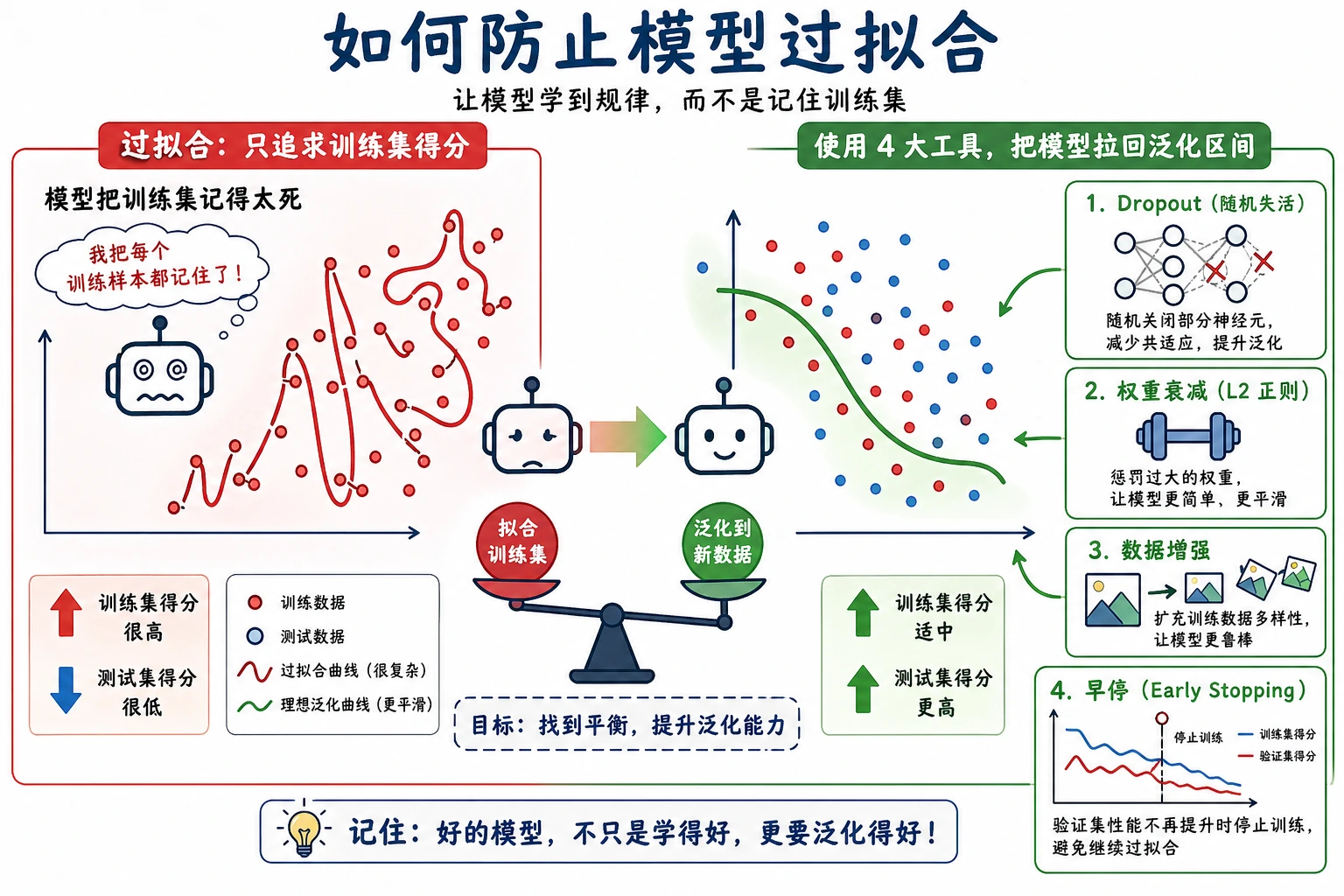
6.1.6 正则化
你会做出什么
Section titled “你会做出什么”这一节会运行一个 PyTorch 实验,比较:
- 不使用正则化;
- dropout;
- weight decay;
- dropout + weight decay;
- 通过
best_epoch观察 early stopping 行为。
python -m pip install -U torch scikit-learn运行完整实验
Section titled “运行完整实验”新建 regularization_lab.py:
import torchimport torch.nn as nnfrom sklearn.datasets import make_moonsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
def make_data(): X, y = make_moons(n_samples=500, noise=0.28, random_state=42) X = StandardScaler().fit_transform(X) X_train, X_val, y_train, y_val = train_test_split( X, y, test_size=0.35, random_state=42, stratify=y ) return ( torch.tensor(X_train, dtype=torch.float32), torch.tensor(y_train.reshape(-1, 1), dtype=torch.float32), torch.tensor(X_val, dtype=torch.float32), torch.tensor(y_val.reshape(-1, 1), dtype=torch.float32), )
class MLP(nn.Module): def __init__(self, dropout=0.0): super().__init__() self.net = nn.Sequential( nn.Linear(2, 32), nn.ReLU(), nn.Dropout(dropout), nn.Linear(32, 32), nn.ReLU(), nn.Dropout(dropout), nn.Linear(32, 1), )
def forward(self, x): return self.net(x)
def accuracy(logits, y): pred = (torch.sigmoid(logits) >= 0.5).float() return (pred == y).float().mean().item()
