8.3.3 LangChain 基础
- 理解 LangChain 这种链式抽象为什么会自然出现
- 看懂 Prompt、模型、解析器、检索器在链中的位置
- 用一个最小例子理解“上一步输出喂给下一步”的核心味道
- 理解它为什么很适合做原型和线性工作流
先建立一张地图
Section titled “先建立一张地图”LangChain 这节最适合新人的理解顺序不是“先学框架 API”,而是先看清:
flowchart LR A["真实应用不只调一次模型"] --> B["拆成多个小步骤"] B --> C["每步都有清楚输入输出"] C --> D["再按顺序串起来"]所以这节真正想解决的是:
- 为什么链式抽象会自然出现
- 它到底是在替你整理什么
一、为什么需要“链”这种抽象?
Section titled “一、为什么需要“链”这种抽象?”因为真实应用通常不只调一次模型
Section titled “因为真实应用通常不只调一次模型”比如你想做一个小问答系统,可能就已经有这些步骤:
- 清理用户 查询
- 检索文档
- 拼 prompt
- 调模型
- 格式化输出
如果你全手写在一个函数里,虽然也能跑,但很快会变得:
- 不清楚
- 不可复用
- 不好调试
链式抽象到底在做什么?
Section titled “链式抽象到底在做什么?”它在说:
把每一步都做成一个职责明确的小组件,然后按顺序串起来。
这就是 LangChain 最核心的味道。
二、一个最小链式示例
Section titled “二、一个最小链式示例”class SimpleChain: def __init__(self, steps): self.steps = steps
def run(self, value): for step in self.steps: value = step(value) return value
def normalize_query(text): return text.strip().lower()
def retrieve_docs(query): if "退款" in query: return {"query": query, "docs": ["课程购买后 7 天内可退款。"]} return {"query": query, "docs": []}
def format_answer(payload): if payload["docs"]: return f"根据资料:{payload['docs'][0]}" return "没有找到相关资料。"
chain = SimpleChain([ normalize_query, retrieve_docs, format_answer])
print(chain.run(" 退款政策是什么? "))预期输出:
根据资料:课程购买后 7 天内可退款。这段代码在教什么?
Section titled “这段代码在教什么?”它已经在教你 LangChain 最核心的一件事:
每一步只关心自己的输入输出,整个系统通过串联完成任务。
这就是链式应用最核心的价值。
三、Prompt 在链里扮演什么角色?
Section titled “三、Prompt 在链里扮演什么角色?”Prompt 不是“附属文案”,而是一个组件
