11.1.2 NLP 概述
完成本节后,你将能够:
- 说清楚 NLP 在解决什么问题
- 了解 NLP 里最常见的几类任务
- 理解一条最基础的 NLP 流程
- 明白为什么文本处理往往比表格和图像更“拧巴”
- 通过最小示例建立“文本 -> 结构化结果”的直觉
一、NLP 到底在做什么?
Section titled “一、NLP 到底在做什么?”NLP 是 Natural Language Processing,自然语言处理。
说得更直白一点:
NLP 就是让计算机处理人类语言。
这里的“语言”包括很多形式:
- 聊天消息
- 评论
- 新闻
- 合同
- 工单
- 邮件
- 搜索词
- 会议纪要
它最终想解决的,不只是“识别文字”,而是更进一步:
- 理解意思
- 提取信息
- 生成回答
- 完成任务
二、NLP 里最常见的任务有哪些?
Section titled “二、NLP 里最常见的任务有哪些?”你可以先把 NLP 任务分成四大类来看:
输入一段文本,输出一个整体结果。
例如:
- 文本分类 “这是退款问题还是发票问题?”
- 情感分析 “这条评论是正面还是负面?”
输入一段文本,输出其中某些关键片段。
例如:
- 命名实体识别
从 “张三在北京工作” 中抽出
张三和北京 - 信息抽取 从公告里抽出时间、地点、人物
文本到文本类
Section titled “文本到文本类”输入一段文本,输出另一段文本。
例如:
- 机器翻译
- 文本摘要
- 改写
- 问答生成
交互式与系统类
Section titled “交互式与系统类”输入不一定只是单轮文本,可能还包括状态、历史和工具结果。
例如:
- 聊天机器人
- RAG 问答系统
- Agent
这类任务会把前面几种能力组合起来。
三、为什么文本处理通常比表格数据更难?
Section titled “三、为什么文本处理通常比表格数据更难?”一句话可能有多种解释。
例如:
“这个手机不便宜,但拍照是真的能打。”
如果只看 “不便宜”,很容易误判成负面; 但整句其实更偏正向评价。
文本强依赖上下文
Section titled “文本强依赖上下文”很多词单独看并不重要,放进上下文后才有具体意思。
例如:
bank既可能是银行,也可能是河岸
文本表达不统一
Section titled “文本表达不统一”用户描述同一个意思,可能有很多写法。
例如:
- “怎么退钱”
- “退款怎么弄”
- “这单还能退吗”
这些文本词面差异很大,但意图接近。
文本天然非结构化
