7.3.2 Transformer 架构回顾与深入
- 理解 Transformer block 内部每个模块分别负责什么
- 理解 token embedding、位置信息、自注意力、FFN 是怎样串联的
- 通过一个可运行的最小 block 示例建立“数据是怎么流动的”直觉
- 理解为什么残差连接和归一化对深层网络很重要
一、为什么 Transformer 会成为大模型的底座?
Section titled “一、为什么 Transformer 会成为大模型的底座?”它解决的是“序列里谁该看谁”的问题
Section titled “它解决的是“序列里谁该看谁”的问题”语言天然是序列。 当模型处理一句话时,它需要知道:
- 当前词和前面哪些词有关
- 哪些位置更重要
- 长距离依赖该怎么保留
RNN 的思路是顺序读, CNN 的思路是局部卷积, Transformer 的思路则是:
让每个位置都主动去“看”其他位置,并为它们分配权重。
这就是自注意力的核心。
Transformer 真正强的地方不只是注意力
Section titled “Transformer 真正强的地方不只是注意力”很多人会把 Transformer 简化成:
- 有 attention 的网络
但真正让它适合大规模训练的,其实是一整套配合:
- token embedding
- 位置表示
- 多头自注意力
- 残差连接
- LayerNorm
- 前馈网络
- 可堆叠的 block 结构
这套组合让它既能建模序列关系,又能做深、做大、做并行。
一个类比:每层 block 都像一次“讨论 + 整理”
Section titled “一个类比:每层 block 都像一次“讨论 + 整理””你可以把一个 Transformer block 想成开会:
- 自注意力像“每个 token 去听别的 token 在说什么”
- 前馈网络像“每个 token 在吸收完上下文后,再单独做一轮内部加工”
- 残差连接像“保留原始发言,不要被新一轮加工完全覆盖”
一个 block 处理一轮, 多层 block 叠起来,就像一群人反复讨论和整理信息。
