E.B.2 迭代器与生成器进阶
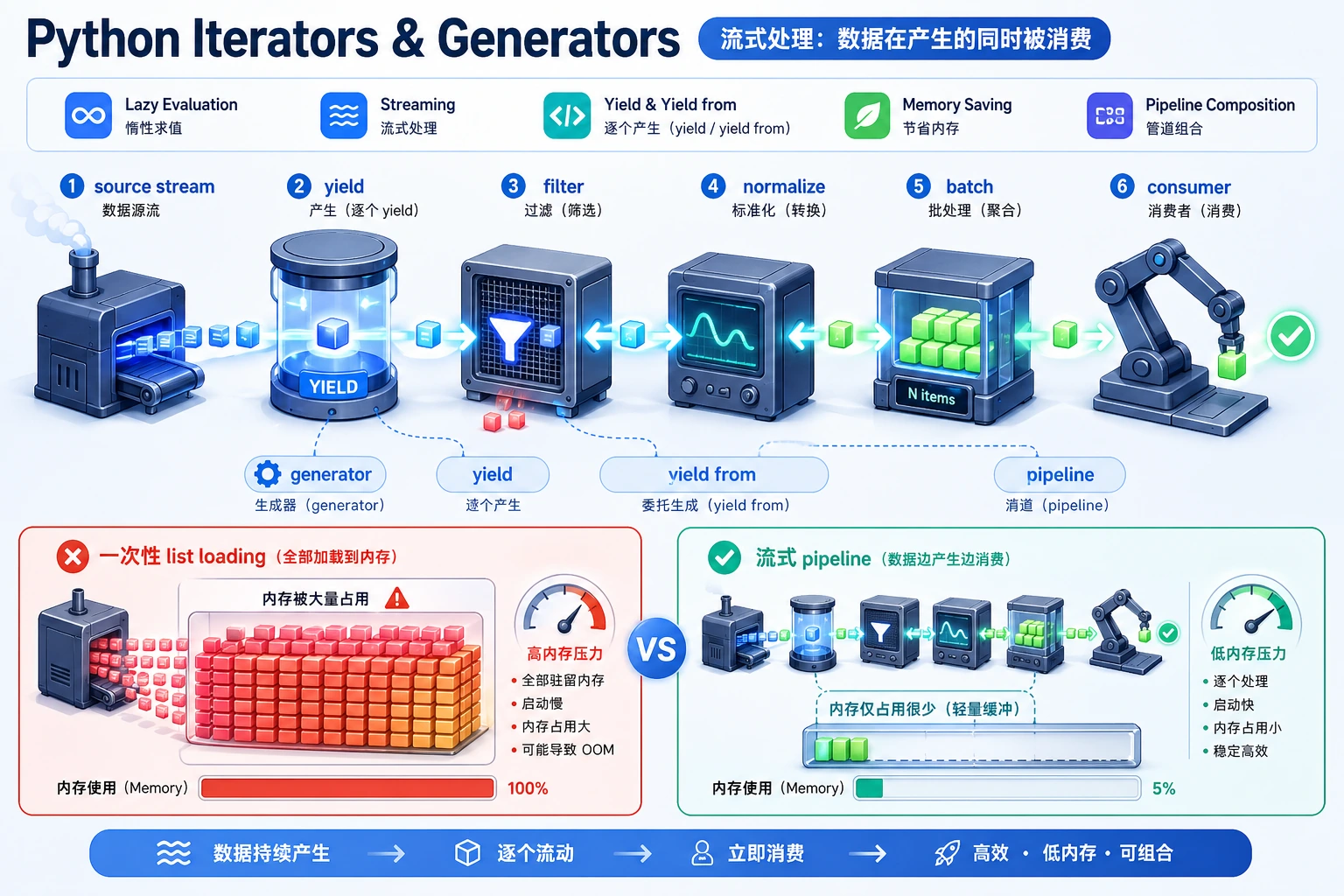
当数据像流一样到来时,生成器很有用:日志、文件、API 分页、样本批次、检索结果或模型输出。它一次只产出一个值,可以避免创建不必要的中间列表。
- Python 3.10+
- 不需要第三方包
- 理解
for循环
- Iterator(迭代器):能不断产出下一个值的对象。
- Generator(生成器):使用
yield惰性产出值的函数。 - Lazy evaluation(惰性求值):需要下一个值时才计算。
- Pipeline(管线):多个小处理步骤串起来。
yield from:把另一个可迭代对象里的值继续向外产出。
运行流式处理管线
Section titled “运行流式处理管线”创建 generator_pipeline.py:
def read_events(): events = [ "INFO request ok", "ERROR db timeout", "INFO cache hit", "ERROR auth failed", "ERROR model busy", ] for event in events: yield event
def filter_errors(events): for event in events: if event.startswith("ERROR"): yield event
def normalize(events): for event in events: yield event.lower()
def batch(items, size): group = [] for item in items: group.append(item) if len(group) == size: yield group group = [] if group: yield group
pipeline = batch(normalize(filter_errors(read_events())), size=2)
for group in pipeline: print(group)运行:
python generator_pipeline.py预期输出:
['error db timeout', 'error auth failed']['error model busy']这条管线完成读取、过滤、标准化和分批,但没有在每一步都生成完整列表。
使用 yield from
Section titled “使用 yield from”运行这个独立小示例:
