4.3.3 偏导数与梯度:多变量的变化方向
- 理解偏导数——固定其他变量,看一个变量的影响
- 理解梯度——所有偏导数组成的向量,指向”上升最快”的方向
- 可视化三维曲面上的梯度
- 理解梯度在神经网络训练中的核心作用
新人先掌握 / 进阶再理解
Section titled “新人先掌握 / 进阶再理解”如果你是第一次学这节,不需要马上熟练推导复杂函数。新人先掌握三句话就够了:偏导数是“只动一个变量看影响”,梯度是“把所有偏导数组成方向”,负梯度是“让损失下降最快的方向”。
如果你已经有一点数学基础,可以进一步关注:为什么梯度方向和等高线垂直、为什么学习率会影响沿负梯度走的效果、以及 PyTorch 的 loss.backward() 本质上在帮你自动计算哪些偏导。
先说一个很重要的学习预期
Section titled “先说一个很重要的学习预期”这一节是很多新人第一次觉得“数学开始真的有点难”的地方。 但这里最重要的,不是一下子把多元微积分全吃透,而是先看懂:
- 单变量导数为什么会自然升级成偏导数
- 梯度为什么会把“很多个变化率”打包成一个方向
- 为什么它会直接决定模型参数怎么调
先建立一张地图
Section titled “先建立一张地图”先看一个故事:你在调一个复杂机器
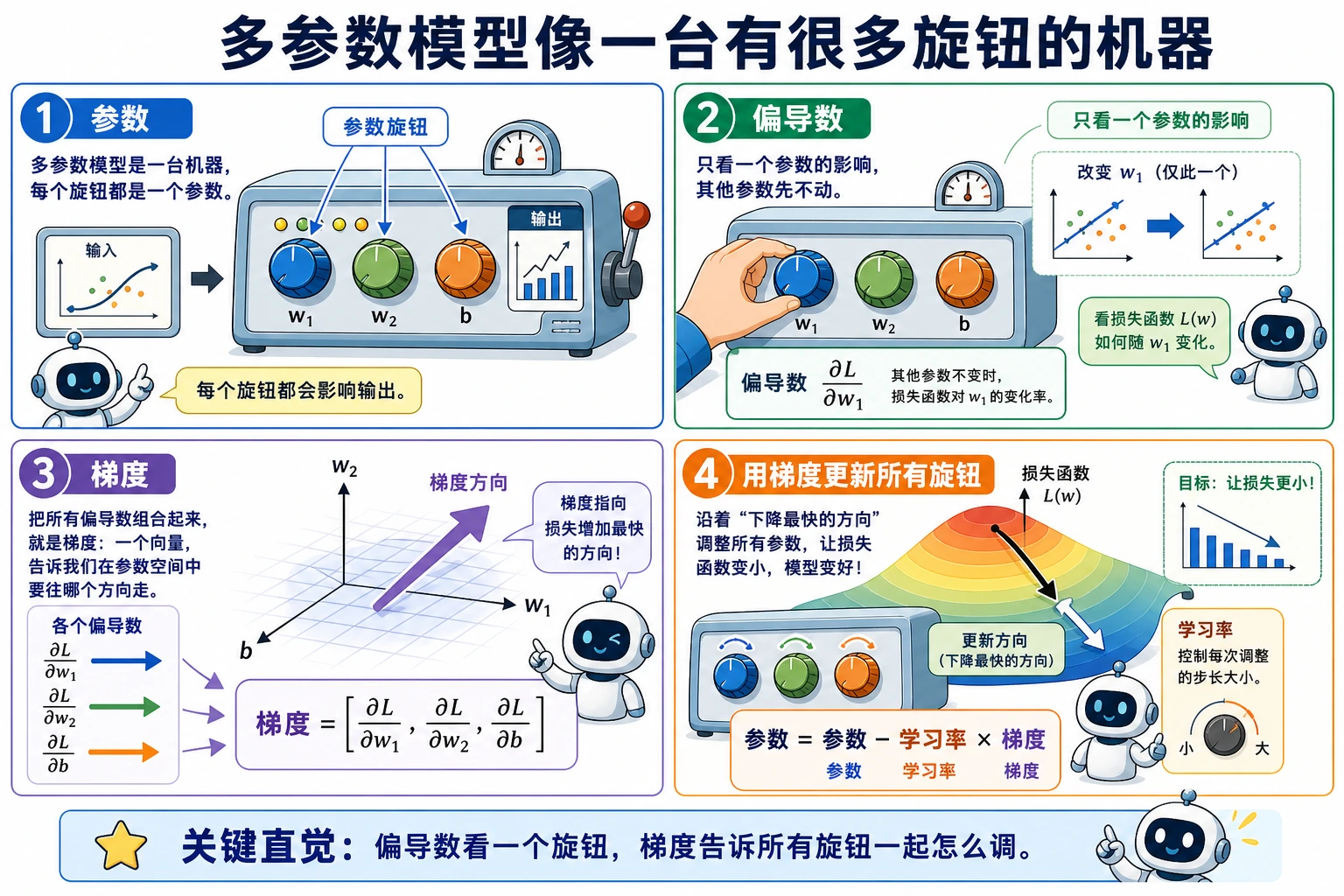
Section titled “先看一个故事:你在调一个复杂机器”想象你面前有一台咖啡机,咖啡味道由很多旋钮共同决定:水温、研磨粗细、咖啡粉量、萃取时间。现在咖啡太苦了,你不能只问“整体哪里错了”,而要一个个试:只调水温会怎样,只调研磨会怎样,只调时间会怎样。