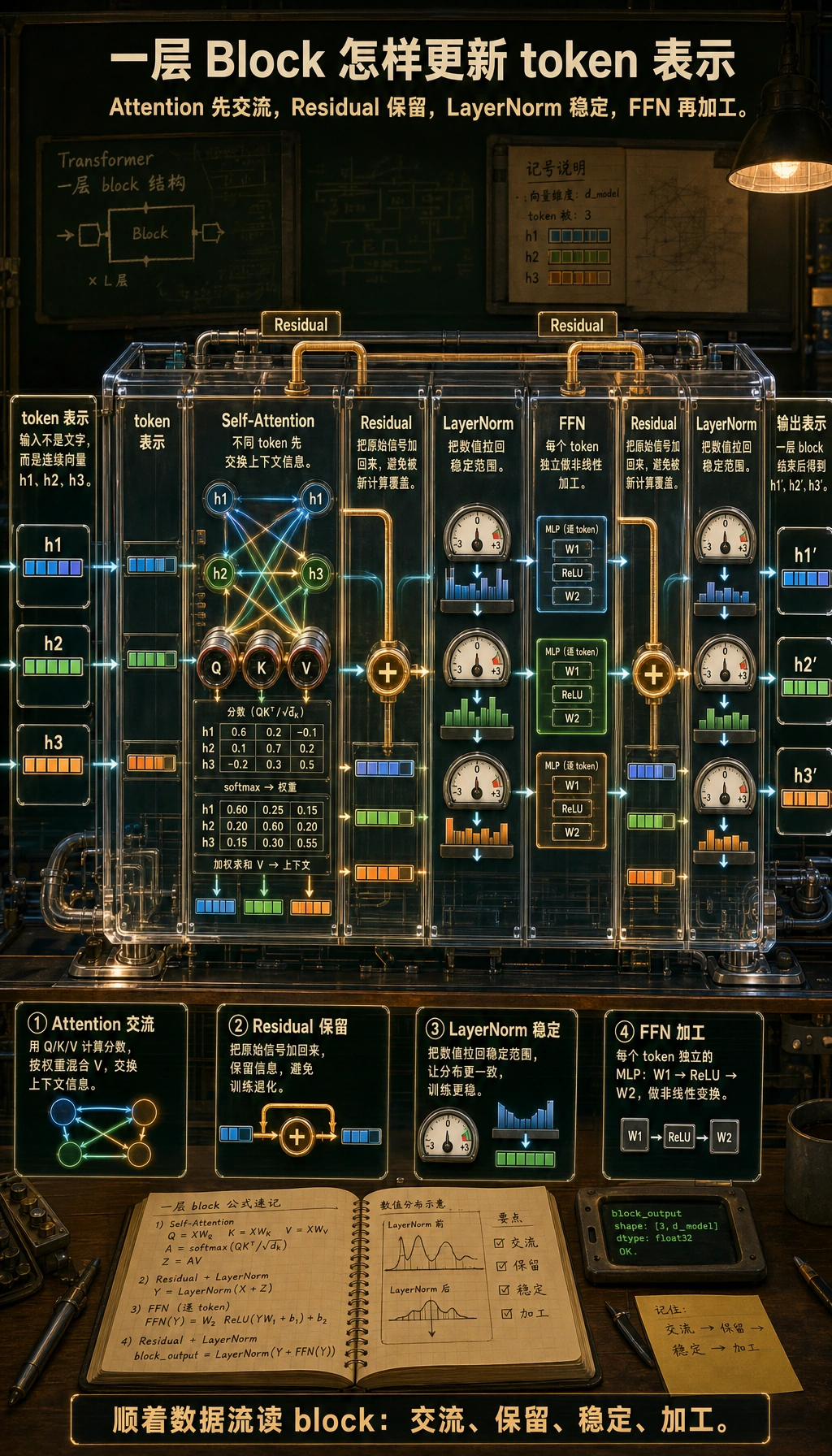
二、一个 Transformer block 里到底有什么?
Section titled “二、一个 Transformer block 里到底有什么?”输入先变成向量
Section titled “输入先变成向量”模型看到的不是文字本身,而是 token id。 这些 token id 会先查 embedding 表,变成向量。
例如:
我->[0.2, -0.1, 0.8, ...]喜欢->[0.7, 0.3, -0.2, ...]
这一步做的是:
把离散符号变成连续空间里的表示。
然后补上位置信息
Section titled “然后补上位置信息”注意力本身只关心“集合里的关系”, 它并不知道 token 原本处在第几个位置。
所以我们必须告诉模型:
- 第 1 个 token
- 第 2 个 token
- 第 3 个 token
这些位置信息可以通过:
- 正弦位置编码
- 可学习位置向量
- RoPE 等相对位置方法
注入进去。
自注意力负责“跨 token 交流”
Section titled “自注意力负责“跨 token 交流””自注意力里每个 token 都会生成三份表示:
- 查询:我想找什么
- Key:我能提供什么
- Value:如果你关注我,你最终拿到什么
然后每个 token 会做两步:
- 用自己的
Query和其他 token 的Key算相似度 - 用这些相似度去加权别人的
Value
得到的结果就是:
- “结合了上下文后的新表示”
前馈网络负责“单 token 深加工”
Section titled “前馈网络负责“单 token 深加工””很多新人学 Transformer 时,会把注意力看成唯一核心。 但实际上,FFN 也非常重要。
它的特点是:
- 每个 token 单独经过一小段 MLP
- 不做跨 token 交流
- 但会增强非线性表达能力
可以把它理解成:
注意力负责交换信息,FFN 负责消化信息。
残差和归一化为什么总出现?