def flatten(groups): for group in groups: yield from group
pipeline = [ ["error db timeout", "error auth failed"], ["error model busy"],]
for item in flatten(pipeline): print(item)预期输出:
error db timeouterror auth failederror model busy这比嵌套循环更清楚地表达了“把每个分组里的元素继续向外产出”。
什么时候生成器有帮助
Section titled “什么时候生成器有帮助”适合:
- 输入可能很大。
- 记录是一条一条处理的。
- 想把读取、过滤、转换、分批串起来。
- 不需要随机访问全部元素。
如果数据很小,而且反复访问列表会让代码更简单,就直接用列表。
复盘生成器管线时,至少检查三个位置:第一条数据、中间一条数据和最终数量。这能发现空流、漏行,以及生成器被消费一次后再次读取为空的问题。
在 AI 数据处理中,生成器的价值是让数据一条条通过管线,同时保留可观察 trace。记录哪些行被读取、哪些被过滤、哪些进入模型或评估器,比只说“节省内存”更有用。
交付检查时,给管线加一个小计数器:读入多少条、过滤多少条、输出多少条。这个计数器能快速发现规则写反、空输入、或者某一步过度过滤。流式代码也需要证据,不是越懒加载越好。
学完这一页,至少保留这张证据卡:
- Python 模式
- 装饰器、迭代器、生成器、并发原语,或元编程钩子
- 代码产物
- 最小可运行示例加上打印输出
- 使用场景
- 这种模式在哪种 AI 应用、流水线、工具或服务器中更有用
- 失败检查
- 隐藏副作用、难读的抽象、竞态条件或过度设计
- 期望产出
- 带实际 AI 系统用途说明的小型高级 Python 示例
- 以为生成器消费完后还能复用。
- 以为生成器永远更快;它的主要价值常常是省内存和组织流程。
- 很简单的列表转换也强行写成
yield,反而降低可读性。
修改 batch,让它同时打印 batch_id。然后改变输入事件,确认后续步骤不改也能继续工作。
参考实现与讲解
一种可接受做法是在输出端给 batch 编号:
for batch_id, group in enumerate(batch(normalized, size=2), start=1): print(batch_id, group)这样前面的读取、过滤、标准化步骤都不需要改。如果改变输入事件后,只是打印出的分组变化,而流水线结构保持不变,就说明练习完成了。核心是:生成器流水线应该允许你替换数据,而不用重写每个后续步骤。