Section titled “Prompt 不是“附属文案”,而是一个组件”在很多链路里,Prompt 本身就是中间的一步:
- 输入 查询
- 生成更清晰的提示模板
一个简单示意
Section titled “一个简单示意”def build_prompt(payload): docs = payload["docs"] query = payload["query"] return f"请根据以下资料回答问题:资料={docs},问题={query}"
payload = {"query": "退款政策是什么", "docs": ["课程购买后 7 天内可退款。"]}print(build_prompt(payload))预期输出:
请根据以下资料回答问题:资料=['课程购买后 7 天内可退款。'],问题=退款政策是什么这个例子在提醒你:
Prompt 也可以被看作链里的一个中间变换节点。
四、再加上一个“模型”步骤
Section titled “四、再加上一个“模型”步骤”为了保证示例能离线运行,我们继续用 mock model。
def mock_llm(prompt): return f"模型输出:{prompt}"
chain = SimpleChain([ normalize_query, retrieve_docs, build_prompt, mock_llm])
print(chain.run("退款政策是什么?"))预期输出:
模型输出:请根据以下资料回答问题:资料=['课程购买后 7 天内可退款。'],问题=退款政策是什么?这一步最关键的收获
Section titled “这一步最关键的收获”你会开始看到:
- 检索器
- prompt builder
- model
其实都是链上的不同节点。
这也是为什么 LangChain 会给人一种“组件拼装框架”的感觉。
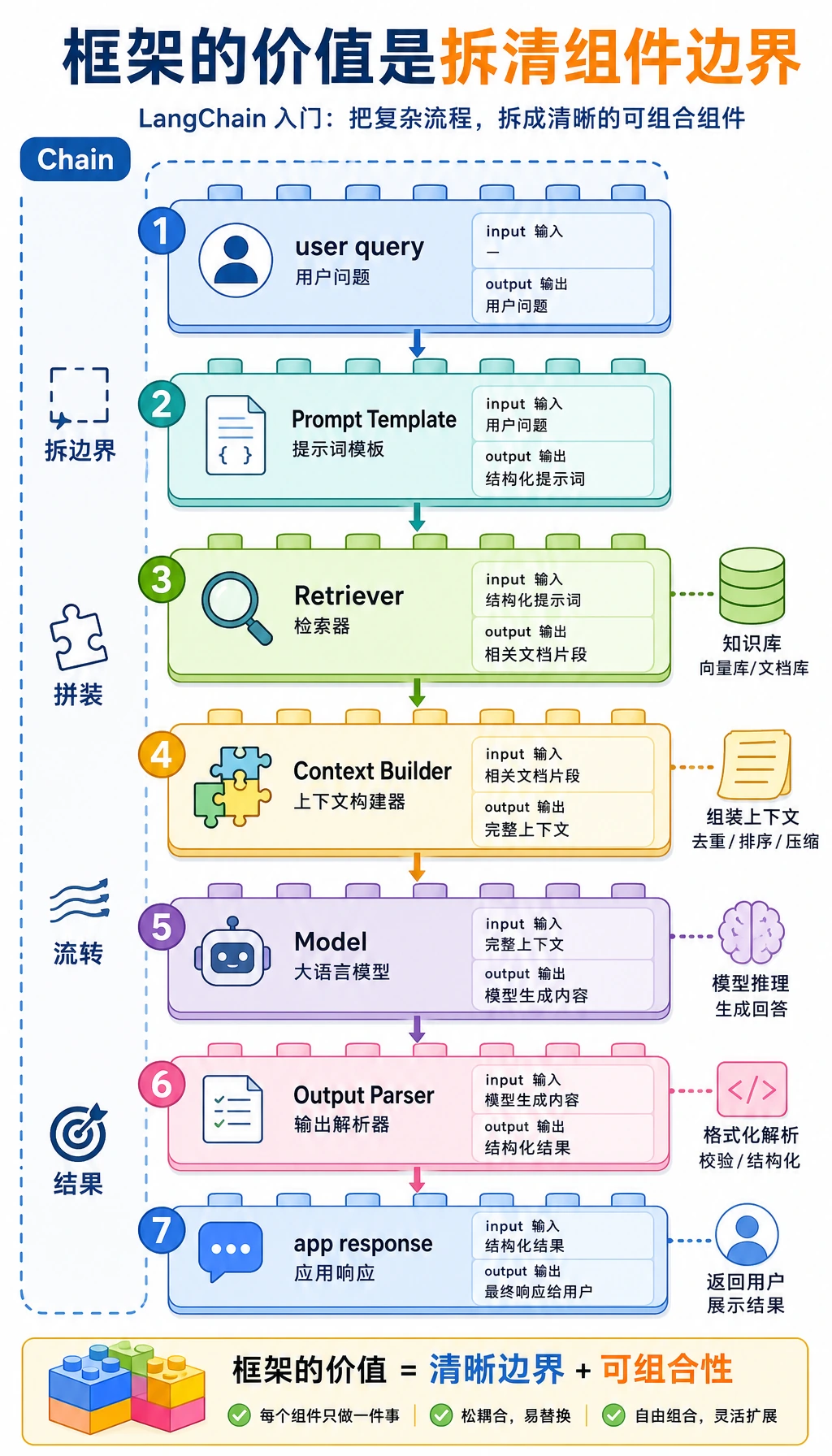
五、输出解析器为什么也重要?
Section titled “五、输出解析器为什么也重要?”很多人只关注输入 prompt 和模型输出,忽略了:
模型输出后,系统还常常要继续做结构化处理。
例如:
- 只取一部分字段
- 转成 JSON
- 映射到前端展示格式
一个最小示例
Section titled “一个最小示例”def output_parser(text): return { "answer": text.replace("模型输出:", ""), "ok": True }
chain = SimpleChain([ normalize_query, retrieve_docs, build_prompt, mock_llm, output_parser])
print(chain.run("退款政策是什么?"))预期输出:
{'answer': "请根据以下资料回答问题:资料=['课程购买后 7 天内可退款。'],问题=退款政策是什么?", 'ok': True}这一步会让你更清楚地意识到:
LangChain 的真正价值,常常在“把不同组件的边界拆清楚”。
六、为什么它特别适合做原型?
