2.1.6 数据结构
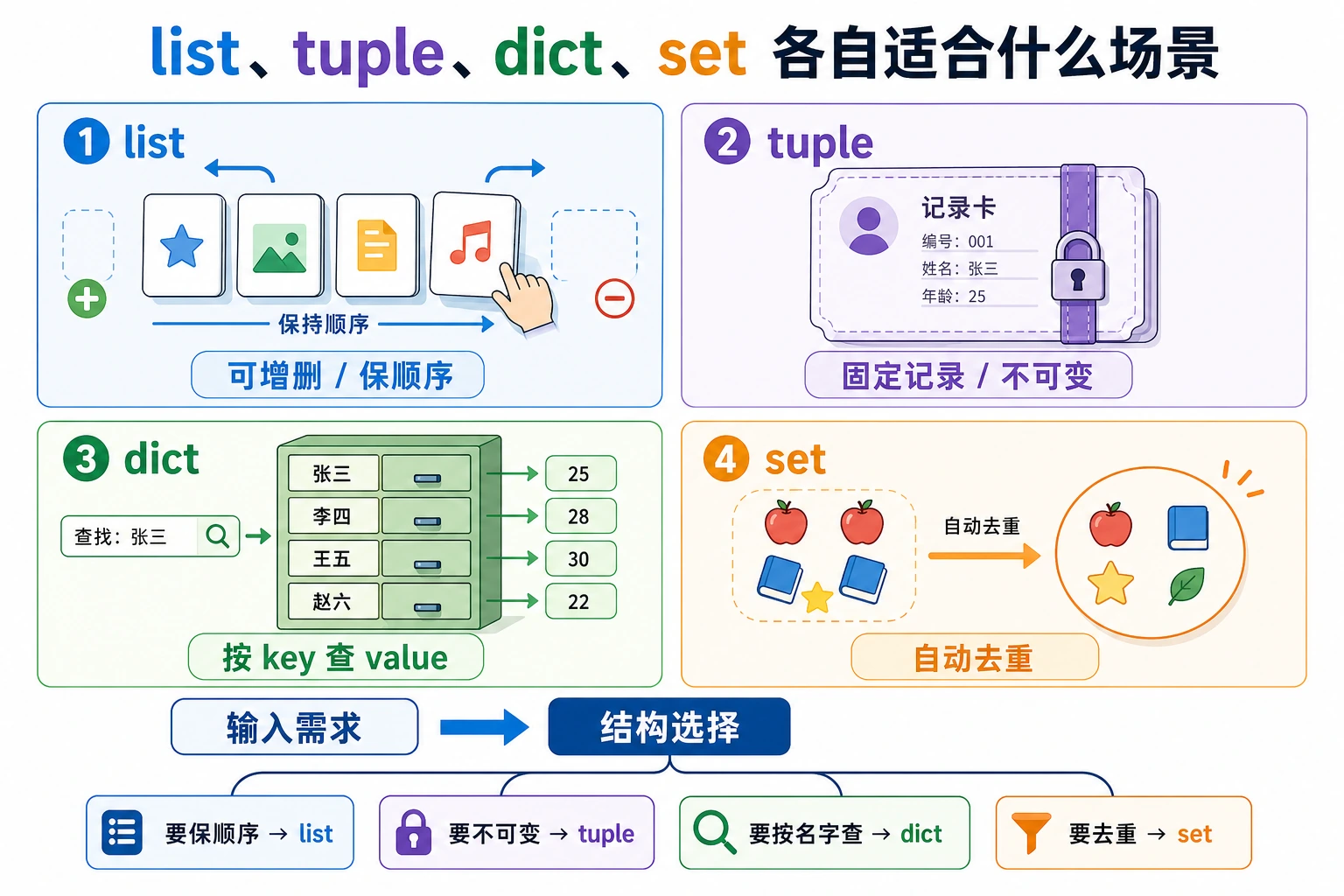
这一节学习如何组织一组数据。列表、元组、字典和集合会贯穿后面的爬虫、数据分析、机器学习样本处理和 API 返回结果解析,重点是知道每种结构适合存什么、什么时候该用哪一种。
- 掌握列表(list)的创建和常用操作
- 理解元组(tuple)的特点和使用场景
- 掌握字典(dict)的键值对操作
- 了解集合(set)的去重和集合运算
- 能根据场景选择合适的数据结构
为什么需要数据结构?
