13.5 开放权重模型路线:gpt-oss、Qwen、DeepSeek、Llama
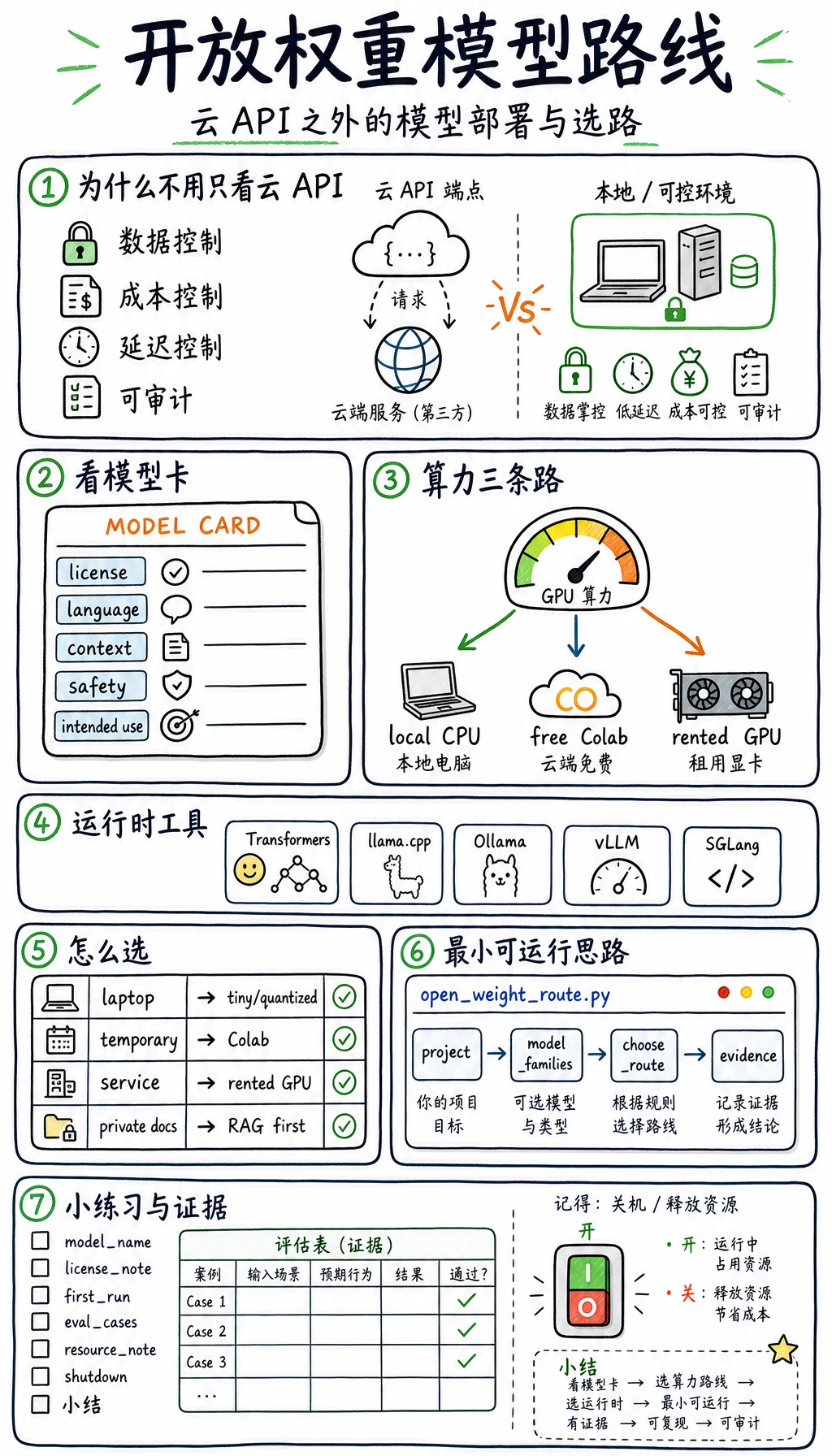
开放权重模型已经成为 AI 工程栈的一部分。OpenAI gpt-oss、Qwen、DeepSeek 风格推理模型、Llama 系列、Mistral 系列等,让团队能更好地控制隐私、成本、延迟和部署。
这一节不要求你追每个模型名。它教一个可重复流程:读模型卡,选 runtime,跑一个小证明,评估结果,然后再决定是否微调。
为什么这项技术会出现
Section titled “为什么这项技术会出现”云 API 让 LLM 应用很容易开始。开放权重模型变重要,是因为团队还需要:
-
数据控制 有些输入不能离开私有机器或 VPC。
-
成本控制 高频推理可能在自有或租用硬件上更便宜。
-
延迟控制 本地或区域部署可以减少网络往返。
-
定制能力 RAG、解码设置、adapter、量化、LoRA 可以围绕具体产品调整。
-
可审计 工程师可以记录模型文件、revision、runtime 设置和评估案例。
代价是你要承担更多系统工程:下载、许可证、显存、驱动、服务、评估和关机。
| 层 | 问题 | 证据 |
|---|---|---|
| 模型卡 | 这个模型允许做什么、适合做什么? | License、语言、上下文、安全说明、适用范围 |
| Runtime | 它怎么运行? | Transformers、llama.cpp、Ollama、vLLM、SGLang 或 notebook |
| 计算路线 | 在哪里运行? | 本地 CPU/GPU、免费 Colab、租 GPU |
| 评估 | 对这个任务够好吗? | 固定 prompt、通过/失败、延迟、内存 |
| 适配 | 要不要调? | 先 Prompt/RAG,再用失败评估证明 LoRA 有必要 |
| 场景 | 第一条路线 | 第一目标 | 停在什么证据上 |
|---|---|---|---|
| 只有笔记本,没有 GPU | 本地 CPU 量化模型 | tiny instruct 或小量化模型 | prompt、输出、耗时、内存 |
| 临时实验 | 可用时用免费 Colab | 小模型和短评估 | Notebook 链接、runtime 类型、重置说明 |
| 需要稳定服务 | 租 GPU | vLLM/SGLang/OpenAI-compatible API | endpoint、请求/响应、每小时成本、停止命令 |
| 需要私有文档 | 本地或私有 GPU | 先 RAG 后微调 | 权限规则、来源 trace、无泄露说明 |
| 需要领域行为变化 | GPU 路线 | 评估失败后才 LoRA | 前后评估和 adapter 产物 |
可运行实验:选择开放权重路线
Section titled “可运行实验:选择开放权重路线”创建 open_weight_route.py,用 Python 3.10 或更高版本运行。脚本不会下载模型,它会生成你花 GPU 钱之前该写的决策卡。
import jsonfrom pathlib import Path
project = { "task": "course Q&A assistant", "privacy": "private_docs", "available_route": "rented_gpu", "needs_service_api": True, "needs_fine_tuning": False, "budget_level": "small",}
model_families = [ {"family": "small instruct model", "fit": ["cpu_lab", "colab"], "runtime": "llama.cpp or Transformers"}, {"family": "Qwen or Llama family", "fit": ["colab", "rented_gpu"], "runtime": "Transformers, vLLM, or SGLang"}, {"family": "gpt-oss family", "fit": ["rented_gpu"], "runtime": "check current model card and runtime support"}, {"family": "reasoning model family", "fit": ["rented_gpu"], "runtime": "serve only after latency and cost checks"},]
def choose_route(info): if info["available_route"] == "local_cpu": return {"route": "local_cpu", "goal": "prove the pipeline with a small quantized model"} if info["available_route"] == "free_colab": return {"route": "free_colab", "goal": "run one notebook experiment and save reset notes"} return {"route": "rented_gpu", "goal": "run a stable API with explicit cost and shutdown"}