偏导数做的就是这件事:先固定其他旋钮,只看一个旋钮对结果的影响。梯度则是把所有旋钮的影响合成一张“调参指南”,告诉你整体最该往哪个方向改。
上一节你看到的是“一个变量怎么变”,这一节把问题升级成:
如果一个函数同时受很多变量影响,我们怎么知道该往哪个方向调?
这节课最重要的不是先记符号,而是先理解:
- 偏导数是在“其他变量不动”的前提下看一个变量
- 梯度是把所有局部变化信息打包成一个向量
一、偏导数——“只动一个变量”
Section titled “一、偏导数——“只动一个变量””从单变量到多变量
Section titled “从单变量到多变量”上一节的导数只有一个变量。但 AI 中,损失函数通常依赖成千上万个参数。
偏导数的想法很简单:固定其他所有变量不动,只看一个变量的变化对结果的影响。
一个更适合新人的类比
Section titled “一个更适合新人的类比”可以先把偏导数想成“调音台上的单个旋钮”:
- 你先只拧一个旋钮
- 其他旋钮都先别动
- 看输出会怎么变
这就是偏导数最重要的第一层直觉:
先单独看一个变量的影响。
import numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False假设你的考试成绩取决于”学习时间”和”睡眠时间”:
成绩 = f(学习时间, 睡眠时间)
- 偏导数 ∂f/∂学习时间 = 固定睡眠不变,多学 1 小时,成绩提高多少?
- 偏导数 ∂f/∂睡眠时间 = 固定学习不变,多睡 1 小时,成绩提高多少?