Section titled “为什么需要数据结构?”到目前为止,你学的变量一次只能存一个值。但在真实场景中,你经常需要处理一组数据:
- 100 次 API 响应延迟
- 一个模型的所有参数
- 用户的个人信息(姓名、年龄、邮箱……)
数据结构就是用来组织和存储多个数据的容器。
Python 有 4 种内置数据结构。最简单的选择方法是:
| 如果你需要…… | 优先使用 |
|---|---|
| 一组有顺序、经常会改的数据 | 列表 [] |
| 一组有顺序、希望固定不改的数据 | 元组 () |
| 按名字或 ID 查找值 | 字典 {key: value} |
| 去重,或比较两组数据 | 集合 {item} |
再记住它们的核心属性:
- 列表:有序、可变、允许重复。
- 元组:有序、不可变、允许重复。
- 字典:按插入顺序保存、可变、键不能重复。
- 集合:无序、可变、会自动去重。
列表(list)—— 最常用的数据结构
Section titled “列表(list)—— 最常用的数据结构”列表就像一个可以伸缩的柜子,你可以往里面放任何东西,也可以随时增删改。
# 创建列表latencies_ms = [120, 95, 240, 180, 310]features = ["登录 API", "RAG 演示", "图表视图"]mixed = [1, "hello", 3.14, True] # 可以混合类型(但不推荐)empty = [] # 空列表
print(type(latencies_ms)) # <class 'list'>print(len(latencies_ms)) # 5访问元素(索引)
Section titled “访问元素(索引)”service_queue = ["登录 API", "搜索 API", "Worker", "仪表盘", "文档站点"]# 0 1 2 3 4# -5 -4 -3 -2 -1
print(service_queue[0]) # 登录 API(第一个服务)print(service_queue[2]) # Worker(第三个服务)print(service_queue[-1]) # 文档站点(最后一个服务)print(service_queue[-2]) # 仪表盘(倒数第二个服务)numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(numbers[2:5]) # [2, 3, 4](索引 2 到 4)print(numbers[:3]) # [0, 1, 2](前 3 个)print(numbers[7:]) # [7, 8, 9](从索引 7 到末尾)print(numbers[::2]) # [0, 2, 4, 6, 8](每隔一个取一个)print(numbers[::-1]) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0](反转)latencies_ms = [120, 95, 240, 180, 310]
# 修改单个元素latencies_ms[2] = 210print(latencies_ms) # [120, 95, 210, 180, 310]
# 修改多个元素(通过切片)latencies_ms[1:3] = [100, 180]print(latencies_ms) # [120, 100, 180, 180, 310]tasks = ["构建登录表单", "编写 API 测试"]
# 在末尾添加tasks.append("补充错误状态")print(tasks) # ['构建登录表单', '编写 API 测试', '补充错误状态']
# 在指定位置插入tasks.insert(1, "评审认证流程")print(tasks) # ['构建登录表单', '评审认证流程', '编写 API 测试', '补充错误状态']
# 添加多个元素tasks.extend(["更新 README", "录制演示"])print(tasks) # ['构建登录表单', '评审认证流程', '编写 API 测试', '补充错误状态', '更新 README', '录制演示']tasks = ["构建登录表单", "编写 API 测试", "补充错误状态", "评审认证流程", "录制演示"]
# 按值删除(删除第一个匹配项)tasks.remove("补充错误状态")print(tasks) # ['构建登录表单', '编写 API 测试', '评审认证流程', '录制演示']
# 按索引删除deleted = tasks.pop(1) # 删除索引 1 的元素,并返回它print(deleted) # 编写 API 测试print(tasks) # ['构建登录表单', '评审认证流程', '录制演示']
# 删除最后一个last = tasks.pop()print(last) # 录制演示
# 按索引删除(不需要返回值)del tasks[0]print(tasks) # ['评审认证流程']列表常用操作
Section titled “列表常用操作”numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5]
