9.2.7 推理评估与优化
- 理解推理系统不能只看最终答案准确率
- 理解过程质量、工具效率和成本为什么也要评估
- 通过可运行示例看懂一组常见推理指标
- 学会围绕评估结果做针对性优化
为什么推理评估比普通 QA 更复杂?
Section titled “为什么推理评估比普通 QA 更复杂?”因为推理系统不只是输出一个文本
Section titled “因为推理系统不只是输出一个文本”一个推理 Agent 往往还会产生:
- 多步 追踪
- 工具调用记录
- 中间状态
- 最终答案
所以它不是单点输出问题, 而是过程型系统问题。
只看最终准确率会漏掉很多信息
Section titled “只看最终准确率会漏掉很多信息”例如两个系统都答对了 80%:
- 系统 A 平均 3 步,几乎不乱调工具
- 系统 B 平均 9 步,经常重复查,成本翻倍
如果只看 accuracy, 你会觉得它们差不多; 但工程上,它们完全不是一个水平。
一个类比:不仅要看是否到达终点,还要看怎么到的
Section titled “一个类比:不仅要看是否到达终点,还要看怎么到的”如果两辆车都到达终点:
- 一辆稳稳开到
- 一辆一路绕路、急刹、险些出事
你不会说它们表现一样。 推理系统也是同理。
推理系统最常看的四类指标
Section titled “推理系统最常看的四类指标”最终结果指标
Section titled “最终结果指标”最常见的是:
- 答案准确率(answer accuracy)
- 精确匹配(exact match)
- 通过率(pass rate)
这回答的是:
- 最终结论对不对
过程质量指标
Section titled “过程质量指标”例如:
- 是否漏关键步骤
- 是否自相矛盾
- 是否有无效循环
这回答的是:
- 过程是否可依赖
工具使用指标
Section titled “工具使用指标”例如:
- 工具成功率
- 重复调用率
- 无必要调用率
这回答的是:
- 工具有没有被合理使用
成本与效率指标
Section titled “成本与效率指标”例如:
- 平均步数
- 平均延迟
- 平均 token 成本
这回答的是:
- 系统值不值得上线
先跑一个真正有用的评估脚本
Section titled “先跑一个真正有用的评估脚本”下面这段代码会比较两个 agent 的 trace 质量。 它会统计:
- 最终答案准确率
- 平均步数
- 工具成功率
- 重复工具调用率
agent_a = [ { "id": "case_1", "expected": "59", "final_answer": "59", "trace": [ {"tool": "calculator", "ok": True}, ], }, { "id": "case_2", "expected": "3-7个工作日", "final_answer": "3-7个工作日", "trace": [ {"tool": "search_policy", "ok": True}, ], },]
agent_b = [ { "id": "case_1", "expected": "59", "final_answer": "59", "trace": [ {"tool": "search_policy", "ok": True}, {"tool": "calculator", "ok": True}, {"tool": "calculator", "ok": True}, ], }, { "id": "case_2", "expected": "3-7个工作日", "final_answer": "5-10个工作日", "trace": [ {"tool": "search_policy", "ok": False}, {"tool": "search_policy", "ok": True}, ], },]
def evaluate_agent(cases): accuracy = sum(case["final_answer"] == case["expected"] for case in cases) / len(cases) avg_steps = sum(len(case["trace"]) for case in cases) / len(cases)
tool_calls = [item for case in cases for item in case["trace"]] tool_success = sum(item["ok"] for item in tool_calls) / len(tool_calls)
repeated_tool_calls = 0 for case in cases: tools = [item["tool"] for item in case["trace"]] repeated_tool_calls += len(tools) - len(set(tools))
repeated_rate = repeated_tool_calls / len(cases)
return { "accuracy": round(accuracy, 3), "avg_steps": round(avg_steps, 3), "tool_success": round(tool_success, 3), "repeated_tool_calls_per_case": round(repeated_rate, 3), }
print("agent_a:", evaluate_agent(agent_a))print("agent_b:", evaluate_agent(agent_b))预期输出:
agent_a: {'accuracy': 1.0, 'avg_steps': 1.0, 'tool_success': 1.0, 'repeated_tool_calls_per_case': 0.0}agent_b: {'accuracy': 0.5, 'avg_steps': 2.5, 'tool_success': 0.8, 'repeated_tool_calls_per_case': 1.0}这段代码最值得带走什么?