f(x, y) = x² + y²
- ∂f/∂x = 2x(把 y 当常数,只对 x 求导)
- ∂f/∂y = 2y(把 x 当常数,只对 y 求导)
# 数值偏导数def partial_derivative(f, args, var_index, h=1e-7): """计算多变量函数 f 对第 var_index 个变量的偏导数""" args_plus = list(args) args_minus = list(args) args_plus[var_index] += h args_minus[var_index] -= h return (f(*args_plus) - f(*args_minus)) / (2 * h)
# f(x, y) = x² + y²f = lambda x, y: x**2 + y**2
# 在 (1, 2) 处的偏导数x0, y0 = 1, 2df_dx = partial_derivative(f, [x0, y0], 0)df_dy = partial_derivative(f, [x0, y0], 1)
print(f"在 ({x0}, {y0}) 处:")print(f" ∂f/∂x = {df_dx:.4f}(精确值: {2*x0})")print(f" ∂f/∂y = {df_dy:.4f}(精确值: {2*y0})")二、梯度——“上升最快的方向”
Section titled “二、梯度——“上升最快的方向””梯度 = 所有偏导数组成的向量。
一个更好记的说法
Section titled “一个更好记的说法”你可以先把梯度理解成:
- 每个变量都有一个“局部变化率”
- 梯度把这些变化率打包成了一支箭头
这支箭头最重要的作用不是“漂亮”,而是:
- 它会告诉你函数往哪边升得最快
对 f(x, y):梯度 = [∂f/∂x, ∂f/∂y]
def gradient(f, args, h=1e-7): """计算多变量函数的梯度""" grad = [] for i in range(len(args)): grad.append(partial_derivative(f, args, i, h)) return np.array(grad)
# 在 (1, 2) 处的梯度grad = gradient(f, [1, 2])print(f"梯度: {grad}") # [2, 4]梯度的方向意义
Section titled “梯度的方向意义”flowchart LR G["梯度方向"] G --> UP["指向函数值<br/>增长最快的方向"] NEG["负梯度方向"] NEG --> DOWN["指向函数值<br/>下降最快的方向"]
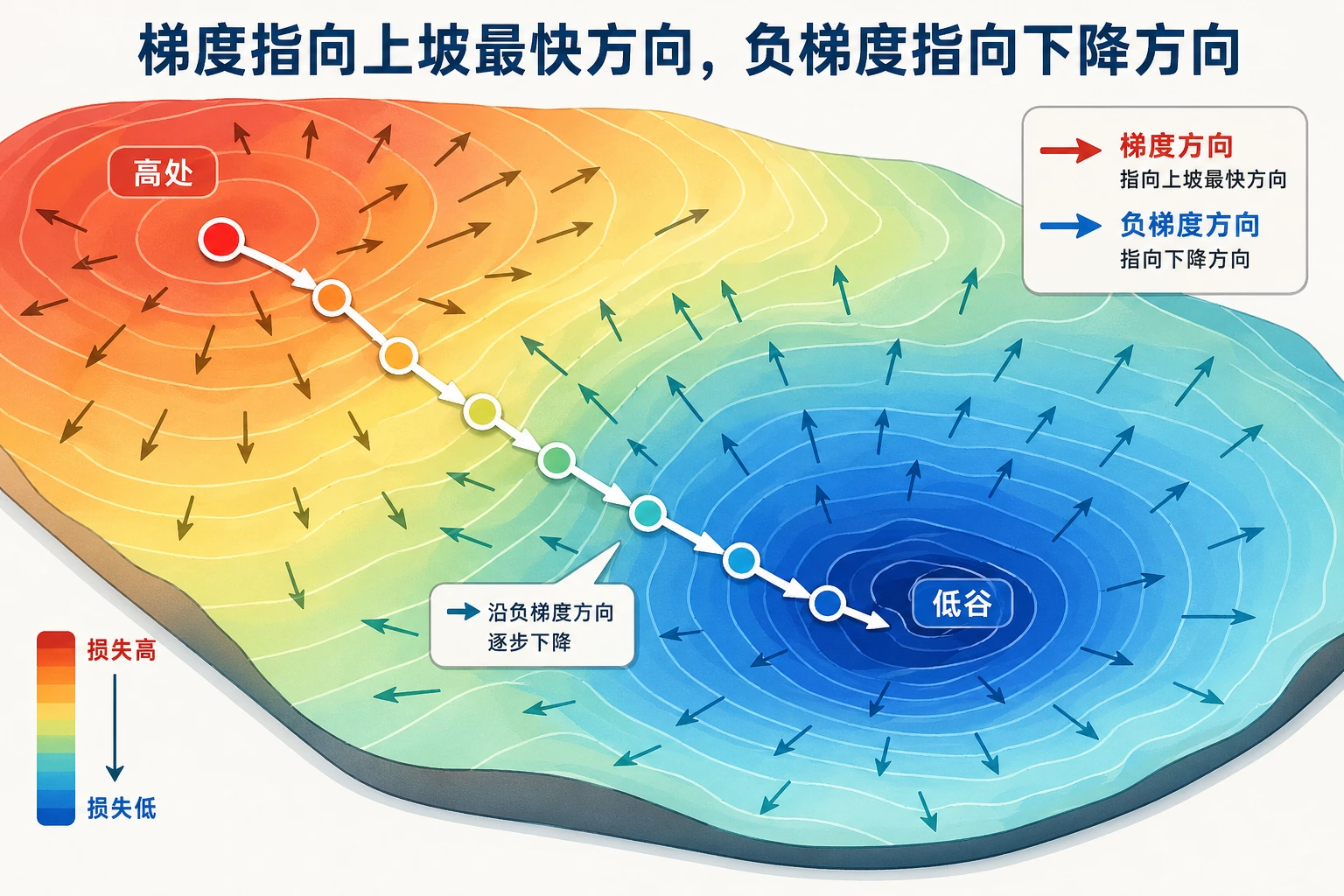
style UP fill:#ffebee,stroke:#c62828,color:#333 style DOWN fill:#e8f5e9,stroke:#2e7d32,color:#333关键洞察:梯度指向”上坡”最快的方向。所以要让损失函数下降,就应该往负梯度方向走。这就是梯度下降的原理。
为什么这一步对 AI 特别关键?
Section titled “为什么这一步对 AI 特别关键?”因为训练模型时,你真正最想知道的就是:
- 参数现在应该往哪边改
而梯度恰好就在回答这个问题。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把梯度想成:
- 站在山坡上的你,脚下最陡的上坡箭头
如果你想往高处走,就沿着梯度方向走; 如果你想往低处走,就沿着负梯度方向走。
这个类比特别值得先记住,因为它会把抽象的“偏导数组成的向量”,重新变成一个很具体的动作问题:
- 我现在该往哪边迈步
可视化:三维曲面上的梯度
Section titled “可视化:三维曲面上的梯度”# f(x, y) = x² + y²(碗形曲面)x = np.linspace(-3, 3, 100)y = np.linspace(-3, 3, 100)X, Y = np.meshgrid(x, y)Z = X**2 + Y**2