Section titled “六、为什么它特别适合做原型?”因为很多早期 LLM 应用都很像:
- 一条比较线性的流程
- 几个组件依次执行
例如:
- 清理 查询
- 检索
- 拼 prompt
- 调模型
- 解析结果
这正是链式抽象最舒服的场景。
七、什么时候它会开始吃力?
Section titled “七、什么时候它会开始吃力?”如果你的流程开始变成:
- 如果检索失败就改写 查询 再查一次
- 如果答案不够稳就让 审核者 再检查
- 某些请求要走工具,某些请求不要
这种情况下,“一条直链”就会越来越勉强。
也就是说:
当系统开始有明显状态分支和回路时,链式抽象就可能不够了。
这也是为什么后面会需要 LangGraph 这种更图式的框架。
什么时候先不用框架?
Section titled “什么时候先不用框架?”LangChain 很适合原型和线性链路,但它不是每个项目的第一步。下面这些情况,先用普通函数把流程写清楚,往往更稳:
| 情况 | 为什么先不用框架 |
|---|---|
| 只有一次模型调用 | 框架带来的抽象成本可能大于收益 |
| 你还没确定输入输出 | 先把任务契约和测试样本定下来 |
| 需要精细控制重试、缓存或日志 | 直接写代码更容易看清每一步 |
| 团队还在学习底层链路 | 先理解 tokenizer、retriever、prompt、model、parser 的数据流 |
一个实用判断是:当你已经能用普通函数跑通流程,并且开始明显感觉“组件边界、复用和追踪变乱”时,再引入框架会更自然。
八、一个很重要的工程提醒
Section titled “八、一个很重要的工程提醒”很多人学 LangChain 时最容易犯的错是:
- 一开始就背一堆类名和接口
但更稳的方式通常是:
- 先理解链式抽象在解决什么问题
- 再去看具体 API
不然很容易变成:
- 会写框架代码
- 但不知道为什么要这么组织
新人第一次用 LangChain 时最稳的方式
Section titled “新人第一次用 LangChain 时最稳的方式”更稳的顺序通常是:
- 先只做一条线性链路
- 先把每个节点输入输出打印清楚
- 再去加检索、解析器和更复杂组件
- 最后才考虑更复杂的图式工作流
学完这一页,至少保留这张证据卡:
- 请求
- 输入、状态、工具/上下文,以及期望输出契约
- 已验证输出
- parser / schema 或业务规则检查的结果
- 追踪记录
- 模型调用、tool/function 调用、文档解析或对话状态
- 失败检查
- 格式无效、字段缺失、状态过时或工具错误
- 下一步动作
- Prompt、schema、状态、API 或解析改进
这一节最重要的不是记住某个具体类,而是理解:
LangChain 的核心价值,在于把“prompt、检索、模型、解析”这些高频组件组织成更清晰的线性工作流。
只要这个链式思维建立起来,后面你看真实框架接口时就会顺很多。
这节最该带走什么
Section titled “这节最该带走什么”- LangChain 不是在替代模型,而是在整理多步应用
- 先理解链,再学框架,会比直接记 API 更稳
- 它特别适合原型和线性工作流,但也不是所有复杂系统的终点
- 给这个
SimpleChain再加一步,把 查询 改写得更适合检索。 - 用自己的话解释:为什么 Prompt 也可以被看作链里的一个组件?
- 想一想:当流程开始有复杂分支时,为什么链式抽象会吃力?
- 用自己的话说明:LangChain 最适合解决什么形状的问题?
参考实现与讲解
- 查询改写步骤可以统一同义词,把原始问题变成更适合检索的表达,同时保留原意。
- Prompt 也是组件,因为它把输入转换成指令,并约束输出形状。
- 当分支、重试、状态决策和工具循环变多时,线性 chain 会变得别扭。
- LangChain 更适合由 Prompt、retriever、tool、parser 等组件组成、流程相对可预测的 LLM 工作流。