Section titled “残差和归一化为什么总出现?”因为深层网络很容易训练不稳。 残差连接和 LayerNorm 的作用,可以先粗略记成:
- 残差:保留旧信息,让新信息是“增量更新”
- LayerNorm:把每层输出拉回更稳定的数值范围
如果没有它们, 深层 Transformer 很容易训练困难。
三、先跑一个真正的最小 Transformer block
Section titled “三、先跑一个真正的最小 Transformer block”下面这段代码会用纯 Python 做一件事:
- 输入三个 token 向量
- 计算一个单头自注意力
- 做残差连接
- 再经过一个小前馈网络
它不是完整工业实现,但每一步都对应真实 block 的核心结构。
from math import exp, sqrt
tokens = [ [1.0, 0.0, 1.0], [0.0, 1.0, 1.0], [1.0, 1.0, 0.0],]
W_q = [ [1.0, 0.0], [0.5, 1.0], [0.0, 1.0],]W_k = [ [1.0, 0.5], [0.0, 1.0], [1.0, 0.0],]W_v = [ [1.0, 0.0, 0.5], [0.0, 1.0, 0.5],]W1 = [ [1.0, -0.5], [0.5, 1.0], [1.0, 0.5],]W2 = [ [0.5, 1.0, 0.0], [1.0, 0.0, 0.5],]
def matmul_vec(vec, matrix): return [ sum(vec[i] * matrix[i][j] for i in range(len(vec))) for j in range(len(matrix[0])) ]
def dot(a, b): return sum(x * y for x, y in zip(a, b))
def softmax(values): m = max(values) exps = [exp(v - m) for v in values] total = sum(exps) return [x / total for x in exps]
def add(a, b): return [x + y for x, y in zip(a, b)]
def relu(vec): return [max(0.0, x) for x in vec]
Q = [matmul_vec(token, W_q) for token in tokens]K = [matmul_vec(token, W_k) for token in tokens]V_in = [[1.0, 0.0], [0.0, 1.0], [1.0, 1.0]]V = [matmul_vec(v, W_v) for v in V_in]
scale = sqrt(len(Q[0]))scores = []for i, q in enumerate(Q): row = [] for j, k in enumerate(K): row.append(dot(q, k) / scale if j <= i else -10**9) scores.append(row)
weights = [softmax(row) for row in scores]
contexts = []for row in weights: context = [0.0, 0.0, 0.0] for w, v in zip(row, V): context = [c + w * x for c, x in zip(context, v)] contexts.append(context)
