7.3.4 主流大模型架构变体
- 理解仅编码器、仅解码器、编码器-解码器的核心差异
- 理解架构选择和训练目标、任务类型之间的关系
- 通过一个可运行示例看清不同 mask 背后的信息流
- 建立“这个任务更适合哪类结构”的第一层判断
一、为什么同样是 Transformer,会长出这么多分支?
Section titled “一、为什么同样是 Transformer,会长出这么多分支?”因为任务不一样,信息流约束也不一样
Section titled “因为任务不一样,信息流约束也不一样”不同 NLP 任务的本质需求不同:
- 文本分类更在意“看懂整句”
- 开放式生成更在意“只能根据过去继续写”
- 翻译摘要更在意“先编码输入,再生成输出”
所以哪怕底层积木都是 Transformer block, 最后也会长成不同结构。
一个简单类比
Section titled “一个简单类比”你可以把三种经典架构理解成三种阅读方式:
- 仅编码器:整篇文章先通读一遍,再做判断
- 仅解码器:只能一边写一边往前看,不能偷看后文
- 编码器-解码器:先认真读原文,再根据原文写摘要或翻译
只要这个类比成立, 后面的差异就会自然很多。
二、三种经典结构分别在做什么?
Section titled “二、三种经典结构分别在做什么?”仅编码器:适合理解,不擅长开放式续写
Section titled “仅编码器:适合理解,不擅长开放式续写”Encoder-only 的典型代表是:
- BERT
它的特点是:
- 每个位置都可以看到左右两边上下文
- 更容易形成完整语义表示
- 很适合分类、匹配、抽取等理解任务
但它不天然适合做自由生成, 因为训练时并没有严格遵守“只能看过去”的约束。
仅解码器:生成路线最直接
Section titled “仅解码器:生成路线最直接”Decoder-only 的典型代表是:
- GPT
- LLaMA
- Qwen
它的关键约束是:
- 当前 token 只能看自己前面的 token
这和生成任务完全一致,因为生成时我们本来也只能一步一步往后写。
它的优点是:
- 训练目标统一
- 生成流程自然
- 很适合大规模自回归建模
编码器-解码器:输入输出职责分开
Section titled “编码器-解码器:输入输出职责分开”Encoder-Decoder 的典型代表是:
- T5
- BART
它的思路是:
- 编码器先把输入理解好
- 解码器再在输入表示基础上生成输出
这类结构特别适合:
- 翻译
- 摘要
- 改写
- 问答生成
因为这些任务天然就是:
- 输入一段东西
