E.C 经典机器学习路线图
当数据量不大、特征清楚,或者你需要在重模型之前先做强 baseline 时,再回来学这个模块。
先看 baseline 地图
Section titled “先看 baseline 地图”
经典机器学习帮你回答:这个问题是否已经能被简单特征解决。
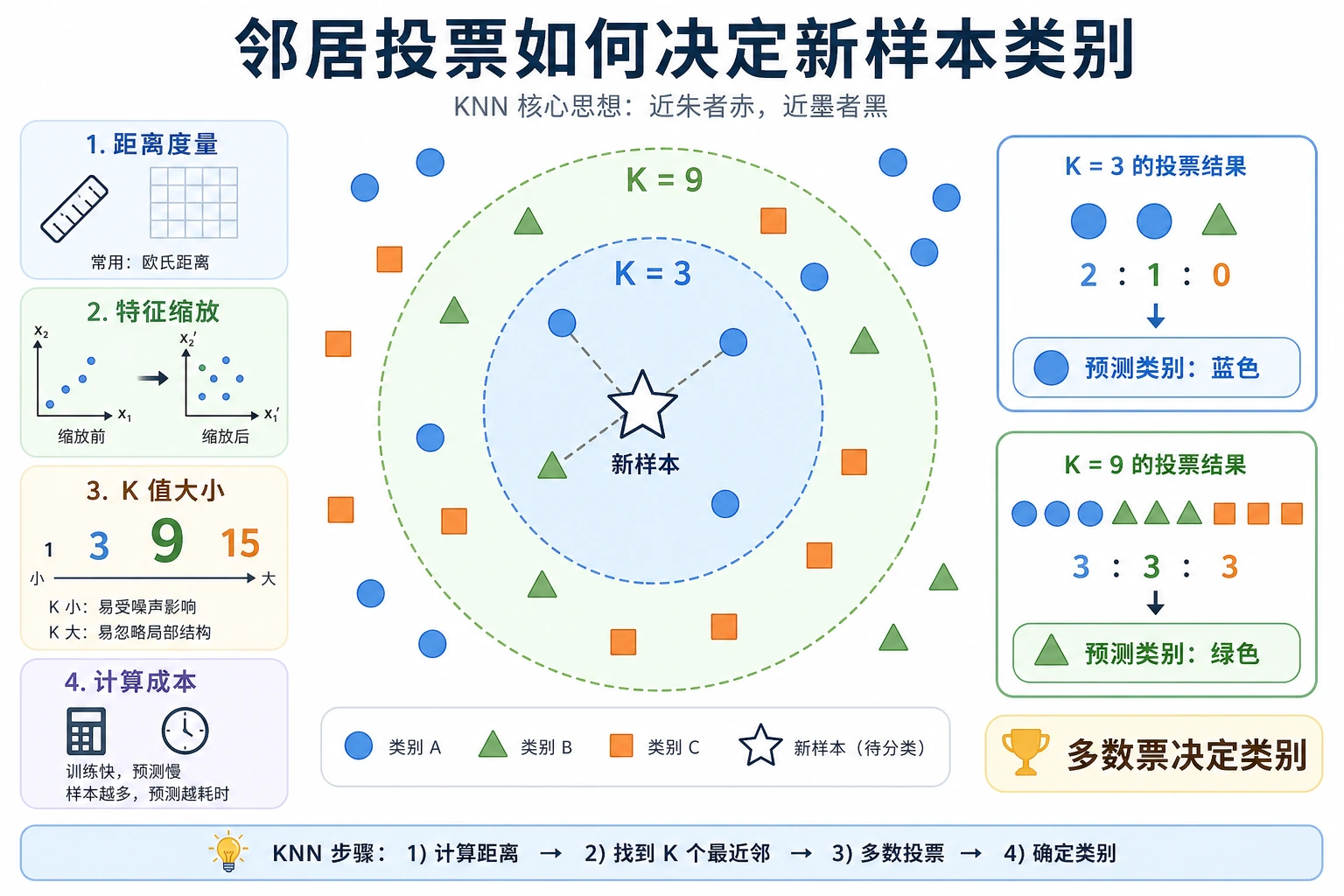
跑最小 KNN baseline
Section titled “跑最小 KNN baseline”def distance(a, b): return sum((x - y) ** 2 for x, y in zip(a, b)) ** 0.5
train = [ ([0.1, 0.2], "low"), ([0.2, 0.1], "low"), ([0.8, 0.9], "high"), ([0.9, 0.8], "high"),]
point = [0.75, 0.85]nearest = min(train, key=lambda row: distance(row[0], point))print("prediction:", nearest[1])print("neighbor:", nearest[0])预期输出:
prediction: highneighbor: [0.8, 0.9]这是最小 baseline 习惯:定义特征,比较距离,预测,并把结果留给后续对比。
如何在真实项目里使用本模块
Section titled “如何在真实项目里使用本模块”把经典机器学习当成 baseline 契约。尝试更大的模型前,先问:干净特征加 SVM、KNN、朴素贝叶斯或 LDA,是否已经能解决大部分任务?如果 baseline 已经很强,更大的模型就必须证明额外成本值得。
比较要具体:同一份训练/测试划分、同一个指标、至少一个失败案例。这样经典 ML 就不是理论绕路,而是防止过度建模的实用护栏。
学习这个模块时,不要把 baseline 当成低级模型。它是成本基线、解释基线和风险基线。只有当新模型在同一指标上明显更好,或者能解决 baseline 的明确失败案例时,复杂度才有理由增加。
最终交付时,至少保留一张对比表:经典 baseline、指标、优点、失败案例、下一步模型。这样你能说明为什么继续升级,而不是因为流行才换更大的模型。
如果经典 baseline 已经达到需求,也要敢于停下。课程项目的目标是做出可靠判断,而不是把模型堆得越来越复杂。能解释“不升级”的理由,也是工程能力。
如果 baseline 失败,也要让失败有价值。写清它在哪类样本上失败、是特征问题还是模型假设问题、下一步为什么值得尝试更复杂的模型。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 课程 | 练习产物 |
|---|---|---|
| 1 | E.C.1 SVM | 解释 margin、support vectors、C 和 kernel 选择 |
| 2 | E.C.2 KNN | 建一个距离投票 baseline |
| 3 | E.C.3 朴素贝叶斯 | 把证据计数转成类别概率 |
| 4 | E.C.4 LDA | 把特征投影到更容易分开类别的方向 |
你能构建一个经典 baseline,解释为什么适合,并和更重的模型或后续项目结果做比较,就算通过本模块。
学完这一页,至少保留这张证据卡:
- 模型家族
- SVM、KNN、朴素贝叶斯、LDA 或其他传统基线
- 数据视图
- 特征缩放、类别平衡、决策边界和训练/测试划分
- 指标
- 准确率/F1、混淆矩阵、边距、邻近行为或投影质量
- 失败检查
- 缩放、高维度、假设薄弱、泄漏或基线拟合差
- 期望产出
- 经典机器学习基线结果,以及一条局限性说明
检查思路与讲解
一个合格答案会先说明为什么这个 baseline 适合:数据小、特征清楚、距离或边界有意义。然后给出一个比较对象,例如更重模型或后续项目结果,并解释限制在哪里。
如果只报一个准确率,信息还不够。经典 ML 的价值是快速、可解释、可对照。