# 三维曲面图fig = plt.figure(figsize=(14, 5))
# 左:三维曲面ax1 = fig.add_subplot(121, projection='3d')ax1.plot_surface(X, Y, Z, cmap='coolwarm', alpha=0.8)ax1.set_xlabel('x')ax1.set_ylabel('y')ax1.set_zlabel('f(x,y)')ax1.set_title('f(x,y) = x² + y²(三维视图)')
# 右:等高线 + 梯度箭头ax2 = fig.add_subplot(122)contour = ax2.contourf(X, Y, Z, levels=20, cmap='coolwarm', alpha=0.7)plt.colorbar(contour, ax=ax2)
# 在几个点画梯度箭头points = [(-2, -2), (-1, 1), (1, -1), (2, 2), (0.5, 0.5)]for px, py in points: gx, gy = 2*px, 2*py # 解析梯度 ax2.quiver(px, py, gx, gy, color='black', scale=30, width=0.005)
ax2.set_xlabel('x')ax2.set_ylabel('y')ax2.set_title('等高线 + 梯度方向(箭头)\n箭头指向上升最快的方向')ax2.set_aspect('equal')
plt.tight_layout()plt.show()解读:
- 等高线图中,箭头(梯度)总是垂直于等高线指向高处
- 离中心越远,梯度越大(箭头越长)——表示函数变化越剧烈
- 在最低点 (0,0),梯度为 [0,0]——已经到底了
非碗形曲面的梯度
Section titled “非碗形曲面的梯度”# 更有趣的函数:有多个极值点def rosenbrock(x, y): return (1 - x)**2 + 100 * (y - x**2)**2
x = np.linspace(-2, 2, 200)y = np.linspace(-1, 3, 200)X, Y = np.meshgrid(x, y)Z = rosenbrock(X, Y)
fig, ax = plt.subplots(figsize=(10, 8))contour = ax.contourf(X, Y, np.log1p(Z), levels=30, cmap='viridis', alpha=0.8)plt.colorbar(contour, ax=ax, label='log(1 + f(x,y))')
# 画几个点的梯度for px, py in [(-1, 1), (0, 0), (1, 1), (1.5, 2)]: grad = gradient(rosenbrock, [px, py]) # 缩放梯度方便显示 norm = np.linalg.norm(grad) if norm > 0: grad_scaled = grad / norm * 0.3 ax.quiver(px, py, -grad_scaled[0], -grad_scaled[1], color='red', scale=3, width=0.008)
ax.plot(1, 1, 'r*', markersize=20, label='最小值 (1, 1)')ax.set_xlabel('x')ax.set_ylabel('y')ax.set_title('Rosenbrock 函数(优化的经典测试函数)\n红色箭头 = 负梯度方向(下降方向)')ax.legend(fontsize=12)plt.show()三、梯度在神经网络中的意义
Section titled “三、梯度在神经网络中的意义”损失函数的梯度
Section titled “损失函数的梯度”在神经网络中:
- 参数 = 数千到数十亿个权重 [w1, w2, …, wn]
- 损失函数 = L(w1, w2, …, wn)
- 梯度 = [∂L/∂w1, ∂L/∂w2, …, ∂L/∂wn]
梯度告诉我们:每个权重应该增大还是减小,才能让损失减少。