# 排序numbers.sort()print(numbers) # [1, 1, 2, 3, 4, 5, 5, 6, 9]
# 降序排序numbers.sort(reverse=True)print(numbers) # [9, 6, 5, 5, 4, 3, 2, 1, 1]
# 不修改原列表的排序original = [3, 1, 4, 1, 5]sorted_list = sorted(original)print(original) # [3, 1, 4, 1, 5](原列表不变)print(sorted_list) # [1, 1, 3, 4, 5]
# 反转numbers = [1, 2, 3, 4, 5]numbers.reverse()print(numbers) # [5, 4, 3, 2, 1]
# 查找print(numbers.index(3)) # 2(元素 3 的索引)print(numbers.count(5)) # 1(元素 5 出现的次数)print(3 in numbers) # True
# 统计latencies_ms = [120, 95, 240, 180, 310]print(len(latencies_ms)) # 5print(sum(latencies_ms)) # 945print(max(latencies_ms)) # 310print(min(latencies_ms)) # 95print(sum(latencies_ms) / len(latencies_ms)) # 189.0(平均延迟)列表推导式(非常 Pythonic!)
Section titled “列表推导式(非常 Pythonic!)”列表推导式是创建新列表的简洁方式:
# 传统方式squares = []for i in range(1, 6): squares.append(i ** 2)print(squares) # [1, 4, 9, 16, 25]
# 列表推导式(一行搞定!)squares = [i ** 2 for i in range(1, 6)]print(squares) # [1, 4, 9, 16, 25]
# 带条件的列表推导式even_squares = [i ** 2 for i in range(1, 11) if i % 2 == 0]print(even_squares) # [4, 16, 36, 64, 100]
# 实际应用:规范化功能 slugraw_slugs = [" Login API ", "RAG DEMO", " Chart View "]clean_slugs = [slug.strip().lower().replace(" ", "-") for slug in raw_slugs]print(clean_slugs) # ['login-api', 'rag-demo', 'chart-view']元组(tuple)—— 不可变的列表
Section titled “元组(tuple)—— 不可变的列表”元组和列表几乎一样,唯一的区别是:元组创建后不能修改。
# 用圆括号创建point = (3, 4)colors = ("红", "绿", "蓝")single = (42,) # 只有一个元素时,必须加逗号!empty = ()
# 其实圆括号可以省略coordinates = 3, 4 # 也是元组print(type(coordinates)) # <class 'tuple'>colors = ("红", "绿", "蓝", "黄", "紫")
# 访问(和列表一样)print(colors[0]) # 红print(colors[-1]) # 紫print(colors[1:3]) # ('绿', '蓝')
# 遍历for color in colors: print(color)
# 查找print(len(colors)) # 5print("红" in colors) # Trueprint(colors.count("红")) # 1print(colors.index("蓝")) # 2
# 但是不能修改!# colors[0] = "黑" # 报错!TypeError: 'tuple' object does not support item assignment# 把元组的值分别赋给多个变量point = (10, 20)x, y = pointprint(f"x={x}, y={y}") # x=10, y=20