Section titled “文本天然非结构化”表格数据往往有明确列含义:
- 年龄
- 收入
- 城市
但文本通常是人随手写的自由表达。 模型必须先把它变成可计算结构。
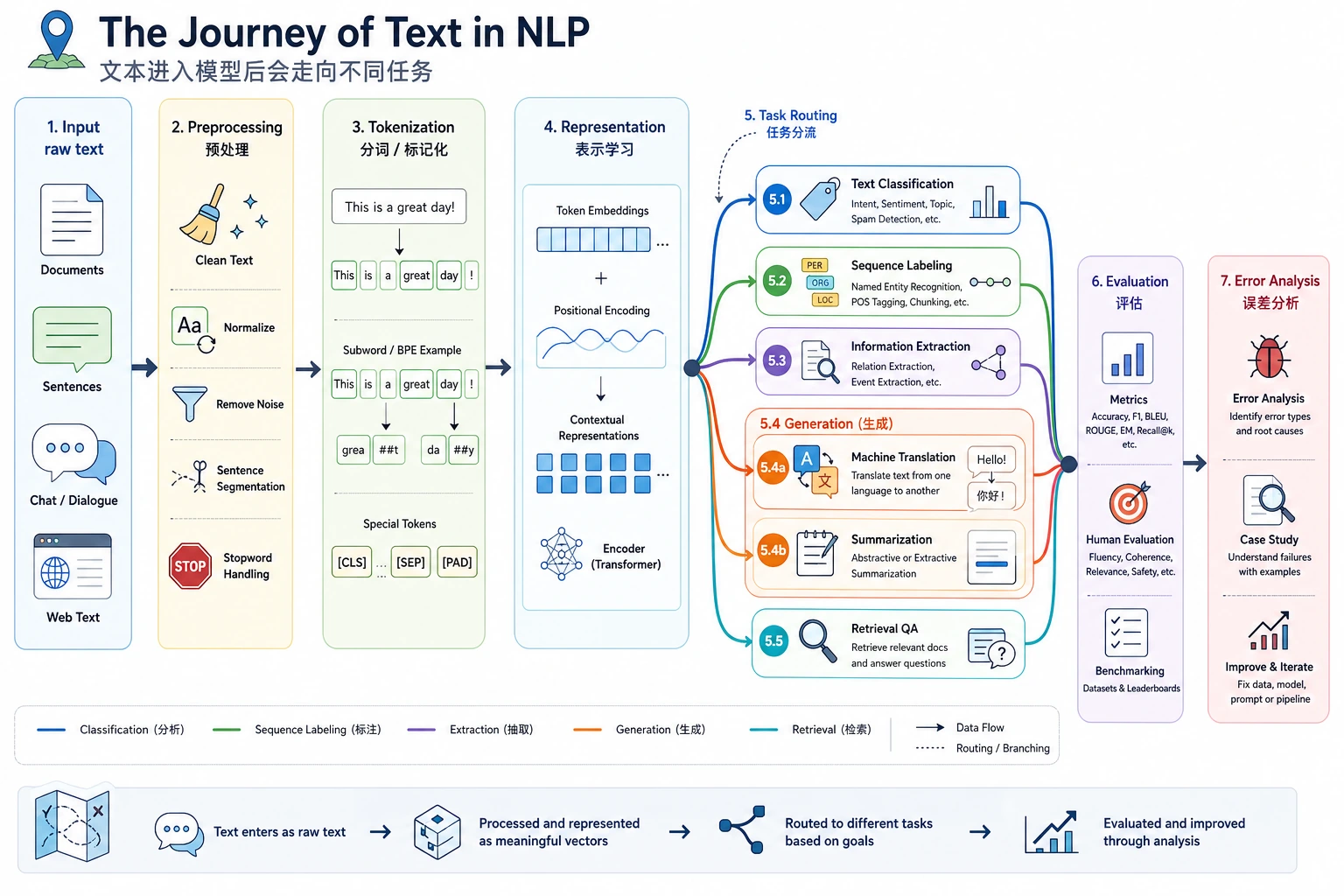
四、NLP 的典型处理流程长什么样?
Section titled “四、NLP 的典型处理流程长什么样?”最基础的一条线可以先理解成:
flowchart LR A["原始文本"] --> B["预处理"] B --> C["文本表示"] C --> D["模型"] D --> E["结果 / 结构化输出"]这条线的每一段都很重要:
- 预处理 把脏文本整理得更适合当前任务
- 文本表示 把文字变成数字
- 模型 学习输入和目标之间的关系
- 输出 变成标签、答案、摘要或实体片段
后面 11 自然语言处理(方向选修)的大部分课程,其实都在围绕这条线往下展开。
五、先跑一个最小 NLP 示例
Section titled “五、先跑一个最小 NLP 示例”下面这个例子非常简单,但它已经完整体现了 NLP 的核心流程:
- 输入是文本
- 做一点最小预处理
- 用规则识别意图
- 输出结构化结果
import re
texts = [ "帮我查一下今天北京天气", "请帮我订一张去上海的机票", "计算一下 25 乘以 4 是多少", "明天深圳会下雨吗",]
def classify_intent(text): text = re.sub(r"\s+", "", text)
if "天气" in text or "下雨" in text: return "weather_query" if "机票" in text or "订票" in text: return "ticket_booking" if "计算" in text or "乘以" in text: return "calculation" return "unknown"
for text in texts: print(text, "->", classify_intent(text))预期输出:
帮我查一下今天北京天气 -> weather_query请帮我订一张去上海的机票 -> ticket_booking计算一下 25 乘以 4 是多少 -> calculation明天深圳会下雨吗 -> weather_query输出是结构化的:每句自由表达都被转换成一个任务标签。后面的模型可以更强,但项目仍然需要先有清晰的输出边界。
这个例子真正想让你抓住什么?