# 模拟:一个只有 2 个参数的简单模型# 损失函数 L(w1, w2) = (w1 - 3)² + (w2 + 1)²# 最优解:w1 = 3, w2 = -1
def loss(w1, w2): return (w1 - 3)**2 + (w2 + 1)**2
# 当前参数w1, w2 = 0, 0grad = gradient(loss, [w1, w2])
print(f"当前参数: w1={w1}, w2={w2}")print(f"当前损失: {loss(w1, w2)}")print(f"梯度: {grad}")print(f"→ w1 的偏导数 = {grad[0]:.1f}(负数 → w1 应该增大)")print(f"→ w2 的偏导数 = {grad[1]:.1f}(正数 → w2 应该减小)")高维梯度的挑战
Section titled “高维梯度的挑战”| 模型 | 参数数量 | 梯度维度 |
|---|---|---|
| 线性回归 | 几个~几百 | 几个~几百 |
| CNN (ResNet-50) | 2500 万 | 2500 万维梯度 |
| BERT | 1.1 亿 | 1.1 亿维梯度 |
| GPT-3 | 1750 亿 | 1750 亿维梯度 |
虽然维度极高,但梯度的计算规则是一样的——每个参数的偏导数。PyTorch 的 autograd 会自动帮你高效计算。
再看一个最小“按梯度更新参数”示例
Section titled “再看一个最小“按梯度更新参数”示例”def loss(w1, w2): return (w1 - 3)**2 + (w2 + 1)**2
def grad_loss(w1, w2): return np.array([2 * (w1 - 3), 2 * (w2 + 1)])
w = np.array([0.0, 0.0])lr = 0.1
for step in range(3): grad = grad_loss(w[0], w[1]) w = w - lr * grad print(f"step={step+1}, w={np.round(w, 4)}, loss={round(loss(w[0], w[1]), 4)}")这个例子特别适合初学者,因为它第一次把“梯度只是一个方向”真正变成了:
- 参数怎么被一步步改掉
也就是说,梯度不只是数学对象, 它会直接变成训练里的更新动作。
一个很适合初学者先记的对比表
Section titled “一个很适合初学者先记的对比表”| 概念 | 最值得先记住的问法 |
|---|---|
| 偏导数 | 如果只拧这一个旋钮,结果怎么变? |
| 梯度 | 如果把所有旋钮的变化率合在一起,最该往哪边调? |
| 负梯度 | 如果我想让损失下降,最该往哪边走? |
这个表特别适合新人,因为它能把“多变量微积分”重新压回到几个可操作的问题上。
一个常见错误:沿着梯度方向更新损失
Section titled “一个常见错误:沿着梯度方向更新损失”很多新人第一次写梯度下降时,会不小心写成:
w = w + lr * grad如果你的目标是让损失变小,这通常方向反了。因为梯度指向的是函数值上升最快的方向,最小化损失时应该沿负梯度走:
w = w - lr * grad可以用下面的小例子直观看到差别:
def loss_1d(w): return (w - 3) ** 2
def grad_1d(w): return 2 * (w - 3)
for direction in ["wrong", "right"]: w = 0.0 lr = 0.1 print("\n方向:", direction) for step in range(3): grad = grad_1d(w) if direction == "wrong": w = w + lr * grad else: w = w - lr * grad print(f"step={step+1}, w={w:.3f}, loss={loss_1d(w):.3f}")这个错例很值得记住:如果你发现训练越训 loss 越大,第一件事就应该检查更新方向和学习率。
学到这里,下一步最值得带去哪里?
