11.6.1 预训练模型路线图:BERT、GPT、T5
预训练模型让 NLP 从单任务训练进入可复用基础模型:先在大规模文本上预训练,再迁移到下游任务。
预训练模型为什么会出现
Section titled “预训练模型为什么会出现”在预训练模型成为主线之前,很多 NLP 项目是“一个任务训练一个模型”:分类训分类模型,NER 训序列标注模型,翻译训 Seq2Seq 模型。问题是这些任务都需要理解词义、语法和上下文,如果每次都从小数据集重新学,会浪费且不稳定。
预训练模型把路线改成:
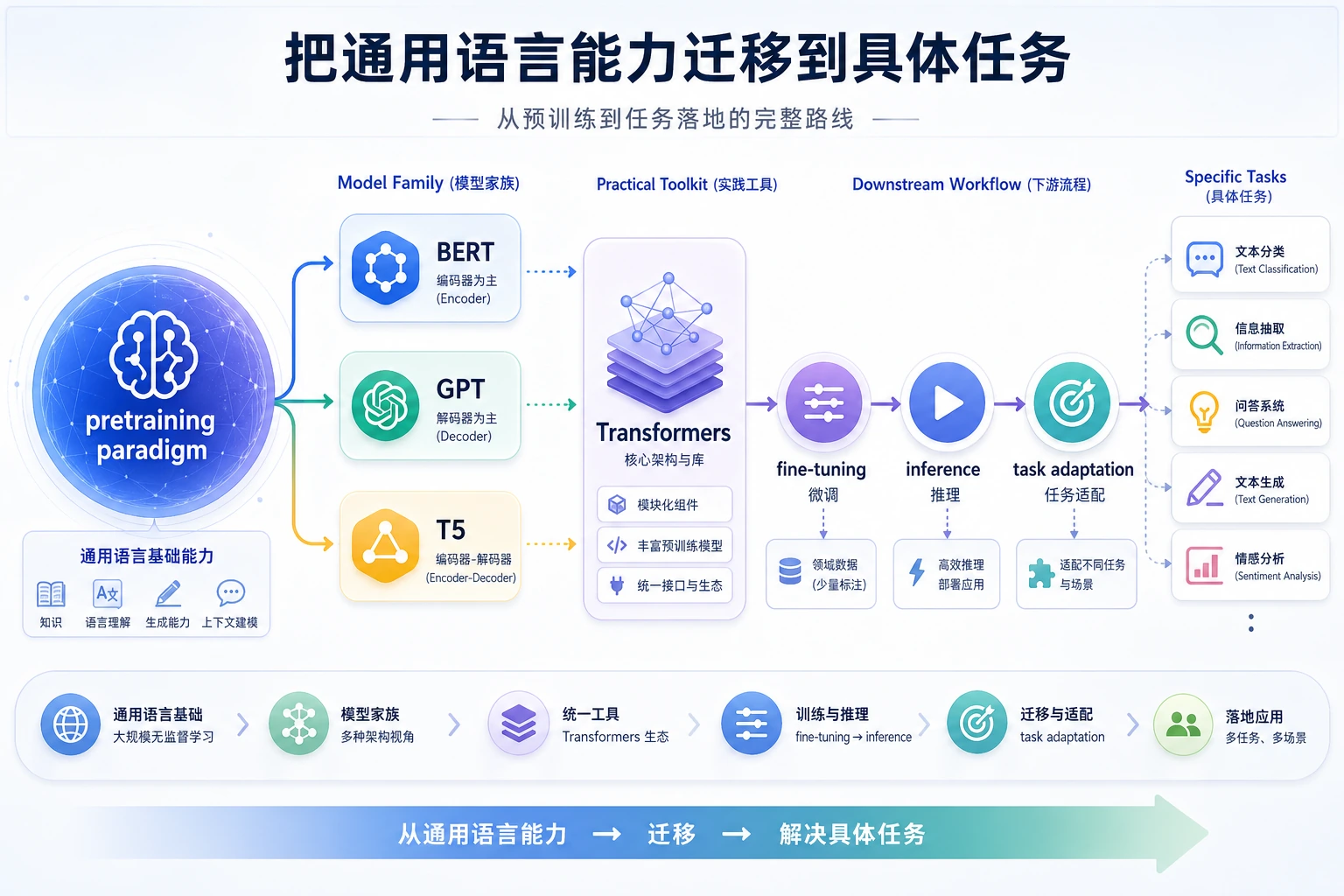
先用大规模文本学习通用语言能力-> 再把这份能力迁移到分类、抽取、问答、摘要或生成不同模型家族的出现,也对应不同任务目标:
| 模型家族 | 历史上主要解决什么 | 更适合先想到的任务 |
|---|---|---|
| BERT | 双向理解一句话或一段文本 | 分类、匹配、抽取、NER |
| GPT | 根据前文生成后文 | 对话、写作、代码、续写 |
| T5 | 把各种任务统一成 text-to-text | 翻译、摘要、改写、问答 |
这条历史线能帮助你避免只背模型名。选择模型时先看任务输出,再看训练目标是否匹配。
先看范式地图
Section titled “先看范式地图”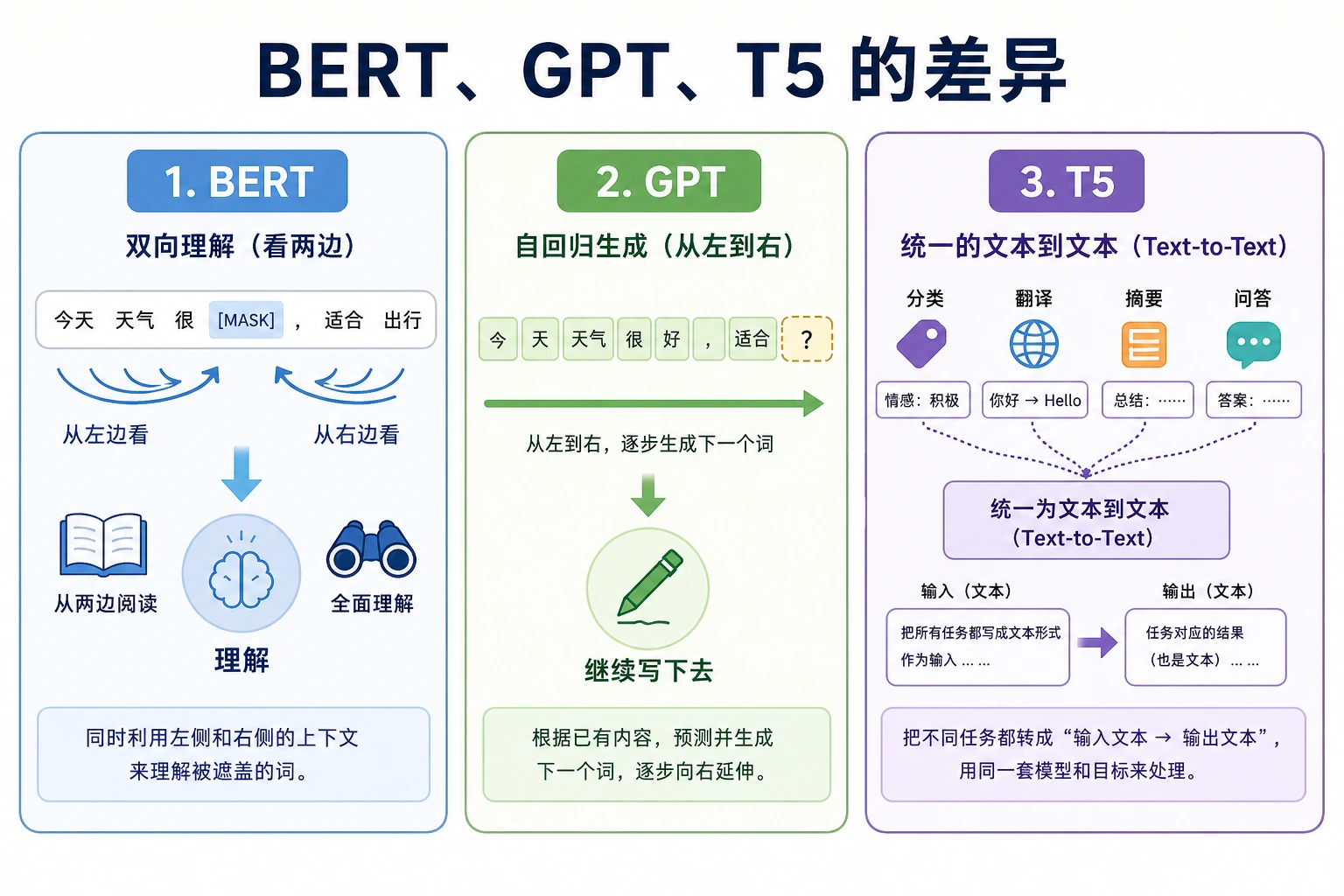

BERT 偏理解,GPT 偏生成,T5 把很多任务改写成 text-to-text。
跑一个模型家族选择检查
Section titled “跑一个模型家族选择检查”task = { "needs_generation": True, "needs_sentence_label": False, "needs_text_to_text": True,}
if task["needs_text_to_text"]: family = "T5-style text-to-text"elif task["needs_generation"]: family = "GPT-style autoregressive"else: family = "BERT-style understanding"
