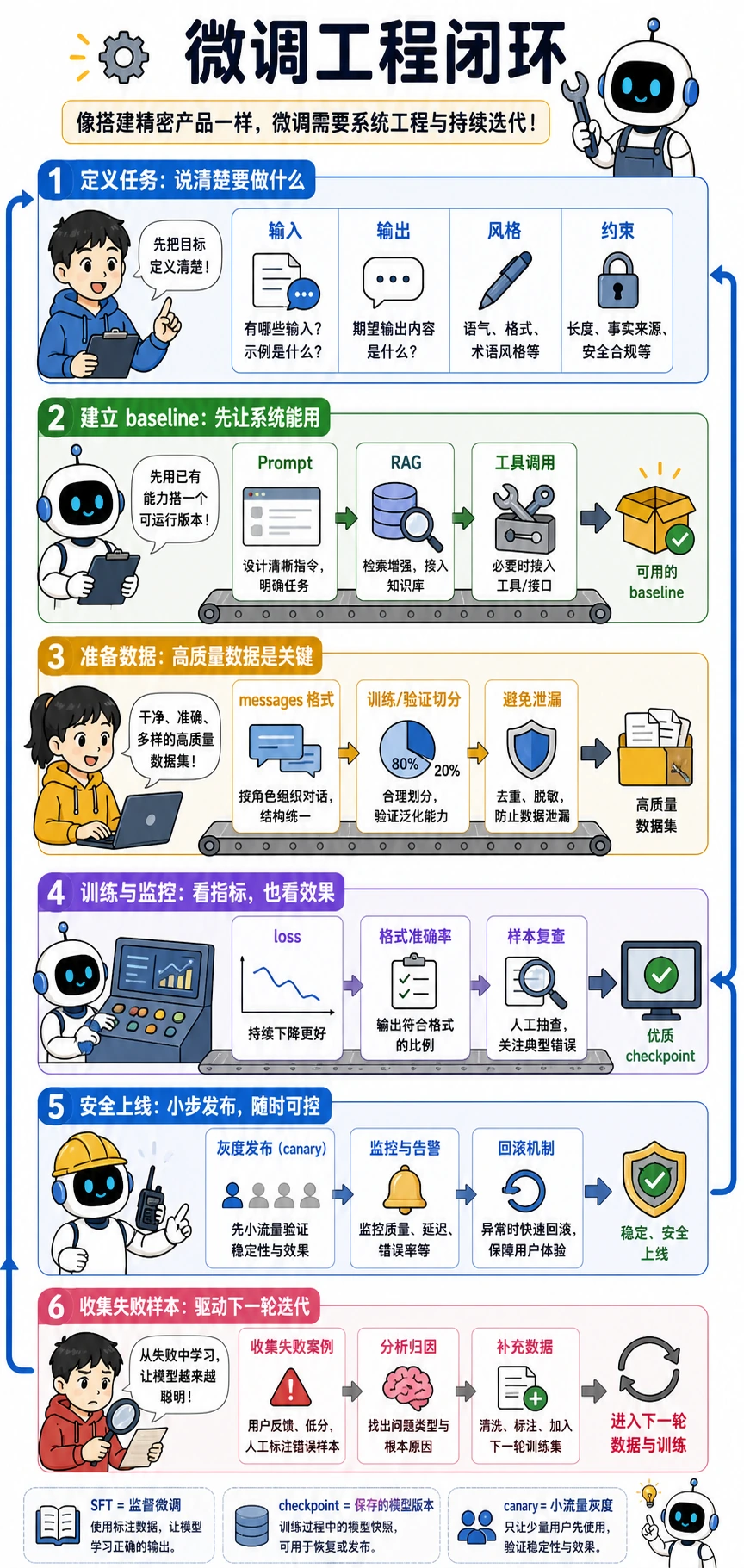
7.6.5 微调工程实践
- 理解微调项目的完整工程顺序
- 学会把原始业务数据整理成训练样本
- 知道如何切分数据、规划 batch、估算训练步数
- 建立“训练前、训练中、训练后分别该看什么”的检查意识
一、微调项目真正的起点不是“开训”
Section titled “一、微调项目真正的起点不是“开训””先把任务写成一句非常具体的话
Section titled “先把任务写成一句非常具体的话”很多团队一开始就说:
- 我们想微调一个客服模型
这句话其实太大了。 更像一个能执行的任务定义应该是:
“给定用户问题和订单上下文,生成一段礼貌、简洁、遵循退款政策的回复。”
你会发现,这里面其实已经隐含了很多关键信息:
- 输入是什么
- 输出是什么
- 风格是什么
- 业务边界是什么
如果这一步含糊,后面所有数据和指标都会跟着飘。
先做基线,再谈微调
Section titled “先做基线,再谈微调”在训练前,你最好先用下面几种方式跑出基线:
- 纯 Prompt
- Prompt + 结构化输出
- RAG
- 工具调用
原因很现实:
- 如果不用微调就能解决,别把系统复杂度白白抬高
- 如果基线已经很强,微调收益可能不大
- 如果基线很差,你反而更容易看出微调到底改善了什么
先决定“训练样本的基本单位”
Section titled “先决定“训练样本的基本单位””常见的训练单位有三种:
- 指令-回答对
- 多轮对话
- 偏好对比样本
这节主要讲监督微调(SFT)工程实践, 因此最常见的单位是:
messagesprompt/completion
别小看这个决定,它会直接影响你后面的数据清洗和模板格式。
动训练脚本前,先理解几个术语
Section titled “动训练脚本前,先理解几个术语”| 术语 | 新人友好的解释 | 在这里为什么重要 |
|---|---|---|
| SFT | Supervised Fine-Tuning,监督微调,用高质量输入输出样本继续训练模型 | 这是本节主要讨论的微调方式 |
messages | 由 system、user、assistant 多个角色组成的聊天样本 | 它更贴近很多对话模型训练和服务时的格式 |
prompt/completion | 更简单的输入 prompt + 目标答案格式 | 适合单轮任务或一些旧数据格式 |
| 验证集 | 不参与训练、专门用来检查效果的保留样本 | 用来估计模型是否真的泛化,而不是只记住训练样本 |
| 数据泄漏 | 相同或同源样本同时出现在训练集和验证集 | 会让验证分数看起来比真实能力更好 |
二、训练前最容易被忽略的三件事
Section titled “二、训练前最容易被忽略的三件事”目标不清,会让数据越标越乱
Section titled “目标不清,会让数据越标越乱”如果你的标注员并不知道:
- 回复是偏简洁还是偏详细
- 是否要主动解释原因
- 碰到越权问题要不要拒答
那你最后得到的数据一定会风格漂移。
数据泄漏会让验证集变得虚假乐观
Section titled “数据泄漏会让验证集变得虚假乐观”一个特别常见的问题是:
- 同一个客户的多条工单
- 同一个 FAQ 的轻微改写版本
- 同一篇文章被切成多个近似片段