- 输出另一段东西
MoE:不是改信息流,而是改“谁来算”
Section titled “MoE:不是改信息流,而是改“谁来算””当模型变得越来越大后, 另一条重要分支出现了:
- Mixture of Experts
它的重点不是改变自注意力的基本规则, 而是:
让不同 token 只激活部分专家网络,而不是每次都走完整个大 FFN。
这样做的核心目的是:
- 在扩大参数规模的同时,控制每次前向实际激活的计算量
所以 MoE 更像“规模化路线的变体”。
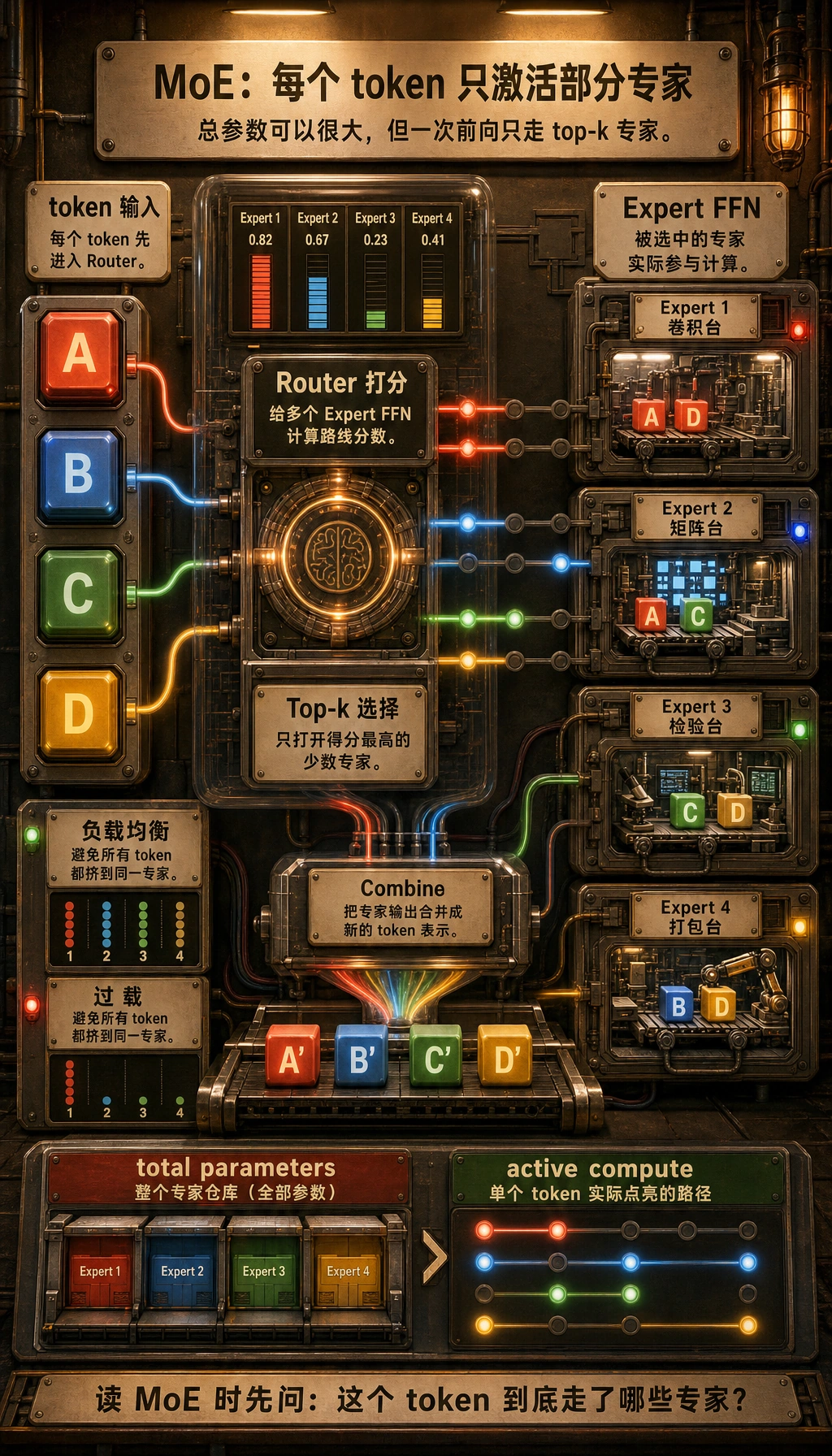
新人不要跳过的 MoE 术语
Section titled “新人不要跳过的 MoE 术语”| 术语 | 通俗含义 | 为什么重要 |
|---|---|---|
| 路由器 | 决定一个 token 该走哪些专家的模块 | 它决定每个 token 的计算路径 |
| Top-k | 只选择得分最高的 k 个专家 | 它控制每个 token 激活多少专家 |
| 负载均衡 | 避免太多 token 都挤到同一个专家 | 否则有的专家过载,有的专家几乎不工作 |
| Expert FFN | 专家池里的前馈子网络 | MoE 通常替换或扩展 dense FFN 部分 |
| 激活计算量 | 一个 token 实际用到的参数和计算 | 它和总参数量不是同一件事 |
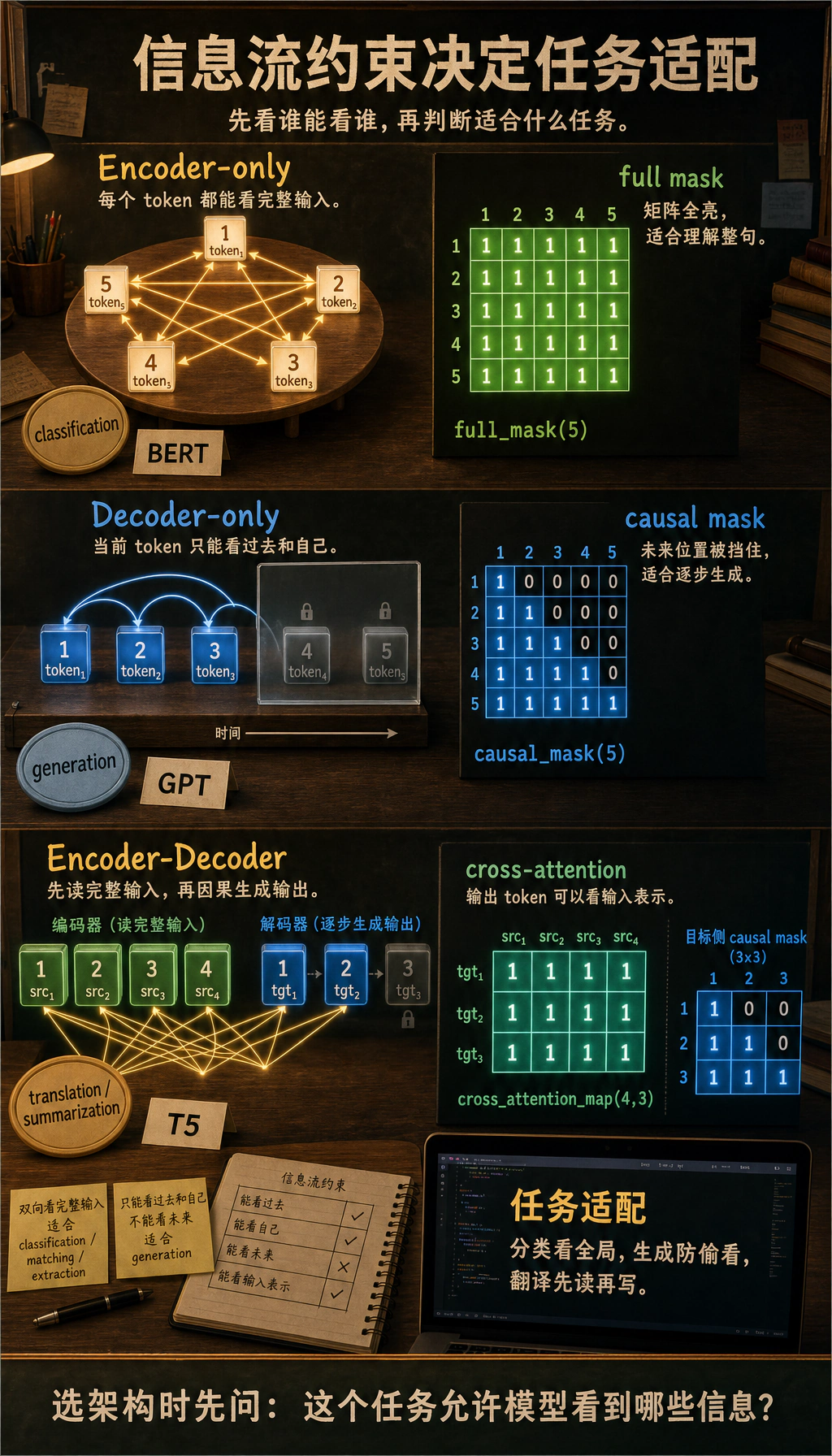
三、先跑一个真正有教学意义的结构差异示例
Section titled “三、先跑一个真正有教学意义的结构差异示例”下面这段代码不会去训练模型, 但它会直接把三种核心架构最重要的差别打印出来:
- 哪些位置能看到哪些位置
这比单纯打印一个字典更接近结构本体。
def full_mask(length): return [[1 for _ in range(length)] for _ in range(length)]
def causal_mask(length): return [[1 if j <= i else 0 for j in range(length)] for i in range(length)]
def cross_attention_map(src_length, tgt_length): return [[1 for _ in range(src_length)] for _ in range(tgt_length)]
