11.1.3 文本预处理
完成本节后,你将能够:
- 理解文本预处理到底在解决什么问题
- 掌握清洗、标准化、分词、停用词等常见步骤
- 写出一个可直接运行的预处理函数
- 明白为什么预处理不是越重越好,而是任务驱动
先建立一张地图
Section titled “先建立一张地图”文本预处理更适合按“任务 -> 信息 -> 操作”的顺序理解:
flowchart LR A["任务类型"] --> B["哪些信息重要"] B --> C["决定保留或清洗什么"] C --> D["形成预处理流程"]所以这节真正想解决的是:
- 为什么预处理不是越重越好
- 为什么同样一条文本,在不同任务里会有不同处理方式
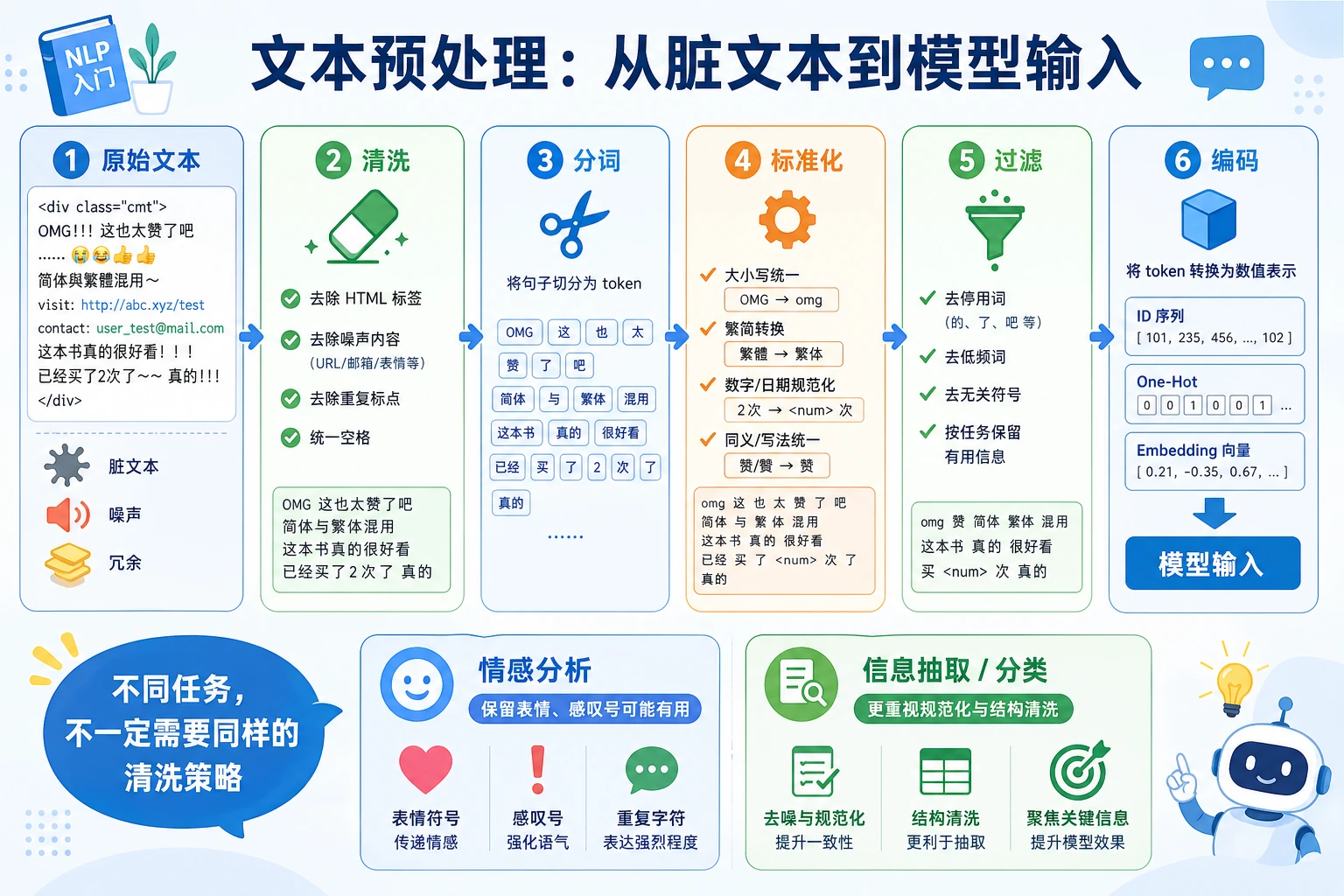
一、为什么文本要预处理?