如果这些样本同时出现在训练和验证里, 你会误以为模型泛化很好,实际上它只是记住了同源数据。
loss 下降不代表业务可用
Section titled “loss 下降不代表业务可用”对大模型来说,经常会出现这种情况:
- loss 在降
- 但输出风格还是不对
- 或者格式偶尔坏掉
- 或者一长段解释后才给答案
因此你不能只看训练曲线, 还得同时看:
- 结构化格式正确率
- 关键业务字段命中率
- 典型样例的人类阅读结果
三、先把原始业务数据整理成训练样本
Section titled “三、先把原始业务数据整理成训练样本”下面这个例子会做三件特别实用的事:
- 把原始客服记录转成
messages格式 - 按
customer_id分组切分训练集和验证集 - 避免同一客户同时出现在两边
import jsonimport random
random.seed(42)
raw_samples = [ { "customer_id": "C001", "question": "订单已经付款了,能申请退款吗?", "answer": "可以申请退款。请先确认订单状态,如果已经发货,需要走售后流程。", }, { "customer_id": "C001", "question": "退款大概多久到账?", "answer": "原路退款通常需要 3 到 7 个工作日,具体以支付渠道到账时间为准。", }, { "customer_id": "C002", "question": "我忘记密码了,怎么重新登录?", "answer": "请在登录页点击“忘记密码”,按短信或邮箱提示完成重置。", }, { "customer_id": "C003", "question": "收货地址填错了,还能改吗?", "answer": "如果订单还未出库,可以在订单详情页修改地址;若已出库,请联系人工客服。", }, { "customer_id": "C004", "question": "发票什么时候能开?", "answer": "订单完成后可在发票中心申请开具,电子发票会发送到预留邮箱。", },]
def to_chat_record(row): system_prompt = "你是电商客服助手,请给出礼貌、准确、符合平台政策的回复。" return { "customer_id": row["customer_id"], "messages": [ {"role": "system", "content": system_prompt}, {"role": "user", "content": row["question"]}, {"role": "assistant", "content": row["answer"]}, ], }
def split_by_customer(records, train_ratio=0.8): customer_ids = sorted({row["customer_id"] for row in records}) random.shuffle(customer_ids) split_point = max(1, int(len(customer_ids) * train_ratio)) train_ids = set(customer_ids[:split_point])