def train_case(name, dropout=0.0, weight_decay=0.0, epochs=120): torch.manual_seed(42) X_train, y_train, X_val, y_val = make_data() model = MLP(dropout=dropout) loss_fn = nn.BCEWithLogitsLoss() optimizer = torch.optim.AdamW(model.parameters(), lr=0.01, weight_decay=weight_decay) best_val = 10**9 patience = 0 best_epoch = 0 for epoch in range(1, epochs + 1): model.train() loss = loss_fn(model(X_train), y_train) optimizer.zero_grad() loss.backward() optimizer.step()
model.eval() with torch.no_grad(): val_loss = loss_fn(model(X_val), y_val).item() if val_loss < best_val: best_val = val_loss best_epoch = epoch patience = 0 else: patience += 1 if patience >= 20: break
model.eval() with torch.no_grad(): train_loss = loss_fn(model(X_train), y_train).item() val_loss = loss_fn(model(X_val), y_val).item() train_acc = accuracy(model(X_train), y_train) val_acc = accuracy(model(X_val), y_val) print( f"{name:<14} epochs={epoch:<3} best_epoch={best_epoch:<3} " f"train_loss={train_loss:.3f} val_loss={val_loss:.3f} " f"train_acc={train_acc:.3f} val_acc={val_acc:.3f}" )
print("regularization_lab")train_case("plain", dropout=0.0, weight_decay=0.0)train_case("dropout", dropout=0.25, weight_decay=0.0)train_case("weight_decay", dropout=0.0, weight_decay=0.05)train_case("both", dropout=0.25, weight_decay=0.05)运行:
python regularization_lab.py预期输出:
regularization_labplain epochs=87 best_epoch=67 train_loss=0.141 val_loss=0.155 train_acc=0.945 val_acc=0.931dropout epochs=101 best_epoch=81 train_loss=0.158 val_loss=0.162 train_acc=0.945 val_acc=0.943weight_decay epochs=87 best_epoch=67 train_loss=0.141 val_loss=0.154 train_acc=0.948 val_acc=0.931both epochs=101 best_epoch=81 train_loss=0.159 val_loss=0.162 train_acc=0.942 val_acc=0.949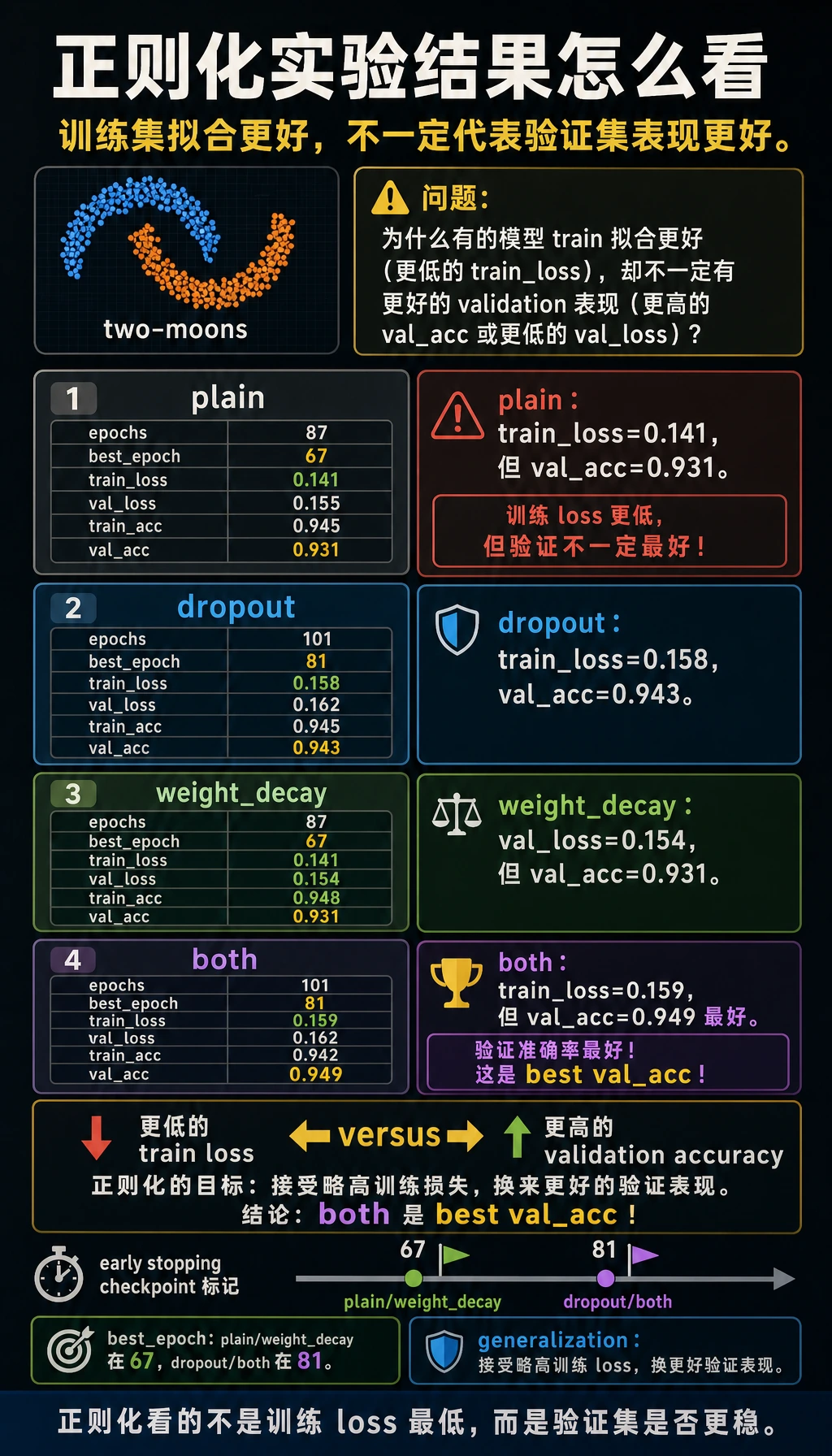
普通模型训练 loss 更低:
plain train_loss=0.141 val_acc=0.931但组合正则化模型验证准确率更高:
both train_loss=0.159 val_acc=0.949这就是正则化的重点。你可能接受稍差的训练拟合,换取更好的泛化。
学习正则化时,不要只保存最低训练 loss。要保存取舍关系:
- 简单
- 训练损失更低,验证准确率更低
- 正则化
- 训练损失略高,但验证准确率更好
- 决策
- 选择验证表现更好的模型
- 下一次探测
- 一次只改变 dropout 或 weight_decay
这里最重要的观念转变是:深度学习优化不是“让训练 loss 最小”,而是“让未来表现更可靠”。
Dropout
Section titled “Dropout”nn.Dropout(0.25) 会在训练时随机丢弃一部分激活:
nn.Linear(2, 32), nn.ReLU(), nn.Dropout(dropout)它让网络不要过度依赖某一个隐藏单元。通常放在隐藏层。执行 model.eval() 时,dropout 会自动关闭。
Weight Decay
Section titled “Weight Decay”weight decay 是由 optimizer 施加的 L2 风格正则化:
torch.optim.AdamW(model.parameters(), lr=0.01, weight_decay=0.05)它会抑制过大的权重。现代 PyTorch 工作中,AdamW 通常比旧式 Adam + L2 更清晰,因为 weight decay 与自适应梯度更新解耦。
Early Stopping
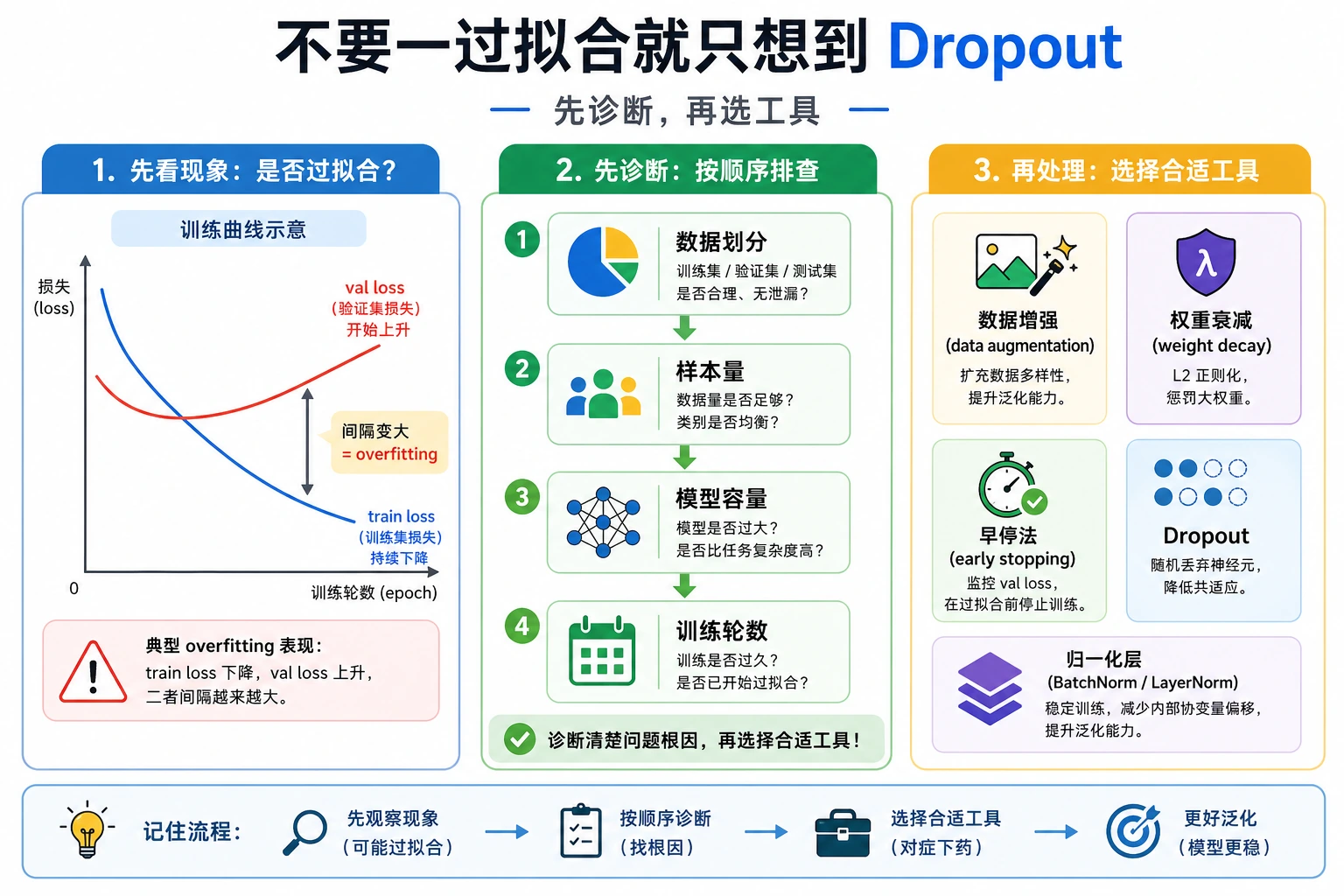
Section titled “Early Stopping”实验追踪了:
best_epoch=67early stopping 的意思是:保存验证集表现最好的 checkpoint,如果验证 loss 很久不提升,就停止训练。它可以防止模型在验证效果停止提升后继续训练太久。
| 问题 | 先做什么 |
|---|---|
| training loss 低,validation loss 高 | 加 weight decay 或 dropout |
| validation 先升后降 | early stopping |
| train 和 validation 都欠拟合 | 减少正则化或增强模型 |
| validation 噪声很大 | 降低 LR,增加数据,多 fold 平均 |
常见排查清单
Section titled “常见排查清单”| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| dropout 严重伤害训练 | dropout 太高或模型太小 | 降低 dropout |
| train 和 validation 都差 | 欠拟合 | 减少正则化 |
| validation 最佳 epoch 很早 | 训练太久 | 保存最佳 checkpoint |
| weight decay 没效果 | 值太小或模型本来简单 | 逐步增大 |
| eval 结果随机变化 | 忘记 model.eval() | 验证前切换 eval mode |
- 把 dropout 改成
0.1、0.5、0.7。 - 把 weight decay 改成
0.001、0.01、0.1。 - 每 20 个 epoch 打印 train 和 validation loss。
- 当
val_loss提升时保存最佳模型状态。 - 验证时移除
model.eval(),解释发生了什么。
参考实现与讲解
dropout=0.1比较温和,0.5较强但常见,0.7可能让模型欠拟合,因为训练时丢掉了太多信号。- 小的 weight decay 可能改善验证 loss;过大的 weight decay 会把权重压得太小,训练和验证表现都可能变差。
- 如果 train loss 下降而 validation loss 上升,通常是过拟合;如果两者都很高,可能是欠拟合或优化失败。
- 最佳 checkpoint 应该按 validation loss 选择,而不是直接用最后一个 epoch。这样可以避免保留已经开始过拟合的模型。
- 不调用
model.eval()时,dropout 和部分 normalization 层仍保持训练行为,验证结果会更噪或有偏差。
你能解释下面几点,就完成本节:
- 正则化关注验证表现,不只是训练 loss;
- dropout 会在训练时随机关闭隐藏激活;
- weight decay 会抑制大权重;
- early stopping 保留验证集最佳点;
- 过强正则化会导致欠拟合。