# 函数返回多个值时,实际返回的是元组def get_task_and_hours(): return "登录 API", 8
task, hours = get_task_and_hours()print(f"{task}, {hours} 小时") # 登录 API, 8 小时
# 用 * 收集多余的值first, *rest = [1, 2, 3, 4, 5]print(first) # 1print(rest) # [2, 3, 4, 5]什么时候用元组?
Section titled “什么时候用元组?”- 数据不应该被修改时(比如坐标、颜色 RGB 值)
- 字典的键(列表不能做字典的键,元组可以)
- 函数返回多个值时
字典(dict)—— 键值对存储
Section titled “字典(dict)—— 键值对存储”字典是 Python 中最重要的数据结构之一。它用键(key) 来查找值(value),就像真实的字典用单词查释义一样。
# 用花括号创建task = { "name": "登录 API", "owner": "Mina", "status": "进行中", "hours": [2, 3, 3]}
# 空字典empty = {}
# 用 dict() 创建config = dict(learning_rate=0.001, epochs=100, batch_size=32)print(config) # {'learning_rate': 0.001, 'epochs': 100, 'batch_size': 32}
print(type(task)) # <class 'dict'>task = {"name": "登录 API", "owner": "Mina", "status": "进行中"}
# 方法 1:用 [] 访问print(task["name"]) # 登录 API# print(task["deadline"]) # 报错!KeyError: 'deadline'
# 方法 2:用 .get() 访问(更安全)print(task.get("owner")) # Minaprint(task.get("deadline")) # None(不存在时返回 None,不会报错)print(task.get("deadline", "未排期")) # 未排期(不存在时返回默认值)task = {"name": "登录 API", "status": "待办"}
# 添加新键值对task["owner"] = "Mina"task["repo"] = "portfolio-api"
# 修改已有的值task["status"] = "进行中"
print(task)# {'name': '登录 API', 'status': '进行中', 'owner': 'Mina', 'repo': 'portfolio-api'}
# 批量更新task.update({"status": "已完成", "hours": 8})print(task)task = {"name": "登录 API", "status": "已完成", "owner": "Mina"}
# 删除指定键del task["owner"]print(task) # {'name': '登录 API', 'status': '已完成'}
# pop:删除并返回值status = task.pop("status")print(status) # 已完成print(task) # {'name': '登录 API'}task_hours = {"登录 API": 8, "RAG 演示": 12, "图表视图": 5}
# 遍历键for task in task_hours: print(task)
# 遍历值for hours in task_hours.values(): print(hours)
# 遍历键值对(最常用)for task, hours in task_hours.items(): print(f"{task}: {hours} 小时")
# 输出:# 登录 API: 8 小时# RAG 演示: 12 小时# 图表视图: 5 小时# 创建一个数字到平方的映射squares = {x: x**2 for x in range(1, 6)}print(squares) # {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# 过滤字典task_hours = {"登录 API": 8, "Bug 修复": 3, "RAG 演示": 12, "文档": 2}large_tasks = {name: hours for name, hours in task_hours.items() if hours >= 8}print(large_tasks) # {'登录 API': 8, 'RAG 演示': 12}实际案例:统计字符出现次数
Section titled “实际案例:统计字符出现次数”text = "hello world"char_count = {}
for char in text: if char in char_count: char_count[char] += 1 else: char_count[char] = 1
print(char_count)# {'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1}集合(set)—— 去重利器
Section titled “集合(set)—— 去重利器”集合是无序且不重复的元素集合。
# 用花括号创建task_tags = {"api", "ui", "testing", "api"} # 重复的会自动去掉print(task_tags) # {'testing', 'ui', 'api'}(顺序可能不同)
# 从列表创建(去重!)modules = ["api", "api", "ui", "worker", "ui", "db"]unique_modules = set(modules)print(unique_modules) # {'api', 'db', 'ui', 'worker'}(顺序可能不同)