Section titled “这个例子真正想让你抓住什么?”它说明 NLP 的最小闭环其实很朴素:
- 输入是自然语言
- 系统从里面识别模式
- 最后输出结构化结果
哪怕这里只用了规则,也已经是一个最基础的 NLP 系统。
六、NLP 的三条主要发展路线
Section titled “六、NLP 的三条主要发展路线”靠人工规则写逻辑。
优点:
- 可解释
- 小任务起步快
缺点:
- 难维护
- 泛化差
传统机器学习
Section titled “传统机器学习”先做特征,再训练分类器。
例如:
- BoW
- TF-IDF
- SVM
- 逻辑回归
深度学习与预训练模型
Section titled “深度学习与预训练模型”让模型直接学习表示和上下文关系。
例如:
- RNN / LSTM
- Transformer
- BERT
- GPT
所以你后面学的很多内容,本质上都在回答同一个问题:
怎样让机器越来越稳定地处理人类语言?
七、为什么 NLP 会和大模型、RAG、Agent 强相关?
Section titled “七、为什么 NLP 会和大模型、RAG、Agent 强相关?”因为大语言模型本质上仍然是在处理文本。 如果你不了解这些基础概念:
- token
- 语义表示
- 上下文
- 分类
- 抽取
- 生成
那后面学 LLM、RAG、Agent 时就很容易只停留在:
- 会调 API
而不是:
- 真正理解它们在做什么
所以 11 自然语言处理(方向选修)不是绕路,而是在铺后面的底。
八、初学者最常见的误区
Section titled “八、初学者最常见的误区”以为 NLP 就等于聊天机器人
Section titled “以为 NLP 就等于聊天机器人”聊天只是 NLP 的一个应用场景,不是全部。
以为预处理只是细枝末节
Section titled “以为预处理只是细枝末节”很多任务里,预处理质量会直接影响结果上限。
以为只有深度学习才算 NLP
Section titled “以为只有深度学习才算 NLP”规则系统和传统机器学习在很多中小任务里依然很有价值。
以为文本“看懂了”就等于机器也能直接处理
Section titled “以为文本“看懂了”就等于机器也能直接处理”对机器来说,文本必须先被转换成可计算形式。
学完这一页,至少保留这张证据卡:
- 原始文本
- 清洗或分词前的原始示例
- 处理后文本
- 清理后的文本、tokens、归一化说明和已移除项
- 任务边界
- 分类、抽取、检索、生成或 QA 输出
- 失败检查
- 含义丢失、分词不佳、语言问题或标签歧义
- 期望产出
- 前后对比文本样本,以及 token 或表示输出
这节课最该记住的一句话是:
NLP 的本质,是把自然语言变成可计算、可建模、可推理的对象。
后面你会看到:
- 预处理解决“怎么整理文本”
- 文本表示解决“怎么把文本变成数字”
- 模型解决“怎么从数字中学出规律”
只要这张地图在脑子里先立住,11 自然语言处理(方向选修)后面的内容就不容易乱。
- 用自己的话解释:为什么文本处理往往比表格数据更难?
- 把示例里的规则再扩成一个
hotel_booking意图分类。 - 想一想:聊天机器人为什么只是 NLP 的一个应用,不是全部?
- 你能否把一个你熟悉的 AI 产品,拆解成它背后用到的 NLP 任务?
参考实现与讲解
- 文本比表格数据更难,是因为含义依赖顺序、上下文、歧义、标点、拼写变化和领域说法;表格列通常已经把特征边界定义好了。
hotel_booking规则可以先匹配hotel、room、check-in、reservation、stay等词;关键是同时测试正例和容易混淆的反例,比如餐厅预订。- 聊天机器人只是 NLP 的一种应用。NLP 还包括分类、搜索、抽取、摘要、翻译、审核和文档分析。
- 拆解熟悉的 AI 产品时,写出输入、NLP 任务、输出和指标。例如客服助手可能包含意图分类、检索问答、摘要和拒答检查。