def pretty_print(title, matrix): print(title) for row in matrix: print(" ".join(str(x) for x in row)) print()
length = 5pretty_print("encoder-only self-attention", full_mask(length))pretty_print("decoder-only self-attention", causal_mask(length))pretty_print("encoder-decoder cross-attention", cross_attention_map(4, 3))预期输出:
encoder-only self-attention1 1 1 1 11 1 1 1 11 1 1 1 11 1 1 1 11 1 1 1 1
decoder-only self-attention1 0 0 0 01 1 0 0 01 1 1 0 01 1 1 1 01 1 1 1 1
encoder-decoder cross-attention1 1 1 11 1 1 11 1 1 1这段代码到底在教什么?
Section titled “这段代码到底在教什么?”它在教三件最根本的事:
- 仅编码器是双向看的
- 仅解码器是因果看的
- 编码器-解码器里的解码器还能额外看输入序列
也就是说, 大部分架构差异最后都能追溯到:
- 信息流限制不同
为什么 mask 这么重要?
Section titled “为什么 mask 这么重要?”因为 mask 决定了模型训练时到底允许自己知道什么。
如果 decoder 没有 causal mask, 模型训练时就会偷看未来 token, 到真正生成时又看不到未来,训练-推理就不一致了。
为什么这能决定任务适配?
Section titled “为什么这能决定任务适配?”因为任务本身就对应不同信息流:
- 分类:允许看完整输入
- 生成:不能看未来
- 翻译:输出可以看完整输入,但不能看未来输出
结构是否合适,本质上就是信息流约束是否匹配任务。
四、把三条路线和典型任务连起来
Section titled “四、把三条路线和典型任务连起来”文本理解任务为什么常用仅编码器?
Section titled “文本理解任务为什么常用仅编码器?”因为这类任务更关注:
- 句子整体意思
- token 之间双向关系
- 一个位置对前后上下文的综合理解
例如:
- 情感分类
- 语义匹配
- 命名实体识别
这些任务更像“读完整段再判断”。
为什么现在大模型主流几乎都走仅解码器?