# 注意:空集合要用 set(),不能用 {}empty_set = set() # 空集合empty_dict = {} # 这是空字典!
print(type(task_tags)) # <class 'set'>a = {1, 2, 3, 4, 5}b = {4, 5, 6, 7, 8}
# 交集(两个都有的)print(a & b) # {4, 5}print(a.intersection(b))
# 并集(合在一起,去重)print(a | b) # {1, 2, 3, 4, 5, 6, 7, 8}print(a.union(b))
# 差集(a 有但 b 没有的)print(a - b) # {1, 2, 3}print(a.difference(b))
# 对称差集(各自独有的)print(a ^ b) # {1, 2, 3, 6, 7, 8}# 场景:找出同时涉及前端和后端的任务frontend_tasks = {"登录界面", "图表视图", "设置页", "主题切换"}backend_tasks = {"登录 API", "图表视图", "审计日志", "设置页"}
both = frontend_tasks & backend_tasksprint(f"同时涉及两端的任务: {sorted(both)}")
only_frontend = frontend_tasks - backend_tasksprint(f"只涉及前端的任务: {sorted(only_frontend)}")
all_tasks = frontend_tasks | backend_tasksprint(f"所有相关任务: {sorted(all_tasks)}")数据结构选择指南
Section titled “数据结构选择指南”| 需求 | 推荐 | 原因 |
|---|---|---|
| 有序集合,需要增删改 | 列表 | 最通用的容器 |
| 数据不应被修改 | 元组 | 不可变,更安全 |
| 通过键查找值 | 字典 | O(1) 查找速度 |
| 去重 | 集合 | 自动去重 |
| 统计出现次数 | 字典 | 键为元素,值为计数 |
| 检查元素是否存在 | 集合/字典 | 比列表快得多 |
练习 1:API 延迟统计
Section titled “练习 1:API 延迟统计”latencies_ms = [120, 95, 240, 180, 310, 150, 88, 205, 260, 170]
# 1. 计算最高延迟、最低延迟、平均延迟# 2. 找出所有超过 200 ms 的延迟(用列表推导式)# 3. 把延迟从高到低排序练习 2:服务负责人目录
Section titled “练习 2:服务负责人目录”用字典实现一个简单的服务负责人目录:
owners = {}
# 1. 添加 3 个服务(服务名 → 负责人邮箱)# 2. 查找某个服务负责人的邮箱# 3. 修改某个服务负责人的邮箱# 4. 删除一个服务# 5. 打印所有服务负责人练习 3:事件词频统计
Section titled “练习 3:事件词频统计”text = "api error api timeout worker error api"
# 统计每个事件词出现的次数# 提示:先 split() 分割成列表,再用字典统计练习 4:列表去重(保持顺序)
Section titled “练习 4:列表去重(保持顺序)”numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# 去除重复元素,但保持原来的顺序# 期望输出: [3, 1, 4, 5, 9, 2, 6]# 提示:用集合记录已出现的元素参考实现与讲解
- 延迟统计结果是最高
310、最低88、平均181.8。超过200ms 的延迟可以是[240, 310, 205, 260],降序排列应以[310, 260, 240, 205, ...]开头。 - 服务负责人目录应按 key 增删改查,例如
owners["登录 API"] = "[email protected]"。 - 示例事件词频中,
api应为3,error应为2,timeout和worker各出现一次。 - 保持顺序去重的结果应为
[3, 1, 4, 5, 9, 2, 6],做法是用seen集合配合结果列表。 - 需要顺序时选列表,需要查找时选字典,需要成员判断或去重时选集合,固定记录可选元组。
学完这一页,至少保留这张证据卡:
- 概念
- 变量、类型、运算符、输入/输出、分支、循环、结构、函数或模块
- 代码
- 用于说明该概念的最小可运行 Python 代码片段
- 输出
- 打印值、类型、分支结果、循环 trace,或返回值
- 失败检查
- 类型不匹配、缩进错误、越界、可变数据或导入路径问题
- 期望产出
- 代码和打印结果,证明概念可行
| 数据结构 | 创建方式 | 特点 | 常用场景 |
|---|---|---|---|
| 列表 | [1, 2, 3] | 有序、可变、可重复 | 存储一组同类数据 |
| 元组 | (1, 2, 3) | 有序、不可变 | 坐标、返回多个值 |
| 字典 | {"a": 1} | 键值对、键不可重复 | 配置、映射关系 |
| 集合 | {1, 2, 3} | 无序、不重复 | 去重、集合运算 |