train_records = [row for row in records if row["customer_id"] in train_ids] val_records = [row for row in records if row["customer_id"] not in train_ids] return train_records, val_records
chat_records = [to_chat_record(row) for row in raw_samples]train_records, val_records = split_by_customer(chat_records)
print("train size =", len(train_records))print("val size =", len(val_records))print("first train example:")print(json.dumps(train_records[0], ensure_ascii=False, indent=2))预期输出:
train size = 3val size = 2first train example:{ "customer_id": "C002", "messages": [ { "role": "system", "content": "你是电商客服助手,请给出礼貌、准确、符合平台政策的回复。" }, { "role": "user", "content": "我忘记密码了,怎么重新登录?" }, { "role": "assistant", "content": "请在登录页点击“忘记密码”,按短信或邮箱提示完成重置。" } ]}这段代码为什么有工程价值?
Section titled “这段代码为什么有工程价值?”因为它对应的是微调里最真实的第一步:
- 原始数据通常不是训练格式
- 你得先整理成模型能吃的结构
- 切分时还要避免同源泄漏
很多项目不是训练方法错, 而是从这一层开始就埋雷了。
为什么要按客户切,而不是直接随机切?
Section titled “为什么要按客户切,而不是直接随机切?”因为随机切分很可能把同一个客户的不同问题同时放进训练和验证。
这样会导致:
- 验证分数看起来很漂亮
- 但其实泛化能力被高估了
所以切分单位通常要尽量贴近真实泛化边界,例如:
- 用户
- 会话
- 文档
- 工单
- 产品线
四、训练格式不只是“长得像对话”
Section titled “四、训练格式不只是“长得像对话””SFT 训练时,通常只希望模型为 assistant 部分负责
Section titled “SFT 训练时,通常只希望模型为 assistant 部分负责”这叫:
- assistant-only loss
意思是:
systemuser
这些内容是条件输入,不该作为训练目标去“背诵”。
下面这个小函数就是一个简化版的 mask 思路:
messages = [ {"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "忘记密码怎么办"}, {"role": "assistant", "content": "请点击忘记密码完成重置"},]
