6.5.1 Transformer 路线图:Attention 让 token 互相看见
Transformer 是从深度学习走向现代 LLM 的桥。第一直觉很简单:每个 token 可以决定哪些其他 token 更重要。
Transformer 为什么会出现
Section titled “Transformer 为什么会出现”RNN/LSTM 能处理顺序,但它们有两个历史瓶颈:训练时很难完全并行,远距离信息要沿很多步传递。Attention 先解决“当前位置直接看哪些上下文”,Transformer 再把这个机制变成可大规模堆叠的架构。
| 旧问题 | Attention / Transformer 的回答 |
|---|---|
| RNN 必须一步步读序列,训练并行度差 | self-attention 可以同时计算多个 token 的关系 |
| 长距离依赖要穿过很多 hidden state | 每个 token 可以直接给远处 token 打分 |
| 单个 attention 机制还不够稳定堆深 | Transformer block 加入残差、归一化和 FFN |
| 序列模型需要同时处理上下文和生成约束 | mask 让生成模型只能看过去,不能偷看未来 |
这就是为什么现代 LLM 几乎都建立在 Transformer decoder 或其变体上:它把“上下文选择”变成了可并行、可扩展、可堆叠的计算块。
先看 Attention 流程
Section titled “先看 Attention 流程”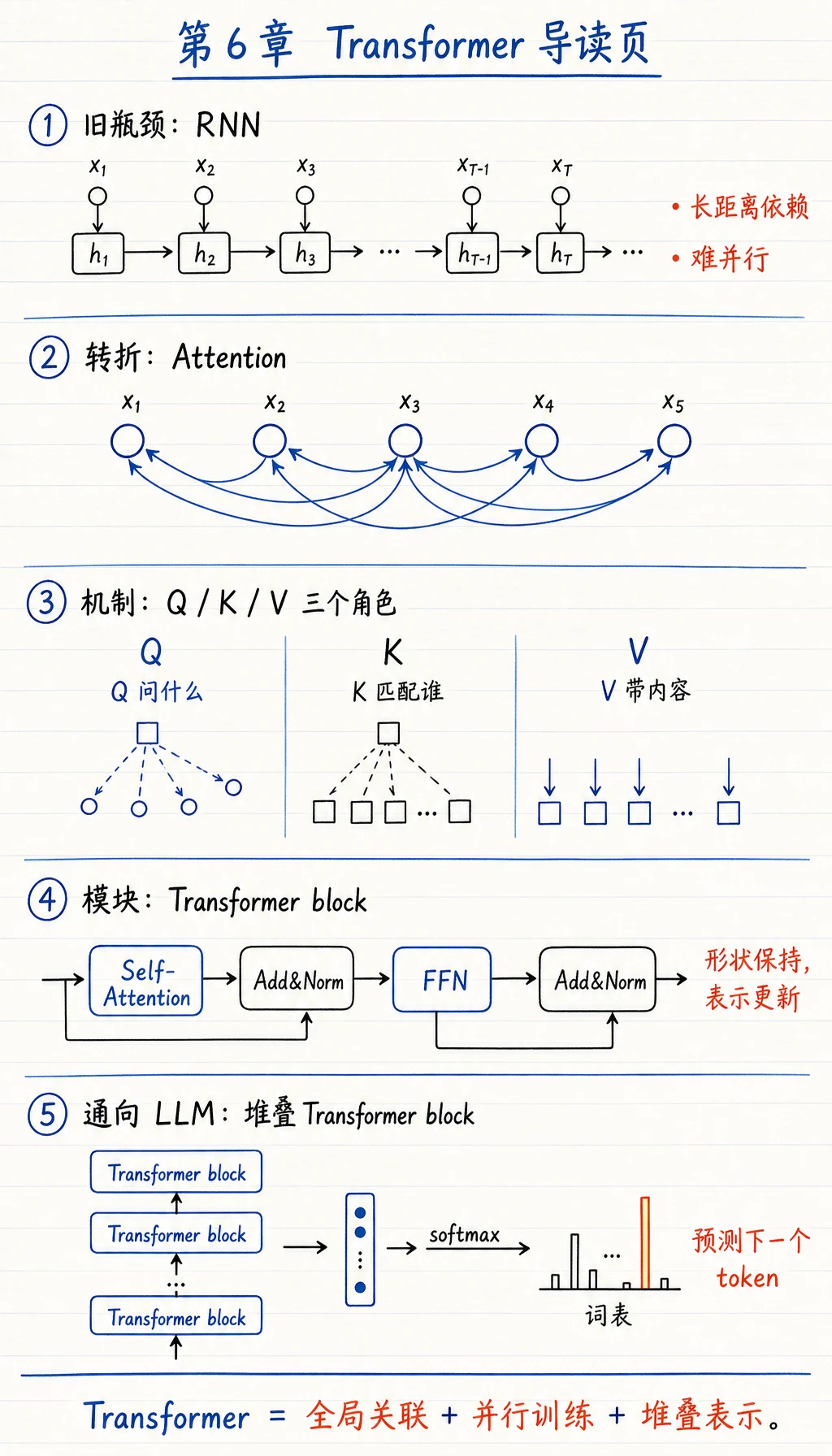
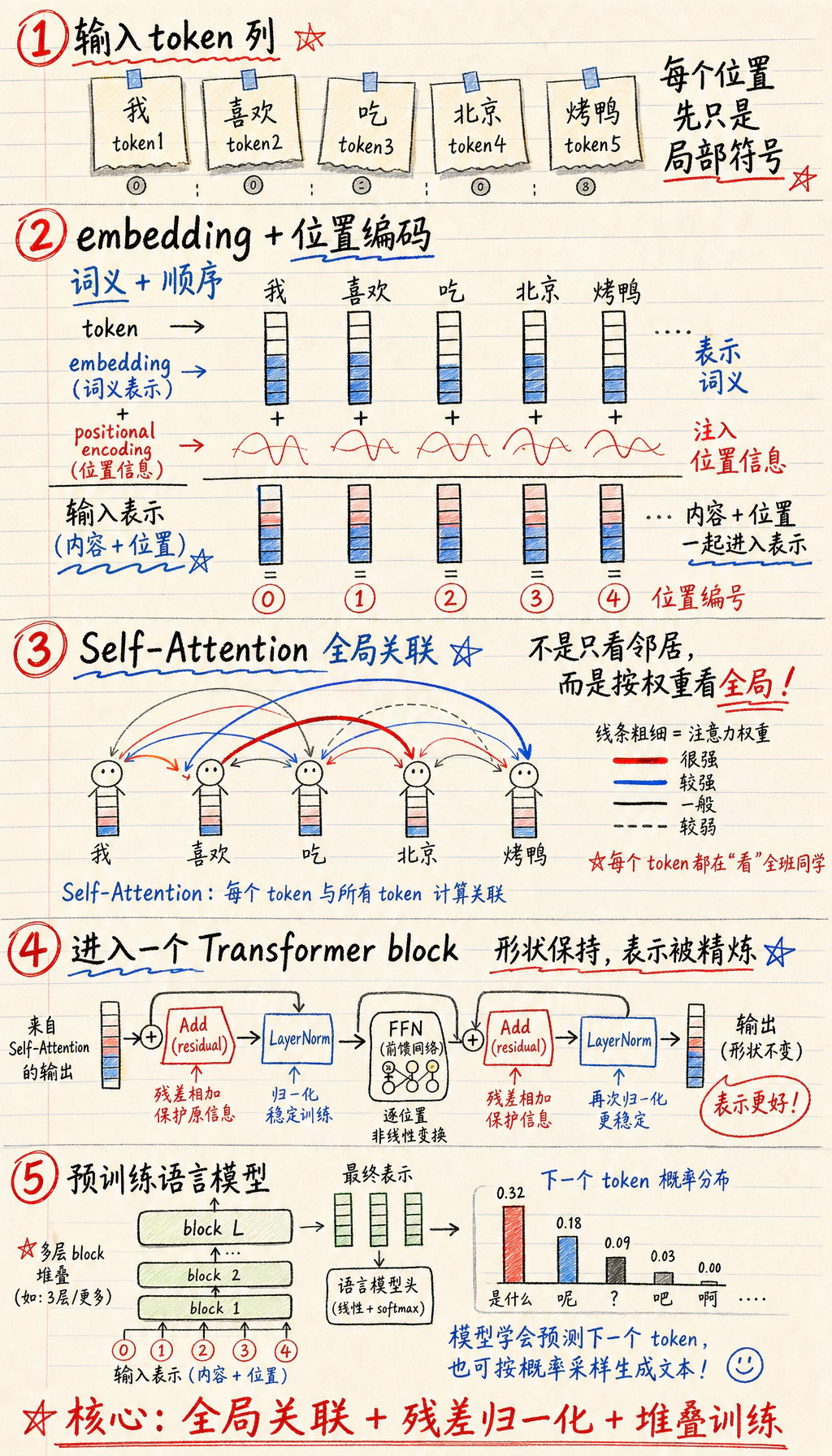
| 概念 | 第一层意思 |
|---|---|
| token | 序列里的一个位置 |
| Q / K / V | token 的 query、key、value 视角 |
| attention weight | 一个 token 看另一个 token 的程度 |
| block | attention 加前馈层反复精炼表示 |
| mask | 生成时防止看见未来 token |
跑一次 Attention 形状检查
Section titled “跑一次 Attention 形状检查”创建 transformer_first_loop.py,安装 torch 后运行。
import torch