def choose_family(info, families): route = choose_route(info)["route"] for item in families: if route in item["fit"]: if info["needs_service_api"] and "vLLM" not in item["runtime"] and route == "rented_gpu": continue return item return families[0]
decision = { "project": project["task"], "route": choose_route(project), "model_family": choose_family(project, model_families), "adaptation": "RAG first; LoRA only after fixed eval failures" if not project["needs_fine_tuning"] else "prepare LoRA after baseline eval", "evidence": [ "model card and license note", "runtime command", "first prompt and output", "five-case eval table", "latency and memory note", "shutdown command", ],}
Path("open_weight_route.json").write_text(json.dumps(decision, indent=2), encoding="utf-8")print(json.dumps(decision, indent=2))预期输出:
{ "project": "course Q&A assistant", "route": { "route": "rented_gpu", "goal": "run a stable API with explicit cost and shutdown" }, "model_family": { "family": "Qwen or Llama family", "fit": [ "colab", "rented_gpu" ], "runtime": "Transformers, vLLM, or SGLang" }, "adaptation": "RAG first; LoRA only after fixed eval failures", "evidence": [ "model card and license note", "runtime command", "first prompt and output", "five-case eval table", "latency and memory note", "shutdown command" ]}project 是约束卡。先改路线、隐私、API 需求和微调需求,再选模型。
model_families 故意不是 benchmark 表,而是规划表。下载或部署前,永远先看当前官方模型卡。
choose_route() 把本地 CPU、免费 Colab、租 GPU 分开。每条路线的证明目标不同。
choose_family() 避免只因为模型流行就选择它。它会先看模型族是否适合路线和 runtime。
decision["evidence"] 是最小运行证据包。没有它之前,不要微调。
把脚本运行三次:
| 运行 | 修改 | 应该发生什么 |
|---|---|---|
| 本地 CPU | available_route="local_cpu", needs_service_api=False | 目标变成证明 pipeline,而不是服务 |
| 免费 Colab | available_route="free_colab" | 证据必须包含重置/runtime 说明 |
| 租 GPU | available_route="rented_gpu", needs_service_api=True | 计划必须包含 API、成本和关机 |
然后写出一个被你拒绝的模型族,以及拒绝理由。
每个开放权重实验都应该保存:
- Model Name
- 尽量写精确 repo 和 revision
- License Note
- 允许什么用途
- Route
- 本地 CPU、免费 Colab 或租 GPU
- Runtime
- 命令和版本
- First Run
- prompt、输出、时间
- Eval
- 至少五个固定案例
- Resource Note
- 内存、延迟、磁盘、成本
- Shutdown
- 如何停止服务或租用实例
- Decision
- 保留、换模型、RAG、LoRA 或停止
开放权重模型带来更多控制,也带来更多工程责任。先做小证明,保存证据,评估后再微调,把租 GPU 当成可复现实验,而不是捷径。
检查理解
能在本地 CPU、免费 Colab、租 GPU 之间选择路线;说出需要的模型卡证据;完成或规划一个小证明;并解释为什么微调应该等到 baseline 评估失败之后,就算通过本节。