8.5.2 项目:企业知识库问答
- 学会把企业文档组织成可检索知识单元
- 学会设计权限和引用这两条企业级关键约束
- 学会用一个最小检索器搭出可展示项目闭环
- 学会围绕错误分析和可追溯性来展示项目
企业知识库项目里有一些词看起来简单,但工程含义很严格:
| 术语 | 新人理解 | 为什么在本项目里重要 |
|---|---|---|
permission filtering | 权限过滤,在检索或回答前先移除当前用户无权查看的文档 | 防止系统泄露内部内容 |
citation | 引用来源,回答后面附带的证据出处 | 让用户能验证答案来自哪里 |
metadata | 元数据,附在 chunk 上的额外字段,比如来源文件、部门、可见范围、页码、版本 | 让过滤、排障和引用变得可做 |
SOP | Standard Operating Procedure,标准作业流程,也就是固定内部流程文档 | 很多企业答案不是单纯事实,而是流程规则 |
traceability | 可追溯性,能把答案追回原始文档和处理链路 | 这是项目可信,而不只是“说得流畅”的关键 |
核心思路是:企业知识库不只是搜索问题,也是权限、证据和审计问题。
一、为什么企业知识库问答比普通 FAQ 更难?
Section titled “一、为什么企业知识库问答比普通 FAQ 更难?”企业知识往往不只是几条问答, 而是:
- 政策文档
- 内部 SOP
- 培训手册
- 产品说明
同一个问题,可能存在:
- 对外版本
- 内部版本
可信度要求更高
Section titled “可信度要求更高”用户常常会追问:
- 这条规则从哪来的?
- 你引用的是哪份文件?
所以企业知识库问答更像:
- 检索系统
- 引用系统
- 权限系统
的组合。

二、先把项目边界定清楚
Section titled “二、先把项目边界定清楚”一个很适合作品集展示的最小范围可以是:
针对课程平台内部帮助中心,做一个“退款 / 发票 / 证书 / 内部客服 SOP”知识库问答系统。
它至少要回答四类问题:
- 对外规则类问题
- 内部流程类问题
- 权限不同导致答案不同的问题
- 需要给出来源的问题
为什么这个范围好?
Section titled “为什么这个范围好?”- 文档主题集中
- 权限边界真实
- 结果好坏容易解释
先设计知识单元,而不是先写模型
Section titled “先设计知识单元,而不是先写模型”下面这个示例会做三件事:
- 把文档切成最小知识单元
- 给每段加元数据
- 区分对外和内部可见范围
kb = [ { "id": "doc_001", "section": "退款政策", "department": "support", "visibility": "public", "text": "课程购买后 7 天内且学习进度低于 20% 可申请退款。", "keywords": {"退款", "7天", "进度", "20%"}, }, { "id": "doc_002", "section": "证书说明", "department": "teaching", "visibility": "public", "text": "完成所有必修项目并通过结课测试后,可以获得结业证书。", "keywords": {"证书", "结课测试", "项目"}, }, { "id": "doc_003", "section": "内部客服 SOP", "department": "internal", "visibility": "internal", "text": "客服处理退款申请时,需要先核验订单号、学习进度和支付渠道。", "keywords": {"退款", "客服", "SOP", "核验", "流程"}, },]
for item in kb: print(f"{item['id']} | {item['visibility']} | {item['section']}")预期输出:
doc_001 | public | 退款政策doc_002 | public | 证书说明doc_003 | internal | 内部客服 SOP为什么这里要加这么多元数据?
Section titled “为什么这里要加这么多元数据?”因为企业知识库检索不只是“内容像不像”, 还要判断:
- 能不能给当前用户看
- 它属于哪个业务域
- 回答时来源怎么展示
这也是企业项目和普通问答演示的根本差异。
先做一个可解释检索器
Section titled “先做一个可解释检索器”为了让示例在当前环境里也能直接跑,我们先不用外部 embedding 库, 而是用一个纯 Python 的关键词重叠检索器,先把项目骨架搭稳。
def retrieve(query, allowed_visibility, top_k=2): candidates = [] query_text = query.lower()
for item in kb: if item["visibility"] not in allowed_visibility: continue score = sum(keyword.lower() in query_text for keyword in item["keywords"]) candidates.append((score, item))
candidates.sort(key=lambda x: x[0], reverse=True) return [item for score, item in candidates[:top_k] if score > 0]
print("public user:")for hit in retrieve("退款规则是什么?", allowed_visibility={"public"}): print(hit["id"], hit["visibility"], hit["section"])
print("\ninternal support:")for hit in retrieve("客服核验流程是什么?", allowed_visibility={"public", "internal"}): print(hit["id"], hit["visibility"], hit["section"])预期输出:
public user:doc_001 public 退款政策
internal support:doc_003 internal 内部客服 SOP这个检索器虽然简单,但为什么很适合教学?