Section titled “学到这里,下一步最值得带去哪里?”看完偏导数与梯度以后,最值得带去下一节的问题是:
- 如果梯度已经告诉我方向,那怎样真的沿着这个方向走?
- 为什么训练不是一下到位,而是一轮轮更新?
- 学习率到底在“往哪调”之外又决定了什么?
最适合接着看的通常是:
学完这一页,至少保留这张证据卡:
- 函数
- 目标函数、损失、导数、梯度或链式法则表达式
- 计算
- 数值导数、梯度步长或反向传播轨迹
- 输出
- 斜率、梯度向量、更新后的参数,或损失变化
- 失败检查
- 符号错误、学习率过大、局部斜率理解错误或链式法则出错
- 期望产出
- 展示参数如何变化的计算轨迹
| 概念 | 直觉 | Python |
|---|---|---|
| 偏导数 | 固定其他变量,看一个变量的影响 | partial_derivative(f, args, i) |
| 梯度 | 所有偏导数的向量,指向上升最快方向 | gradient(f, args) |
| 负梯度 | 指向下降最快方向 | -gradient(f, args) |
| 梯度大小 | 函数变化的剧烈程度 | np.linalg.norm(grad) |
这节最该带走什么
Section titled “这节最该带走什么”- 偏导数最重要的直觉是“先只看一个变量怎么影响结果”
- 梯度最重要的直觉是“把很多局部变化率打包成一个方向”
- 在 AI 里,梯度最关键的价值是告诉模型参数该往哪边调
这一节的学习闭环
Section titled “这一节的学习闭环”学完这一节后,你可以用下面这张表检查自己是不是真的理解了:
| 层次 | 你应该能做到什么 |
|---|---|
| 直觉 | 能解释“只动一个变量”和“沿负梯度下降”是什么意思 |
| 代码 | 能用数值差分计算一个二维函数的偏导数和梯度 |
| 图像 | 能看懂等高线图里的梯度箭头为什么指向高处 |
| 连接 AI | 能说清楚为什么训练模型时需要梯度来更新参数 |
练习 1:计算梯度
Section titled “练习 1:计算梯度”用 gradient 函数计算 f(x, y) = x²y + xy² 在 (2, 3) 处的梯度。手算验证(∂f/∂x = 2xy + y², ∂f/∂y = x² + 2xy)。
练习 2:可视化梯度场
Section titled “练习 2:可视化梯度场”画出 f(x, y) = sin(x) + cos(y) 的等高线图和梯度箭头(使用 plt.quiver)。
练习 3:三变量梯度
Section titled “练习 3:三变量梯度”对 f(x, y, z) = x² + 2y² + 3z²,在 (1, 1, 1) 处计算梯度,判断哪个方向变化最快。
解题思路与讲解
- 对
f(x,y)=x^2y+xy^2,梯度是[2xy+y^2, x^2+2xy];在(2,3)处是[21,16]。 - 对
sin(x)+cos(y),梯度箭头应遵循[cos(x), -sin(y)]。等高线图和箭头在视觉上应一致:箭头指向增长更快的方向。 - 对
x^2+2y^2+3z^2,在(1,1,1)处梯度是[2,4,6],所以最快增加方向就是这个向量方向;最快下降方向是它的相反方向。