Section titled “为什么现在大模型主流几乎都走仅解码器?”因为当目标变成:
- 通用对话
- 开放生成
- 代码补全
- 长文本续写
decoder-only 结构最顺手。
再加上:
- 预训练目标统一
- 推理路径清晰
- 扩到超大规模后效果很好
于是它成了大语言模型时代的主流路线。
编码器-解码器为什么没有消失?
Section titled “编码器-解码器为什么没有消失?”因为很多任务仍然非常适合它:
- 翻译
- 摘要
- 文本改写
- 输入输出结构差异明显的生成任务
如果任务天然是“给定输入,生成另一段输出”, encoder-decoder 依然很有优势。
MoE 适合什么情况?
Section titled “MoE 适合什么情况?”当团队在追求:
- 更大参数规模
- 但又不想每次前向都把所有参数算一遍
就会开始关注 MoE。
但它也会带来新工程问题:
- 路由是否稳定
- 负载是否均衡
- 分布式训练是否更复杂
五、结构差异不只是“谁更强”,而是“谁更合适”
Section titled “五、结构差异不只是“谁更强”,而是“谁更合适””不存在永远最强的通用结构
Section titled “不存在永远最强的通用结构”很多新人会问:
- BERT、GPT、T5 到底谁更强?
其实更合理的问题是:
- 任务是什么?
- 训练目标是什么?
- 推理方式是什么?
结构不是排行榜, 而是任务匹配问题。
很多“效果差距”其实来自训练规模和数据,不只是结构
Section titled “很多“效果差距”其实来自训练规模和数据,不只是结构”例如 GPT 系列强,不只是因为 decoder-only, 还因为:
- 数据量大
- 参数量大
- 工程成熟
所以不要把结构本身神化成唯一因素。
结构和目标函数是绑在一起看的
Section titled “结构和目标函数是绑在一起看的”通常你会看到这样的耦合:
- 仅编码器 + masked language modeling
- 仅解码器 + causal language modeling
- 编码器-解码器 + seq2seq / denoising
也就是说, 架构和训练目标通常是一整套设计,而不是随便拼。
六、常见误区
Section titled “六、常见误区”误区一:BERT 只是“老模型”,所以没必要学
Section titled “误区一:BERT 只是“老模型”,所以没必要学”不对。 它仍然是理解任务和表示学习的重要基线。
误区二:仅解码器什么都能做,所以一定是最优解
Section titled “误区二:仅解码器什么都能做,所以一定是最优解”它确实很通用, 但对某些输入输出明确分离的任务, encoder-decoder 仍然可能更自然。
误区三:MoE 只是“更大的普通模型”
Section titled “误区三:MoE 只是“更大的普通模型””不完全对。 MoE 的核心变化在于:
- 参数规模和实际激活计算被拆开了
这会改变训练和部署复杂度。
学完这一页,至少保留这张证据卡:
- 仅编码器
- 双向理解任务
- 仅解码器
- 因果生成和聊天模型
- 编码器-解码器
- 读取一个序列并生成另一个序列
- 选择规则
- 架构要符合任务和服务模式
- 避免误读
- 变体名称不是简单的质量排名
这一节最重要的不是记名字, 而是建立一张结构地图:
仅编码器更像“通读后理解”,仅解码器更像“按时间顺序生成”,编码器-解码器更像“先读再写”,MoE 则是在规模化时改变计算路径。
只要你能把架构、任务和信息流这三件事连起来, 以后再看到新的模型名字时,就不会只剩“它很火”这种印象了。
- 用自己的话解释:为什么 causal mask 是仅解码器的核心约束?
- 想一个翻译或摘要任务,说明它为什么天然适合编码器-解码器。
- 如果要做文本分类,你会更优先考虑仅编码器还是仅解码器?为什么?
- 假设你要继续做超大模型扩展,但每步计算预算有限,为什么 MoE 会变得有吸引力?
解题思路与讲解
- Causal mask 让每个 token 只能根据过去预测,不能偷看未来。正是这个约束把 Transformer block 变成了自回归生成器。
- 翻译和摘要天然有“输入序列”和“输出序列”。Encoder 可以完整阅读源文本,Decoder 再一边看源文本表示,一边逐步生成目标文本。
- 经典文本分类通常优先考虑 Encoder-only,因为它能双向读取完整输入,并形成紧凑表示。Decoder-only 也能分类,但更常在需要生成能力或统一 LLM 接口时使用。
- MoE 每个 token 只激活部分专家。它能增加总参数容量,同时不让每一步训练或推理都为所有专家付费。