print("family:", family)print("reason:", "match model objective to task output")预期输出:
family: T5-style text-to-textreason: match model objective to task output不要只按模型名称选择。要匹配 tokenizer、训练目标、输出格式、成本和部署约束。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 预训练范式 | 解释 pretrain → transfer → fine-tune/infer |
| 2 | BERT | 理解 mask prediction 和双向表示 |
| 3 | GPT | 理解 next-token generation 和上下文窗口 |
| 4 | T5 | 把任务改写成 text-to-text 形式 |
| 5 | Transformers 实战 | 连接 tokenizer、model、pipeline、input、output |
如果你能解释不同训练目标为什么带来不同优势,并运行或设计一个小型预训练模型对比实验,就通过了本章。
检查思路与讲解
- 合格答案要从文本单元和输出类型说起:token、span、句子标签、序列、embedding 或生成文本。
- 证据应包含小样本、模型或 pipeline 选择、评价指标,以及至少一个被检查过的错误案例。
- 自检时要能区分预处理问题和模型问题,例如分词错误、标签歧义、数据不平衡或生成幻觉。
学完这一页,至少保留这张证据卡:
- 模型选择
- BERT、GPT、T5、Transformer 流水线或其他预训练基线
- tokenizer 输出
- id、mask、解码文本或批次形状
- 任务结果
- 分类、生成、抽取或文本到文本输出
- 失败检查
- 错误的模型家族、token 限制、领域不匹配、成本或延迟
- 期望产出
- 模型调用结果加一段简短的选择理由