Section titled “这段代码最值得带走什么?”最重要的不是某个公式, 而是它展示了一种思路:
同一个系统,至少要同时看答案质量、过程长度和工具表现。
只有三者一起看, 你才知道系统到底是真的稳,还是只是偶然答对。
为什么 agent_b 看起来不一定差很多,但工程上其实更差?
Section titled “为什么 agent_b 看起来不一定差很多,但工程上其实更差?”因为它可能会出现:
- 步数更长
- 重复工具调用更多
- 工具失败后需要补救
即使最终个别 case 答对了, 代价也更高。
为什么重复调用率值得单独看?
Section titled “为什么重复调用率值得单独看?”因为很多 Agent 常见问题不是“完全不会”, 而是:
- 不够果断
- 重复试同一个工具
- 做了很多没必要的动作
这会直接拖慢系统、抬高成本。
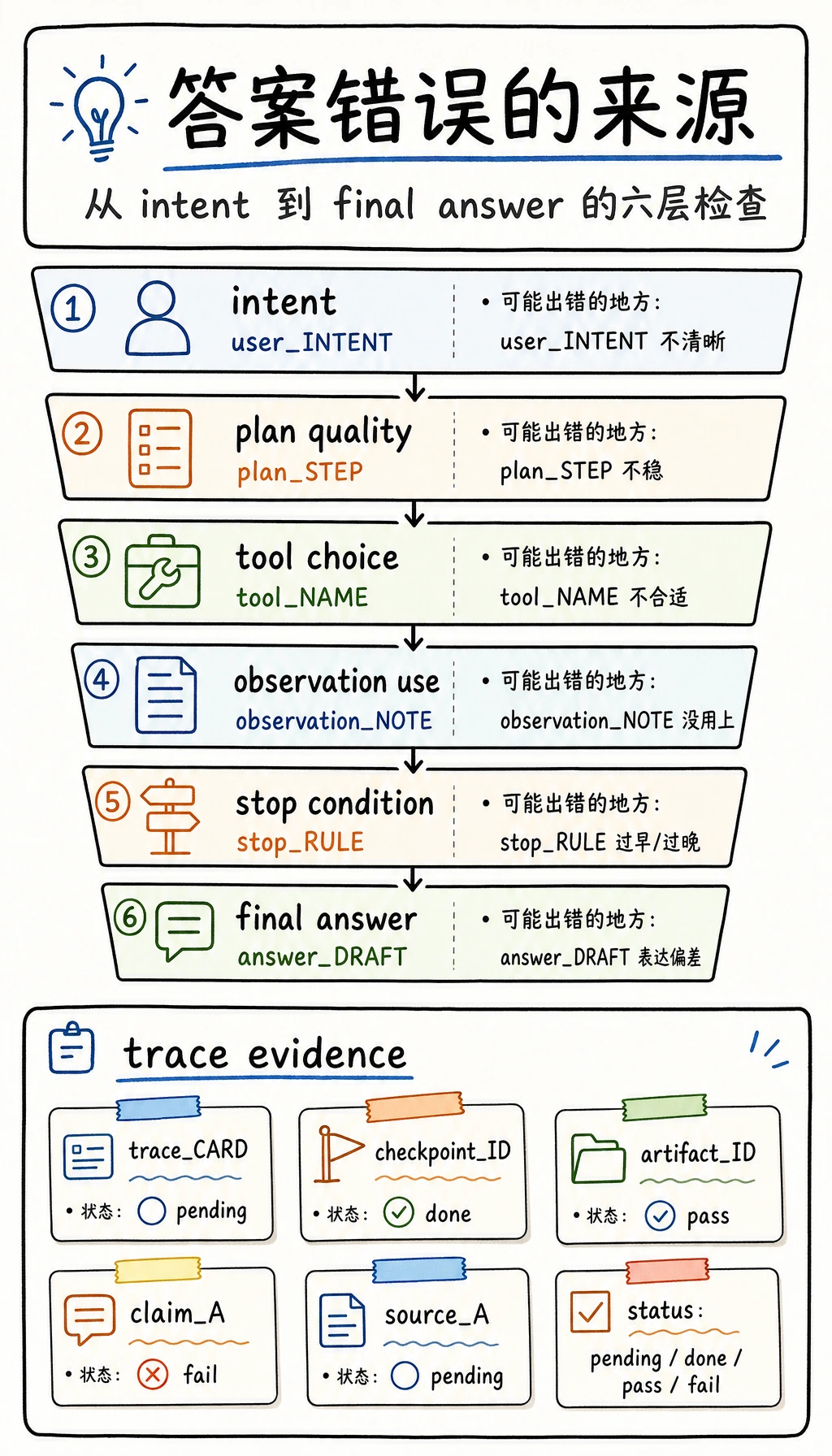
评估时不能只看“有没有答对”
Section titled “评估时不能只看“有没有答对””对答案类任务,看正确率
Section titled “对答案类任务,看正确率”例如:
- 数学题
- 规则问答
- 明确检索题
对过程类任务,看步骤是否合理
Section titled “对过程类任务,看步骤是否合理”例如:
- 是否漏关键步骤
- 是否提前下结论
- 是否先查再算
对 Agent 类任务,看动作是否划算
Section titled “对 Agent 类任务,看动作是否划算”例如:
- 有没有不必要的工具调用
- 有没有工具失败后死循环
- 有没有在够用的信息下及时停止
停止时机本身也是能力的一部分。
拿到评估结果后,该怎么优化?