def build_loss_mask(messages): mask = [] for message in messages: token_count = len(message["content"].split()) value = 1 if message["role"] == "assistant" else 0 mask.extend([value] * token_count) return mask
print(build_loss_mask(messages))预期输出:
[0, 0, 1]这不是在复现真实 tokenizer, 而是在帮你理解:
训练时不是所有 token 都要一起算 loss。
在真实 SFT 管道里,tokenizer 会先把 messages 变成 token ID,训练器通常再构造 label mask。system 和 user token 是条件输入,告诉模型当前任务和上下文;assistant token 才是模型要学习的目标行为。assistant-only loss 的作用,就是让模型学习“怎样回答”,而不是把训练信号浪费在背用户问题上。
如果格式规则不稳定,模型会学到“脏模式”
Section titled “如果格式规则不稳定,模型会学到“脏模式””例如同一个任务里:
- 有的样本用
messages - 有的样本用
question/answer - 有的样本 assistant 会先寒暄一大段
- 有的样本直接给答案
这种混乱会让模型难以形成稳定行为。
所以格式统一非常关键:
- 字段统一
- role 顺序统一
- 风格统一
- 结束方式统一
五、训练计划要在开训前就算清楚
Section titled “五、训练计划要在开训前就算清楚”很多人开训时才发现:
- batch 太小
- 步数太少
- warmup 太怪
- checkpoint 存太密或太稀
下面这个脚本可以帮你先算清训练规模。
from math import ceil
def build_training_plan( num_train_examples, micro_batch_size, gradient_accumulation, epochs, num_gpus=1, warmup_ratio=0.03,): effective_batch_size = micro_batch_size * gradient_accumulation * num_gpus steps_per_epoch = ceil(num_train_examples / effective_batch_size) total_steps = steps_per_epoch * epochs warmup_steps = max(1, int(total_steps * warmup_ratio))
return { "effective_batch_size": effective_batch_size, "steps_per_epoch": steps_per_epoch, "total_steps": total_steps, "warmup_steps": warmup_steps, }
plan = build_training_plan( num_train_examples=3200, micro_batch_size=4, gradient_accumulation=8, epochs=3, num_gpus=1,)print(plan)