after_attention = [add(token, context) for token, context in zip(tokens, contexts)]ffn_hidden = [relu(matmul_vec(vec, W1)) for vec in after_attention]ffn_output = [matmul_vec(vec, W2) for vec in ffn_hidden]block_output = [add(x, y) for x, y in zip(after_attention, ffn_output)]
print("attention weights:")for row in weights: print([round(x, 3) for x in row])
print("\nblock output:")for row in block_output: print([round(x, 3) for x in row])预期输出:
attention weights:[1.0, 0.0, 0.0][0.413, 0.587, 0.0][0.456, 0.225, 0.32]
block output:[3.75, 3.5, 1.5][3.897, 4.294, 2.566][4.366, 4.752, 1.153]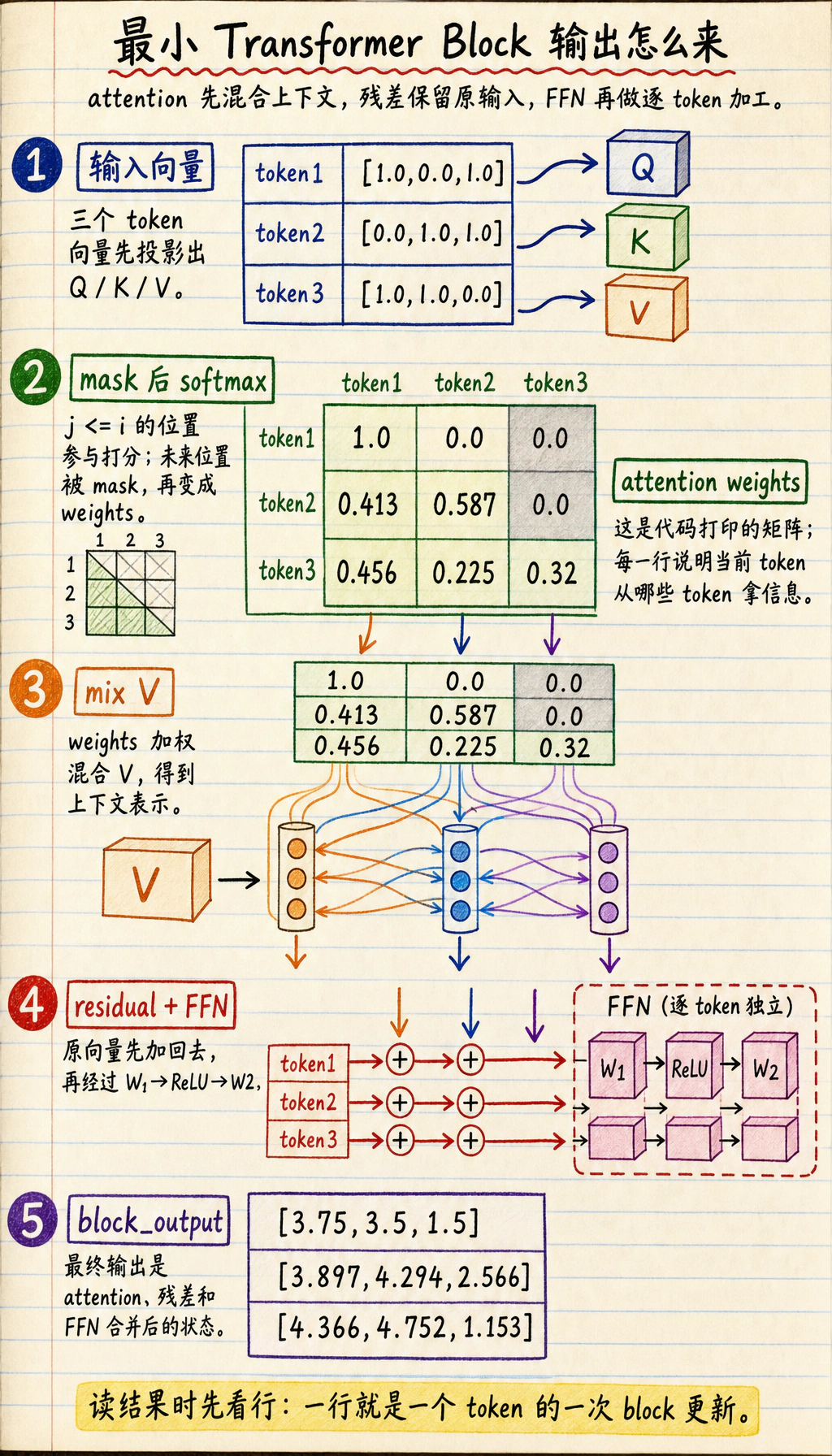
读这段代码时,先盯住四个位置
Section titled “读这段代码时,先盯住四个位置”最关键的地方只有四处:
Q / K / V的生成scores的计算softmax后的加权求和- 残差 + FFN
如果这四处看懂了, 你对 Transformer block 的理解就已经越过“只会背图”的阶段了。
为什么这里要加 causal mask?
Section titled “为什么这里要加 causal mask?”你会看到这句:
row.append(dot(q, k) / scale if j <= i else -10**9)它表示:
- 当前 token 只能看自己和前面的 token
- 不能偷看未来
这正是 GPT 这类 decoder-only 模型训练时的关键约束。
如果你把 j <= i 去掉,
它就更像 encoder 里的双向注意力。
为什么注意力后面还要再过 FFN?
Section titled “为什么注意力后面还要再过 FFN?”因为注意力只是在“汇总上下文”。 它告诉当前 token:
- 我该关注谁
但它不擅长做充分的非线性变换。 FFN 的作用就是:
- 把上下文融合后的表示再加工一轮
所以二者分工不同,缺一不可。
四、把 block 放回整张结构图里
Section titled “四、把 block 放回整张结构图里”多层堆叠意味着逐层抽象
Section titled “多层堆叠意味着逐层抽象”第一层注意力看到的可能更多是:
- 词法关系
- 邻近模式
更高层可能逐渐形成:
- 句法关系
- 语义角色
- 长距离依赖
- 任务相关特征
这也是为什么 Transformer 不只是“一层 attention”, 而是很多层 block 叠起来。
编码器和解码器的差别主要在 mask 和交互方式
Section titled “编码器和解码器的差别主要在 mask 和交互方式”如果只看 block,本质上它们很像。 差别主要在:
- 编码器:通常是双向自注意力
- 解码器:通常是因果 mask
- 编码器-解码器:解码器里还会多一层 cross-attention
所以很多架构差异,最后都能追溯到:
- 谁能看谁
GPT 为什么只保留解码器?
