E.A.1 C++ 编程基础
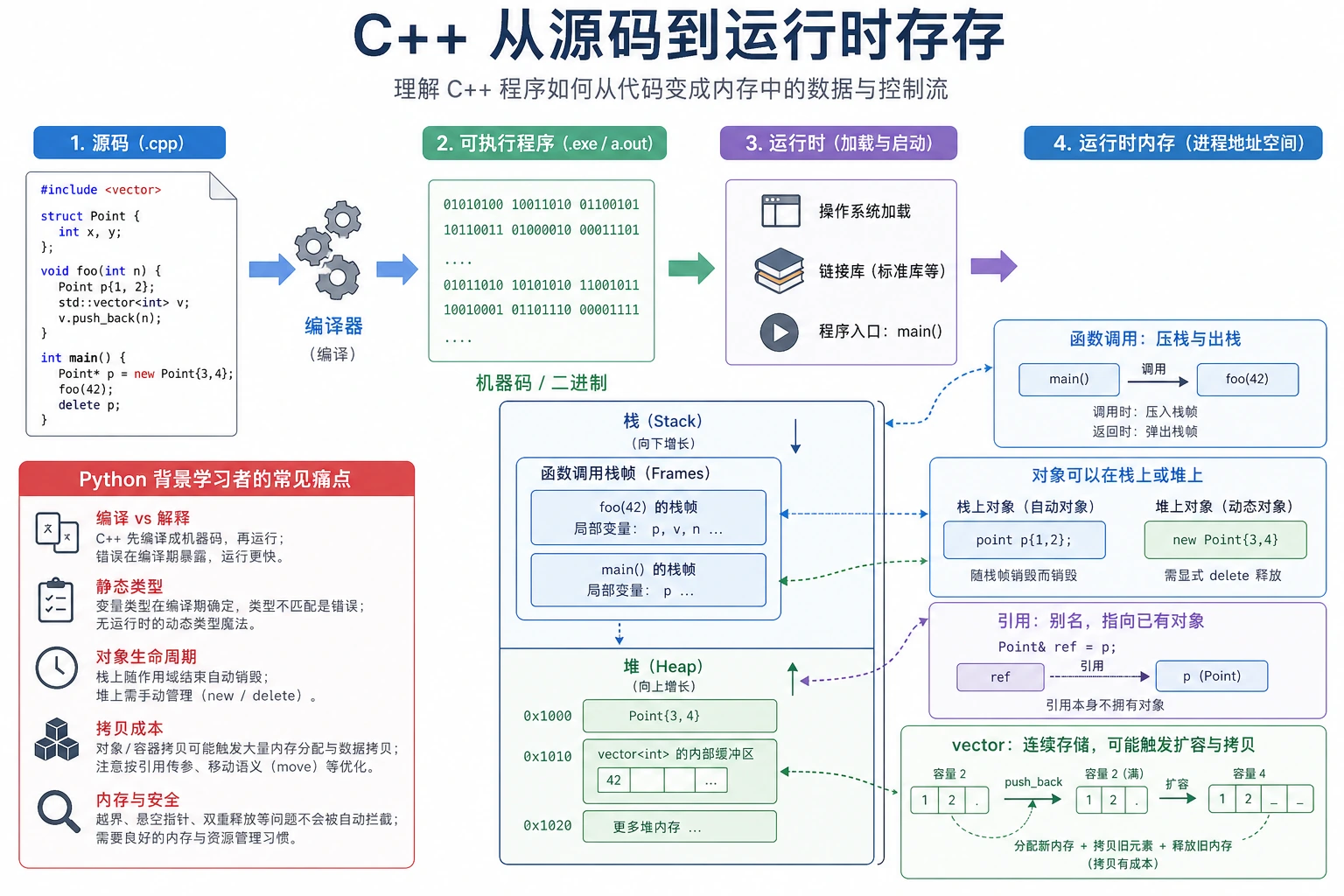
读部署代码前,你不需要先变成 C++ 专家。先掌握反复出现的小集合:类型、函数、std::vector、引用、编译和清晰输出。
运行最小推理风格程序
Section titled “运行最小推理风格程序”创建 demo.cpp:
#include <iostream>#include <vector>
int main() { std::vector<float> logits = {1.2f, 0.3f, 2.1f}; int best_index = 0;
for (int i = 1; i < static_cast<int>(logits.size()); ++i) { if (logits[i] > logits[best_index]) { best_index = i; } }
std::cout << "best_class=" << best_index << "\n"; std::cout << "score=" << logits[best_index] << "\n"; return 0;}运行:
c++ -std=c++17 demo.cpp -o demo./demo预期输出:
best_class=2score=2.1| C++ 点 | 部署含义 |
|---|---|
std::vector<float> | 一个简单的类 tensor 容器 |
明确类型 float / int | 编译器必须知道数据和值类型 |
static_cast<int>(...) | 明确转换类型,而不是赌它能跑 |
| 先编译再运行 | 部署通常产出二进制,而不只是脚本 |
| 打印结果 | 每个部署测试都需要可复现证据 |
像读部署代码一样读它
Section titled “像读部署代码一样读它”在推理 runtime 或部署代码里看到 C++ 时,先盯住三件事:
- 数据容器:它承载的是什么形状、什么数值类型。这里是很小的
std::vector<float>,真实系统里可能是 tensor buffer。 - 代码和证据的边界:能编译说明代码合法,能打印稳定结果说明运行路径真的走通了。
- 失败点:如果结果不对,先查输入值、索引逻辑、类型转换和最终输出,不要一上来就重写整个程序。
这个小例子不是为了讲完 C++,而是训练部署习惯:让输入可见、让决策规则可见、让别人能重跑输出。
复盘这段程序时,不要只说“编译成功”。要说清楚输入是什么、决策规则是什么、输出为什么稳定。真实推理代码也是一样:logits、阈值、类别映射和输出格式都应该能被检查。
如果你把这个例子换成真实模型输出,最小证据仍然不变:编译命令、运行命令、输入样例、输出结果,以及一次改变输入后的结果变化。
交付检查时,把 demo.cpp 当成一个很小的部署单元。代码能编译,说明语法和链接路径没问题;输出能复现,说明运行路径没问题;修改 logits 后类别变化,说明决策逻辑没被写死。三件事都成立,才算真正跑通。
把 logits 改成:
std::vector<float> logits = {3.4f, 0.3f, 2.1f};再次运行,预期 best_class 变成 0。
操作参考与检查点
修改后,循环会比较 3.4、0.3 和 2.1,最大值在下标 0,所以输出类别应变为 0。重点不只是“数值更大”,而是这个推理辅助程序扫描 logit 向量,并返回最大值所在的位置。
至少留下这些证据:
- 编译命令可以成功运行。
- 输出变成
best_class=0。 - 你能说明
std::vector<float>在这里代表一个很小的 tensor 或模型输出数组。
学完这一页,至少保留这张证据卡:
- 部署目标
- 本地推理、边缘设备、模型服务器或优化实验
- 工件
- C++ 代码片段、基准测试、模型工件、服务配置或部署说明
- 指标
- 延迟、内存、吞吐量、模型大小、准确率下降或可靠性
- 失败检查
- ABI/构建问题、硬件不匹配、量化损失或服务瓶颈
- 期望产出
- 可复现的部署或优化证据,而不只是理论笔记
你能编译文件、修改输入值、解释为什么类别改变,并说清楚 std::vector<float> 在推理程序里代表什么,就算通过。