Section titled “这个检索器虽然简单,但为什么很适合教学?”因为它让你清楚看到三件事:
- 查询词怎么影响召回
- 权限怎么影响候选集
- 结果为什么会不同
为什么这里故意不直接用 embedding?
Section titled “为什么这里故意不直接用 embedding?”因为这节课要先把:
- 权限
- 来源
- 结构化知识单元
这些企业级关键点讲清楚。 等骨架清楚后,再换更强检索方式才更稳。
把“回答 + 来源”一起做出来
Section titled “把“回答 + 来源”一起做出来”def answer_with_sources(query, allowed_visibility): hits = retrieve(query, allowed_visibility=allowed_visibility, top_k=2)
if not hits: return { "answer": "当前权限范围内没有找到足够相关的信息。", "sources": [], }
top = hits[0] return { "answer": top["text"], "sources": [ { "id": top["id"], "section": top["section"], "department": top["department"], "visibility": top["visibility"], } ], }
print(answer_with_sources("退款规则是什么?", {"public"}))print(answer_with_sources("客服核验流程是什么?", {"public", "internal"}))预期输出:
{'answer': '课程购买后 7 天内且学习进度低于 20% 可申请退款。', 'sources': [{'id': 'doc_001', 'section': '退款政策', 'department': 'support', 'visibility': 'public'}]}{'answer': '客服处理退款申请时,需要先核验订单号、学习进度和支付渠道。', 'sources': [{'id': 'doc_003', 'section': '内部客服 SOP', 'department': 'internal', 'visibility': 'internal'}]}为什么“来源返回”是作品级项目的亮点?
Section titled “为什么“来源返回”是作品级项目的亮点?”因为它让系统不只是“给你一个答案”, 而是还能回答:
- 这答案从哪来
- 为什么信它
这会显著提高项目可信度。
为什么企业场景比普通问答更需要来源?
Section titled “为什么企业场景比普通问答更需要来源?”因为企业用户经常会真的拿答案去执行流程。 没有来源,就很难建立信任。
项目最该怎么评估?
Section titled “项目最该怎么评估?”不是只看“有没有答出来”
Section titled “不是只看“有没有答出来””企业知识库项目最少要分成三层评估:
- 召回是否相关
- 权限是否正确
- 引用是否可追溯
一个极简评估集
Section titled “一个极简评估集”eval_cases = [ { "query": "退款规则是什么?", "visibility": {"public"}, "expected_doc": "doc_001", }, { "query": "客服核验流程是什么?", "visibility": {"public"}, "expected_doc": None, }, { "query": "客服核验流程是什么?", "visibility": {"public", "internal"}, "expected_doc": "doc_003", },]