Section titled “一、为什么文本要预处理?”原始文本通常很“脏”:
- 大小写不统一
- 标点很多
- 链接、数字、表情混在一起
- 同一个意思可能有很多写法
你可以把文本预处理想成“洗菜”:
- 不洗,模型很难直接下锅
- 洗过头,又可能把营养一起洗掉
所以预处理的核心不是“洗得越干净越好”,而是:
让文本更适合当前任务。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把文本预处理想成:
- 出门前整理背包
如果你去爬山,带的东西会和去办公室不一样。 同样地:
- 做情感分析时,否定词很重要
- 做检索时,关键词覆盖更重要
- 做命名实体识别时,大小写和格式信息可能很重要
所以预处理不是:
- 永远固定一套动作
而是:
- 看你准备去做什么任务
二、预处理最常见的几步
Section titled “二、预处理最常见的几步”| 步骤 | 常见作用 |
|---|---|
| 小写化 | 统一英文大小写 |
| 去链接 / 特殊符号 | 降低无意义噪声 |
| 去多余空格 | 统一格式 |
| 分词 | 拆成更小处理单位 |
| 停用词处理 | 去掉高频低信息词 |
| 数字 / 特殊模式标准化 | 统一某些规则模式 |
但记住:
- 这些步骤不是每次都全做
- 也不是做得越多越好
一个新人很值得先记住的判断表
Section titled “一个新人很值得先记住的判断表”| 任务 | 最值得优先保留的信息 |
|---|---|
| 情感分析 | 否定词、情绪词、程度词 |
| 检索 / RAG | 关键词、术语、数字、专有名词 |
| NER | 大小写、格式、专名边界 |
| 传统文本分类 | 稍重一点的清洗常常更常见 |
这个表不是绝对规则,但它能帮新人先建立一个很重要的直觉:
- 预处理是否合理,必须回到任务本身看
三、先跑一个最小预处理函数
Section titled “三、先跑一个最小预处理函数”下面我们先用英文示例,因为英文更容易用标准库直接演示。 思路对中文同样适用,只是中文通常要借助更专业的切分工具。
import re
stopwords = {"the", "is", "a", "an", "and", "to", "of", "in"}
def preprocess(text): text = text.lower() # 1. 小写化 text = re.sub(r"http\\S+", " ", text) # 2. 去链接 text = re.sub(r"[^a-z0-9\\s]", " ", text) # 3. 去特殊符号 text = re.sub(r"\\s+", " ", text).strip() # 4. 合并多余空格
tokens = text.split() # 5. 简单分词 tokens = [t for t in tokens if t not in stopwords] # 6. 去停用词 return tokens
sample = "The movie is AMAZING, and the ending is full of surprises!"print(preprocess(sample))预期输出:
['movie', 'amazing', 'ending', 'full', 'surprises']大小写、标点、常见停用词和多余符号被去掉了,真正携带情绪和主题信息的词被保留下来。
这个例子最想让你看到什么?
Section titled “这个例子最想让你看到什么?”文本预处理通常不是一个神秘大黑箱, 而是一连串很朴素的小步骤。
真正关键的是:
- 每一步为什么存在
- 它是否真的适合当前任务
再看一个“保留否定词”的最小对比
Section titled “再看一个“保留否定词”的最小对比”import re
stopwords_keep_not = {"the", "is", "a", "an", "and", "to", "of", "in"}stopwords_drop_not = {"the", "is", "a", "an", "and", "to", "of", "in", "not"}
def preprocess_with_stopwords(text, stopwords): text = text.lower() text = re.sub(r"[^a-z0-9\\s]", " ", text) text = re.sub(r"\\s+", " ", text).strip() tokens = text.split() return [t for t in tokens if t not in stopwords]
sample = "This movie is not good"print("keep_not :", preprocess_with_stopwords(sample, stopwords_keep_not))print("drop_not :", preprocess_with_stopwords(sample, stopwords_drop_not))预期输出:
keep_not : ['this', 'movie', 'not', 'good']drop_not : ['this', 'movie', 'good']第二个结果把 not 去掉了,意思会被悄悄反转。这正是停用词规则必须根据任务选择的原因。
这个例子很适合初学者,因为它会直接让你看到:
- 一个看起来“不重要”的词
- 其实可能正是决定语义方向的关键
四、小写化为什么常见?
Section titled “四、小写化为什么常见?”在英文里:
AppleappleAPPLE
很多任务里可能都想当成同一个词。
但不是永远都该做
Section titled “但不是永远都该做”例如:
- 命名实体识别
- 品牌名识别
大小写本身可能就是重要信息。
所以要记住:
- 预处理一定要和任务绑定看
五、分词为什么这么重要?
Section titled “五、分词为什么这么重要?”因为模型不直接处理“整句原文”
Section titled “因为模型不直接处理“整句原文””它通常需要更小单位:
- 词
- 子词
- 字
英文和中文情况不同
Section titled “英文和中文情况不同”英文天然有空格,
简单场景里可以直接 split()。
中文没有天然空格, 分词问题会更复杂。
例如:
- “自然语言处理”
到底切成:
- 自然语言处理
还是:
- 自然 / 语言 / 处理
会直接影响后续表示和模型效果。
一个简单中文切分意识
Section titled “一个简单中文切分意识”即便现在不引入专业分词工具,你也要先建立一个判断:
中文文本不是天然就有词边界。
六、停用词为什么有用,又为什么危险?