attention = torch.nn.MultiheadAttention(embed_dim=8, num_heads=2, batch_first=True)tokens = torch.randn(1, 4, 8)output, weights = attention(tokens, tokens, tokens)
print("tokens_shape:", tuple(tokens.shape))print("output_shape:", tuple(output.shape))print("attention_shape:", tuple(weights.shape))预期输出:
tokens_shape: (1, 4, 8)output_shape: (1, 4, 8)attention_shape: (1, 4, 4)attention_shape 是 [batch, query_position, key_position]:4 个位置里的每个位置都能看 4 个位置。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 6.5.2 Attention 机制 | QKV、attention 权重、mask |
| 2 | 6.5.3 Transformer 架构 | block 结构、残差、前馈层 |
保留一条 attention 桥接笔记:
- token 张量形状
- [batch, seq_len, embed_dim]
- 注意力形状
- [batch, query_position, key_position]
- QKV 含义
- Q/K 负责匹配,V 携带内容
- mask 原因
- 生成不能看到未来 token
- LLM 桥接
- 解码器块把 token 上下文转换为下一个 token 的 logits
能读懂 attention 权重形状,解释为什么 attention 带来全局上下文,并把 mask 和文本生成联系起来,就算通过。
检查思路与讲解
- 合格答案要把 tensor、模型层、loss、
backward()和 optimizer 更新连成一个训练闭环。 - 证据应包含可运行的小实验、tensor shape 检查,以及能解释的 loss 或验证曲线。
- 自检时要能指出一个失败模式,例如 shape 不匹配、loss 不下降、过拟合、数据泄漏,或只会说 Attention/Transformer 名词却讲不出数据流。