val_history = [ {"checkpoint": 100, "val_loss": 1.82, "format_acc": 0.61}, {"checkpoint": 200, "val_loss": 1.35, "format_acc": 0.78}, {"checkpoint": 300, "val_loss": 1.31, "format_acc": 0.74},]
best = min(val_history, key=lambda item: (item["val_loss"], -item["format_acc"]))print("best checkpoint =", best)预期输出:
{'effective_batch_size': 32, 'steps_per_epoch': 100, 'total_steps': 300, 'warmup_steps': 9}best checkpoint = {'checkpoint': 300, 'val_loss': 1.31, 'format_acc': 0.74}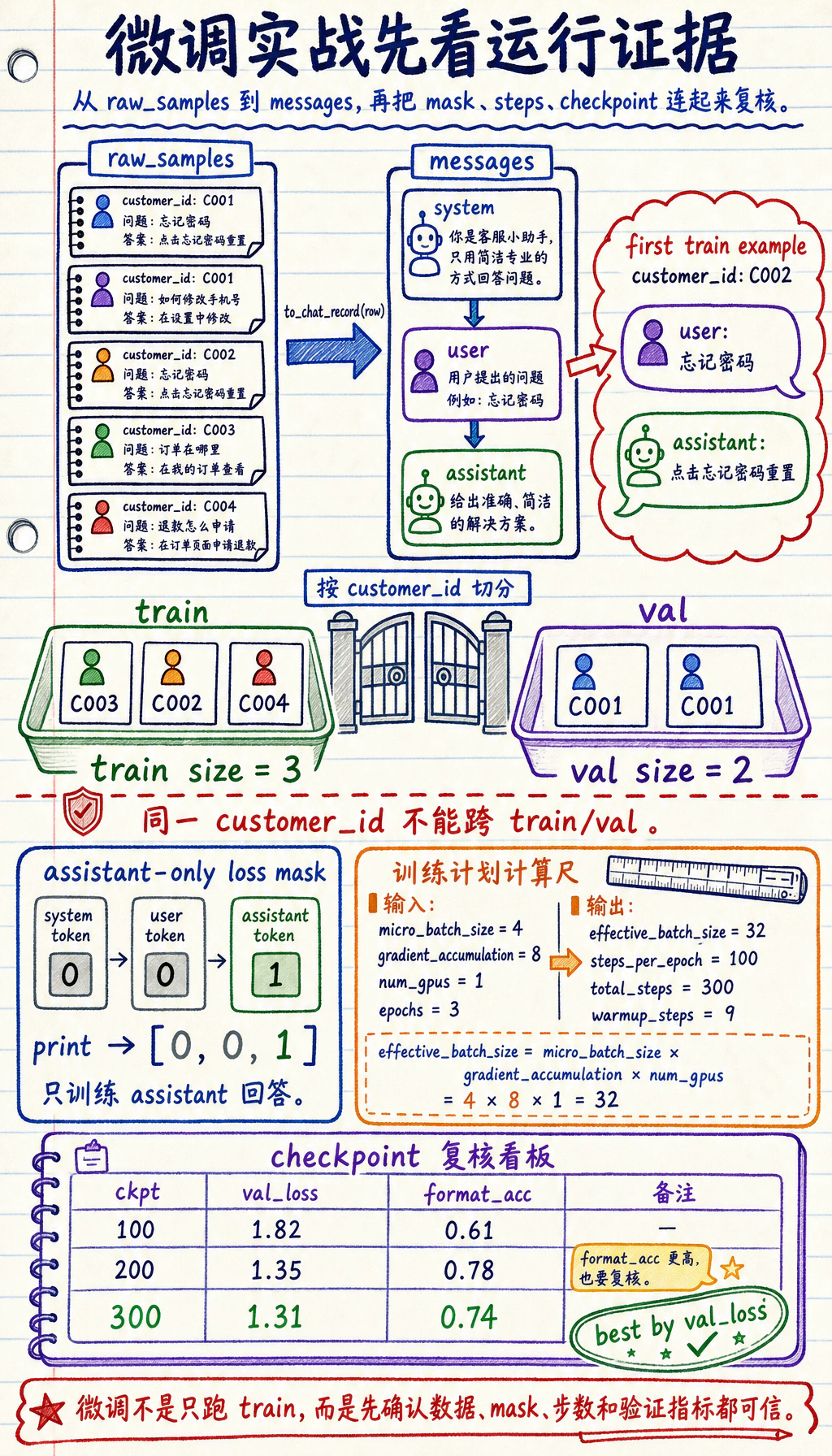
为什么要特别关心 effective batch size?
Section titled “为什么要特别关心 effective batch size?”因为你真正每次参数更新看到的样本数,不只是:
- 单卡 batch size
而是:
micro_batch_size * gradient_accumulation * GPU 数量
这直接影响:
- 梯度稳定性
- 学习率选择
- 总训练步数
为什么验证时不能只看 val_loss?
Section titled “为什么验证时不能只看 val_loss?”因为业务任务常常有更关键的指标,例如:
- JSON 格式正确率
- 分类标签准确率
- 关键信息召回率
- 人工满意度
所以保存最佳 checkpoint 时, 通常至少要同时看:
- 通用训练指标
- 业务指标
容易读错的训练计划术语
Section titled “容易读错的训练计划术语”| 术语 | 含义 | 为什么影响项目 |
|---|---|---|
| 微批大小(Micro batch size) | 单个设备一次小型前向/反向计算处理的样本数 | 主要受 GPU 显存限制 |
| 梯度累积(Gradient accumulation) | 多个 micro batch 的梯度先累积,再做一次优化器更新 | 显存有限时,可以模拟更大的 batch |
| 有效批大小(Effective batch size) | micro_batch_size * gradient_accumulation * GPU 数量 | 会影响学习率选择和梯度稳定性 |
| 预热步数 | 训练初期学习率逐步升高的步数 | 降低训练刚开始时的不稳定 |
| 检查点 | 某个训练步保存下来的模型状态 | 方便比较版本、继续训练或回滚 |
| 灰度流量(Canary traffic) | 先把少量真实流量打到新模型上 | 全量发布前降低上线风险 |
六、训练中到底该盯什么?