Section titled “六、停用词为什么有用,又为什么危险?”高频但区分度弱的词,例如:
- the
- is
- and
在很多传统模型里确实容易带来噪声。
某些看似不起眼的词,可能非常关键。
例如:
not good
如果把 not 去掉,语义就翻转了。
所以停用词不是“必删项”
Section titled “所以停用词不是“必删项””更合理的想法是:
- 它是一个可选操作
- 是否使用取决于任务
七、再看一个稍完整点的小练习
Section titled “七、再看一个稍完整点的小练习”import re
stopwords = {"the", "is", "a", "an", "and", "to", "of", "in", "this"}
def preprocess(text): text = text.lower() text = re.sub(r"http\\S+", " ", text) text = re.sub(r"[^a-z0-9\\s]", " ", text) text = re.sub(r"\\s+", " ", text).strip() tokens = text.split() tokens = [t for t in tokens if t not in stopwords] return tokens
texts = [ "This course is easy to follow!", "The examples are clear and practical.", "I love the hands-on exercises in this class.",]
for text in texts: print("原文 :", text) print("处理后 :", preprocess(text)) print("-" * 30)预期输出:
原文 : This course is easy to follow!处理后 : ['course', 'easy', 'follow']------------------------------原文 : The examples are clear and practical.处理后 : ['examples', 'are', 'clear', 'practical']------------------------------原文 : I love the hands-on exercises in this class.处理后 : ['i', 'love', 'hands', 'on', 'exercises', 'class']------------------------------把这种前后对照当成习惯。如果重要词消失了,先调整规则,再去训练模型。
这个例子真正值得关注什么?
Section titled “这个例子真正值得关注什么?”你要看:
- 哪些信息被保留了
- 哪些信息被删除了
- 删除是否符合任务需要
这比死记“预处理步骤表”更重要。
八、传统模型和预训练模型的预处理思路为什么不同?
Section titled “八、传统模型和预训练模型的预处理思路为什么不同?”传统机器学习
Section titled “传统机器学习”通常更依赖人工预处理,因为模型本身比较浅, 对噪声比较敏感。
预训练模型 / 大模型
Section titled “预训练模型 / 大模型”很多时候更依赖模型自带 tokenizer, 如果你在外面过度清洗,反而可能:
- 破坏原始结构
- 丢掉模型能利用的信息
一个很重要的判断
Section titled “一个很重要的判断”不是所有 NLP 时代都用同一套预处理策略。
第一次做 NLP 项目时,最稳的默认顺序
Section titled “第一次做 NLP 项目时,最稳的默认顺序”更稳的顺序通常是:
- 先想清楚任务是什么
- 先写一个很轻的 baseline 预处理
- 先看输出里丢掉了什么信息
- 再决定要不要继续加规则
这样会比一开始就堆很多正则和规则更容易看清问题。
九、初学者常见误区
Section titled “九、初学者常见误区”觉得预处理越多越高级
Section titled “觉得预处理越多越高级”不对。 删太多信息,效果反而可能更差。
不区分任务就套同一套规则
Section titled “不区分任务就套同一套规则”文本分类、检索、NER、RAG 的预处理策略常常不同。
中文也直接 split()
Section titled “中文也直接 split()”在很多任务里通常不够。
如果把它做成项目,最值得展示什么
Section titled “如果把它做成项目,最值得展示什么”最值得展示的通常不是:
- 我用了多少正则
而是:
- 原始文本长什么样
- 处理后文本长什么样
- 哪些信息被保留
- 哪些信息被删掉
- 这套处理为什么适合当前任务
这样别人会更容易看出:
- 你理解的是任务需求
- 不只是机械清洗文本
学完这一页,至少保留这张证据卡:
- 原始文本
- 清洗或分词前的原始示例
- 处理后文本
- 清理后的文本、tokens、归一化说明和已移除项
- 任务边界
- 分类、抽取、检索、生成或 QA 输出
- 失败检查
- 含义丢失、分词不佳、语言问题或标签歧义
- 期望产出
- 前后对比文本样本,以及 token 或表示输出
文本预处理最重要的不是“洗干净”,而是:
围绕任务,把文本整理成更适合当前模型处理的形式。
下一节我们会继续往前走,解决另一个关键问题:
文本怎么表示成数字?
这节最该带走什么
Section titled “这节最该带走什么”- 文本预处理不是固定模板,而是任务驱动选择
- 删掉的信息和保留的信息同样重要
- 第一次做项目时,先做轻量 baseline,通常比重度清洗更稳
- 给
preprocess()再加一个数字替换逻辑,把所有数字替换成<num>。 - 把
not加进停用词,再观察情感句子会发生什么问题。 - 自己找 5 条短评论,跑一遍预处理,看看哪些信息被保留、哪些被删掉。
- 想一想:在 NER 场景里,小写化为什么可能反而有害?
参考实现与讲解
- 数字替换规则可以把连续数字替换成
<num>,但要保留前后对比,因为日期、价格和 ID 可能需要不同处理。 - 把
not加进 stopwords 往往会伤害情感任务,因为not good清洗后会变得太像good。 - 跑 5 条评论时,对比原文、清洗后文本和 token。最好的观察不是“越短越好”,而是有用证据是否还在。
- 小写化可能伤害 NER,因为人名、产品代码、缩写和地点常常依赖大小写作为证据。