for case in eval_cases: result = answer_with_sources(case["query"], case["visibility"]) got = result["sources"][0]["id"] if result["sources"] else None print({ "query": case["query"], "expected_doc": case["expected_doc"], "got": got, "match": got == case["expected_doc"], })预期输出:
{'query': '退款规则是什么?', 'expected_doc': 'doc_001', 'got': 'doc_001', 'match': True}{'query': '客服核验流程是什么?', 'expected_doc': None, 'got': None, 'match': True}{'query': '客服核验流程是什么?', 'expected_doc': 'doc_003', 'got': 'doc_003', 'match': True}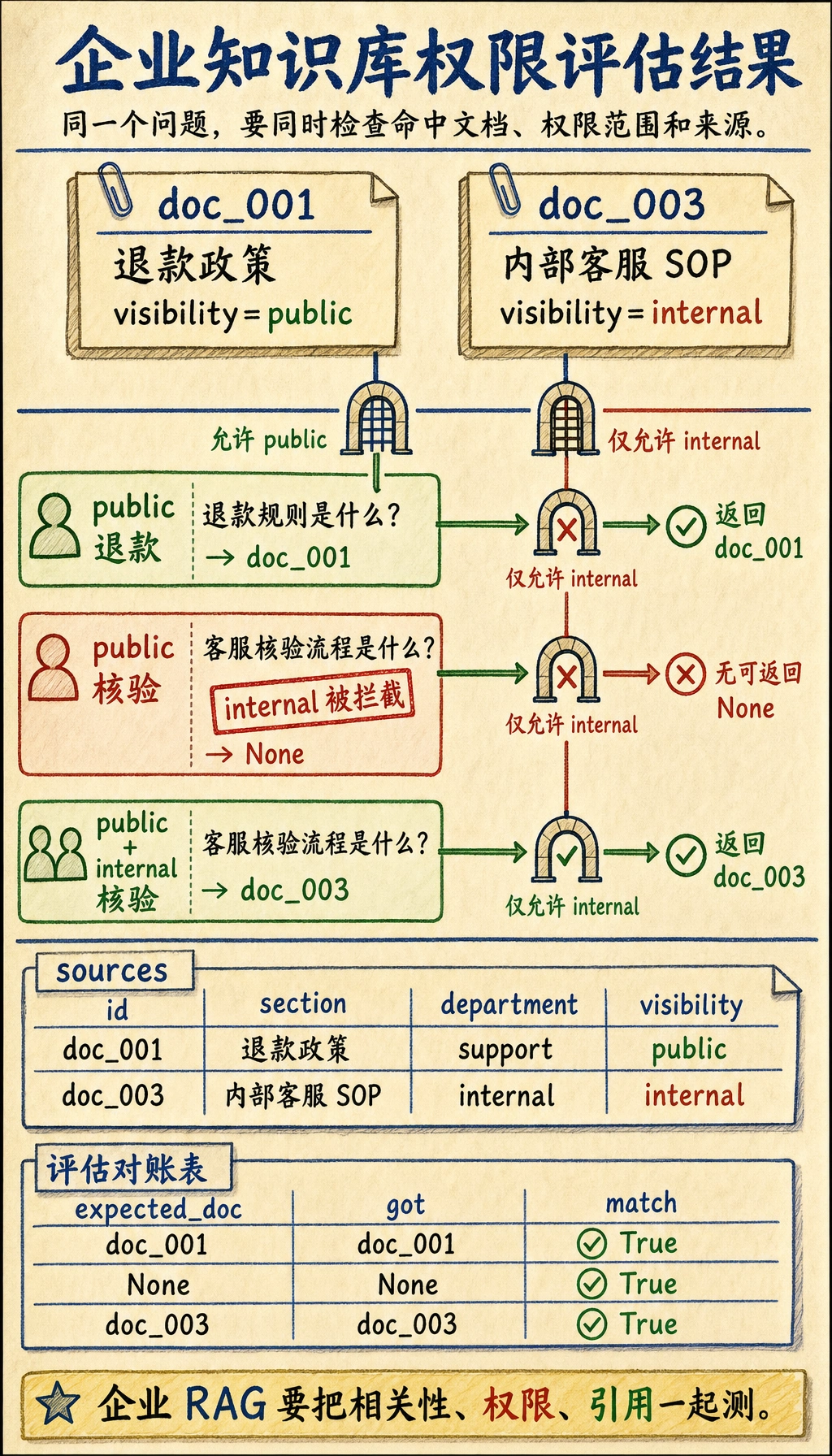
为什么这种评估很值钱?
Section titled “为什么这种评估很值钱?”因为它直接覆盖了企业知识库最关键的两个风险:
- 该答却没答对
- 不该看却看到了内部文档
七、这个项目怎么往作品级再推一步?
Section titled “七、这个项目怎么往作品级再推一步?”把规则检索升级成向量检索
Section titled “把规则检索升级成向量检索”加文档 chunking 和 rerank
Section titled “加文档 chunking 和 rerank”把来源展示做成界面
Section titled “把来源展示做成界面”最推荐展示:
- 用户问题
- 命中文档
- 最终答案
- 来源引用
展示几个“权限相关失败样例”
Section titled “展示几个“权限相关失败样例””这会非常有说服力。
八、最容易踩的坑
Section titled “八、最容易踩的坑”只做“能答”,不做“能追溯”
Section titled “只做“能答”,不做“能追溯””只看语义相关,不看权限边界
Section titled “只看语义相关,不看权限边界”文档单元切得太粗
Section titled “文档单元切得太粗”切太粗时,答案和来源常常都会变得含糊。
学完这一页,至少保留这张证据卡:
- 项目目标
- 用户任务和业务边界
- 基线
- 最简单的提示/RAG/应用版本优先
- 评估
- 固定案例、检索证据、答案质量和引用检查
- 失败日志
- 至少一个失败案例及其可能原因
- 交付物
- README、运行命令、截图/日志、下一步
这节最重要的是建立一个作品级判断:
企业知识库问答真正像项目的地方,不是接了一个检索器,而是能把知识单元、权限边界、回答生成和来源追溯组织成一条可信闭环。
只要这条闭环清楚了,这个项目就会非常像真实企业场景里的系统。
版本路线建议
Section titled “版本路线建议”| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
- 给
kb再加两条“公开文档”和一条“内部文档”,让查询竞争更真实。 - 为什么说企业知识库项目里“权限正确”有时比“答案漂亮”更重要?
- 想一想:如果文档 chunk 切得太粗,会怎么影响回答和引用?
- 如果你把这个项目做成作品集,首页最值得展示哪 4 块信息?
项目交付参考与讲解
- 新文档最好包含相似的 public/internal 主题,这样能同时测试排序质量和权限过滤。
- 泄露内部信息是安全失败,即使答案写得很漂亮也不合格。权限正确是硬要求。
- chunk 太粗会混入无关事实,让引用变模糊,也会让权限和 citation 边界不清楚。
- 首页最值得展示的模块包括问题范围、架构/检索流程、权限模型、评估结果和失败分析。题目要求 4 块时,选最能体现项目判断的四块。