Section titled “六、训练中到底该盯什么?”第一层:曲线有没有明显异常
Section titled “第一层:曲线有没有明显异常”例如:
- loss 完全不降
- 一开始就爆炸
- 学习率调度异常
- 验证集突然变差
这些属于“先救火”的问题。
第二层:模型输出有没有跑偏
Section titled “第二层:模型输出有没有跑偏”抽 20 到 50 条固定样例, 每个 checkpoint 都看一遍输出。
重点看:
- 是否过度啰嗦
- 是否开始胡编
- 是否格式不稳定
- 是否遗忘原有基础能力
第三层:有没有过拟合或灾难性遗忘
Section titled “第三层:有没有过拟合或灾难性遗忘”你会经常遇到这种情况:
- 训练集越来越好
- 验证集提升停滞
- 原本会的通用能力反而变差
这通常说明:
- 数据分布太窄
- 训练轮数过多
- 学习率过高
- 样本风格太单一
灾难性遗忘指的是:模型在狭窄微调任务上变好,但丢掉了一些原本会的通用能力。一个简单的检查方式是保留一小组“通用能力检查集”,例如摘要、推理、代码、安全边界样例,并在每个重要 checkpoint 后和任务验证集一起跑。
七、上线前要补的最后一层
Section titled “七、上线前要补的最后一层”离线评估通过,不代表可以直接上线
Section titled “离线评估通过,不代表可以直接上线”真正上线前,至少还要补:
- 灰度流量
- 人工抽检
- 回滚方案
- 版本记录
线上要记的不是只有请求日志
Section titled “线上要记的不是只有请求日志”你还需要关心:
- 哪类问题变好了
- 哪类问题变差了
- 新错误集中在哪些输入类型
这会直接反过来变成你下一轮数据补充的来源。
微调项目不是“一次训练”,而是一条持续迭代链
Section titled “微调项目不是“一次训练”,而是一条持续迭代链”最健康的闭环通常是:
- 明确任务
- 准备数据
- 跑 基线
- 开训与验证
- 灰度上线
- 收集失败样本
- 再进下一轮
八、最常见的误区
Section titled “八、最常见的误区”误区一:一上来先配训练参数
Section titled “误区一:一上来先配训练参数”先配参数,往往是在跳过最关键的任务定义和数据整理。
误区二:数据越多越好
Section titled “误区二:数据越多越好”很多时候更重要的是:
- 数据是否贴任务
- 风格是否一致
- 是否有代表性
误区三:训练一结束就算项目结束
Section titled “误区三:训练一结束就算项目结束”真正的工程实践里, 训练完成通常只是中间节点,不是终点。
学完这一页,至少保留这张证据卡:
- 数据集样本
- 原始记录和格式化训练示例
- 拆分
- 训练/验证/测试或留出规则
- 基线
- 训练前的仅提示输出
- 监控
- 损失、验证分数和失败示例
- 发布检查
- 质量、安全、回滚和 README 说明
这节最重要的不是记住某个配置文件长什么样, 而是建立一条稳定顺序:
先把任务写清楚,再把数据整理对,再把切分和训练计划算明白,最后用业务指标而不只是 loss 去决定版本。
只要这条顺序稳了, 你后面换模型、换框架、换微调方法,工程判断都不会乱。
- 把你手头一个真实业务任务改写成一句更具体的“输入-输出-风格-约束”描述。
- 参考本节代码,把一份原始问答数据整理成
messages格式。 - 想一想:你的数据更应该按用户、按会话,还是按文档切分?为什么?
- 如果验证集
val_loss更低,但 JSON 格式正确率更差,你会选哪个 checkpoint?为什么?
解题思路与讲解
- 好的任务描述要写清输入字段、期望输出形状、风格或语气、禁止行为和通过/失败约束。像“回答更好”这种目标太含糊,不足以支撑可靠微调。
- 好的
messages数据集会区分system、user、assistant角色,移除重复或互相矛盾的样本,并把敏感或低质量内容排除在训练外。 - 切分方式要优先防止泄漏。用户个性强就按用户切;有连续对话依赖就按会话切;文档问答则按文档切,避免同一来源同时进入训练集和验证集。
- 应选择最符合部署要求的 checkpoint。如果 JSON 正确率是硬约束,那么
val_loss稍高但格式合规明显更好的 checkpoint 通常更安全。