Section titled “拿到评估结果后,该怎么优化?”如果准确率低
Section titled “如果准确率低”优先看:
- 问题理解是否错
- 工具选择是否错
- observation 整合是否错
如果准确率还行,但步数太长
Section titled “如果准确率还行,但步数太长”优先看:
- 是否重复调用工具
- 是否该提早 stop
- 是否可以合并步骤
如果工具成功率低
Section titled “如果工具成功率低”优先看:
- 结构约束 是否写清楚
- 参数生成是否稳定
- observation 是否足够结构化
如果不同题型表现差异很大
Section titled “如果不同题型表现差异很大”就应该按题型分桶分析。 例如:
- 算术题
- 政策检索题
- 多约束规划题
这样才能做针对性优化。
评估样本该怎么设计?
Section titled “评估样本该怎么设计?”不要只放容易题
Section titled “不要只放容易题”否则系统很容易显得“都挺好”。 你应该刻意加入:
- 容易误判的题
- 需要多步工具配合的题
- 很容易无限循环的题
最好覆盖失败模式
Section titled “最好覆盖失败模式”例如:
- 需要 stop 却不停
- 不该调工具却乱调
- 工具失败后不会恢复
固定评估集要长期保留
Section titled “固定评估集要长期保留”这样每次改 prompt、改策略、改工具后, 你才能进行可比的前后对比。
误区一:最终答案对就说明系统没问题
Section titled “误区一:最终答案对就说明系统没问题”不一定。 它可能只是:
- 过程非常低效
- 成本过高
- 稳定性差
误区二:指标越多越好
Section titled “误区二:指标越多越好”指标不是收集癖。 关键是:
- 指标能不能解释问题
- 指标能不能指导优化
误区三:没有固定基准测试也能靠感觉迭代
Section titled “误区三:没有固定基准测试也能靠感觉迭代”只靠主观感觉, 很容易把系统改得越来越不可控。
学完这一页,至少保留这张证据卡:
- 任务目标
- Agent 想要解决什么
- 计划或轨迹
- 推理步骤、计划、ReAct 轨迹或执行图
- 观察
- 每次操作后发生了什么变化
- 失败检查
- 虚构步骤、过时观察、循环或未经验证的结论
- 评估动作
- 与期望结果对比并修正计划
这节最重要的,不是多记几个指标名, 而是建立一条评估闭环:
推理系统要同时评估最终答案、过程质量、工具使用和成本效率,然后根据具体短板做针对性优化。
当你真正按这条闭环做迭代时, Agent 系统才会从“偶尔能跑”的演示,走向“能解释、能改进、能上线”的系统。
- 给示例中的
agent_b再添加一个 case,看看指标会怎样变化。 - 为什么说“最终答案正确率”不足以完整评估一个推理 Agent?
- 想一想:如果你的系统经常重复调用同一工具,最先会查哪一层?
- 为你的一个 Agent 任务设计一组至少 3 个核心指标,并解释它们为什么有价值。
参考实现与讲解
- 增加一个 case 可能改变 accuracy、tool-use rate、loop count 或失败分布;关键是看哪个指标变化,以及为什么变化。
- 只看最终正确率会漏掉坏 trace:重复工具调用、不安全动作、缺少引用、成本过高,或者只是碰巧答对。
- 优先检查 routing 和停止逻辑,包括工具描述、observation 解析、循环终止条件和 retry policy。
- 有价值的指标包括任务成功率、step count、无效工具调用率、恢复率、延迟与成本、groundedness,以及用户可见错误率。