Section titled “GPT 为什么只保留解码器?”因为生成任务最核心的结构约束是:
- 只能根据过去预测未来
decoder-only 更贴这个目标,结构也更直接。 这就是后来 GPT 系列一路做大的原因之一。
五、工程上最容易忽略的点
Section titled “五、工程上最容易忽略的点”注意力不是免费午餐
Section titled “注意力不是免费午餐”每个 token 都要和其他 token 比较, 长度一长,成本会迅速上升。
这也是后面为什么会出现:
- 高效注意力
- KV cache
- GQA / MQA
- FlashAttention
这些改造。
block 结构看起来重复,但训练时并不轻松
Section titled “block 结构看起来重复,但训练时并不轻松”当层数和 hidden size 提高后,你很快就会碰到:
- 显存压力
- 梯度稳定性
- 吞吐与延迟权衡
所以 Transformer 真正能成为大模型底座,不只是因为“结构优雅”, 也因为大量工程细节逐步成熟了。
看懂 block,后面很多章节都会轻松很多
Section titled “看懂 block,后面很多章节都会轻松很多”后面你学:
- 架构变体
- 高效注意力
- 预训练方法
- 微调
本质上都在围绕这个 block 做改造或利用。
六、常见误区
Section titled “六、常见误区”误区一:Transformer = 注意力
Section titled “误区一:Transformer = 注意力”不完整。 Transformer 是一套 block 设计,不是一个孤立公式。
误区二:FFN 只是配角
Section titled “误区二:FFN 只是配角”错。 它承担的是非常重要的非线性特征变换。
误区三:只要知道 QKV 就算理解了 Transformer
Section titled “误区三:只要知道 QKV 就算理解了 Transformer”真正理解还包括:
- 残差为什么重要
- mask 为什么决定行为
- 多层堆叠为什么能形成抽象
学完这一页,至少保留这张证据卡:
- 输入约束
- token embeddings plus position information
- 注意力作用
- 在不同位置之间混合信息
- FFN 作用
- 对每个位置独立进行变换
- 稳定性部分
- 残差加归一化
- 输出桥接
- 隐藏状态变成词表 logits
这节最重要的不是再记一遍结构图, 而是把一个 Transformer block 的数据流串起来:
token 向量先通过注意力和上下文交流,再经过前馈网络深加工,并依靠残差和归一化在多层堆叠中保持训练稳定。
只要这一条链在脑子里顺了, 后面很多“大模型看起来很复杂”的结构,其实都只是围绕这个 block 在做变化。
- 把示例里的
j <= i改成始终允许,观察注意力权重会怎么变。 - 试着去掉残差连接,看看
block_output和原始输入的关系还稳不稳。 - 用自己的话解释:为什么说注意力负责交流信息,FFN 负责消化信息?
- 想一想:如果要把这个 block 叠 48 层,你最担心的工程问题会是什么?
参考实现与讲解
- 始终允许 attention 后,每个位置都能看到后面的 token。注意力矩阵会不再保持明显的三角形结构,这有助于观察机制,但会破坏 decoder-only 生成时必须遵守的自回归规则。
- 去掉残差连接后,block 更难保留原始信号。层数很深时,每一层都要同时学习变换和身份传递,训练会更脆弱。
- Attention 在不同 token 位置之间混合信息;FFN 则对每个位置的混合表示做非线性处理,所以更像是在“消化”当前位置已经汇集到的信息。
- 最需要担心的通常是训练稳定性、显存压力、梯度流和吞吐量。LayerNorm 位置、残差路径、激活保存和 checkpointing 都会变成真实工程问题,而不只是结构细节。