8.4.6 长上下文、RAG 与记忆的选择
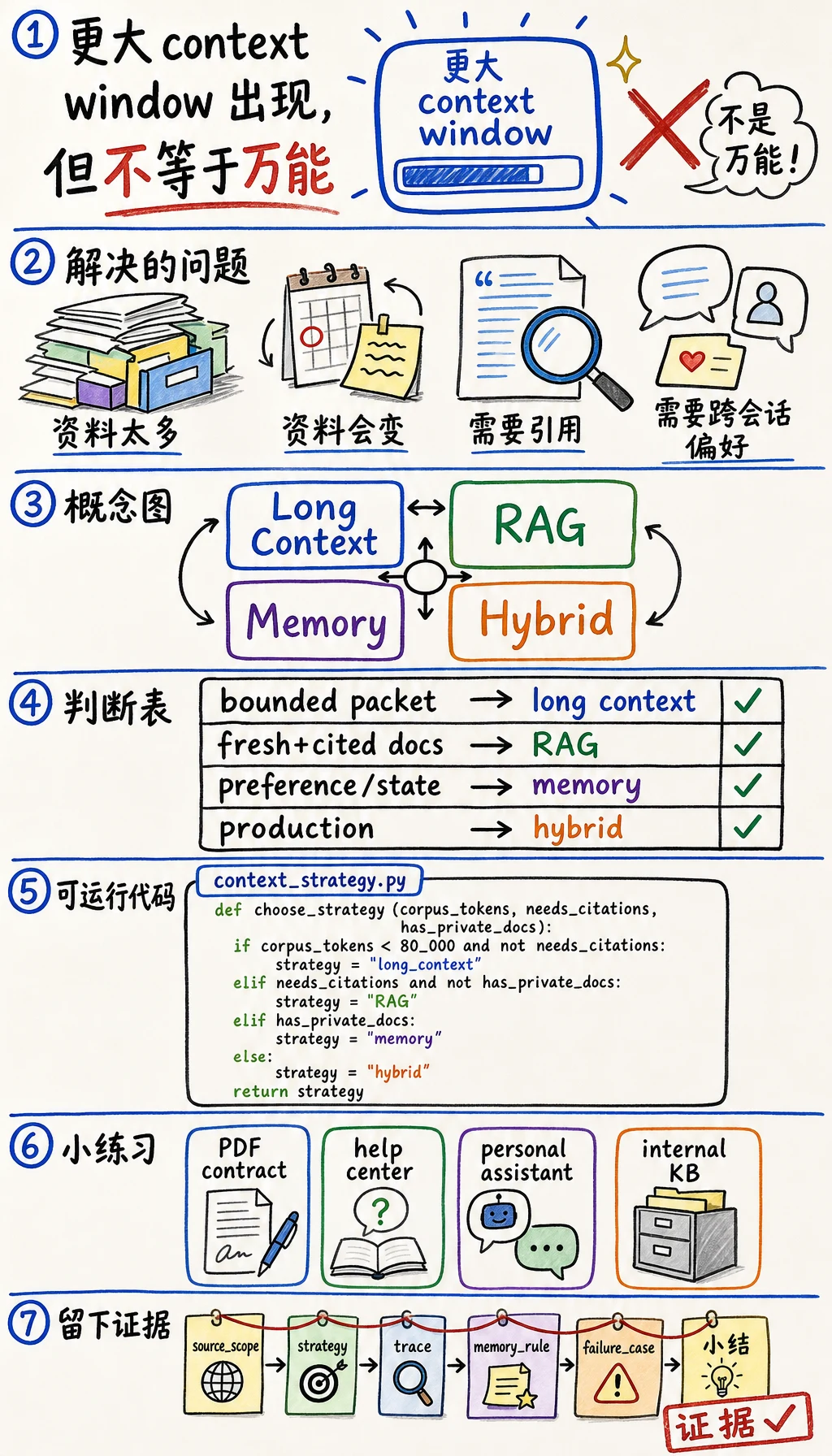
长上下文模型、RAG 系统和 Agent 记忆都在解决同一个痛点:模型需要在正确时间拿到正确资料。常见错误是把其中一种技术当成唯一答案。
这一节给你一套判断规则。现在 GPT-4.1 和 Claude 1M context 这类长上下文能力,让一些工作流可以直接读很多材料。但更大的窗口并不等于不需要检索、引用、权限控制或记忆清理。
为什么这项技术会出现
Section titled “为什么这项技术会出现”在长上下文能力变强之前,RAG 经常是“模型需要更多文档”的默认答案。它有效,但也带来切块、embedding、索引、排序、引用和更新的问题。
长上下文改变了权衡:
- 可以直接放入更多源材料。
- 小型或边界清晰的语料,不一定要先做复杂检索。
- 某些场景下,完整 prompt 更容易审查。
但长上下文也有新问题:
- token 更多,成本和延迟可能更高。
- 关键证据可能被淹没。
- 用户长期偏好不应该每次都塞进 prompt。
- 私有或合规文档仍然需要访问控制。
记忆提供第三个轴:什么内容应该跨会话保存?
| 技术 | 保存什么 | 最适合 | 主要风险 |
|---|---|---|---|
| 长上下文 | 很大的 prompt,包含文件或片段 | 一次性深度阅读、代码审查、合同/文档对比、会议记录分析 | 成本、延迟、注意力稀释 |
| RAG | 从语料库检索出的 chunk | 新鲜知识、引用、大型资料库、按用户授权访问 | 切块差、检索错、索引旧 |
| 记忆 | 持久化事实、偏好和状态 | 用户/项目跨会话连续性 | 记忆过期、敏感、隐含假设 |
| 混合 | 上下文 + 检索 + 记忆 | 生产级助手和 Agent | 如果没有 trace,会更难调试 |
| 如果任务需要… | 优先选择 | 原因 |
|---|---|---|
| 一个边界清晰、能放进上下文的资料包 | 长上下文 | 少一个系统层,trace 更简单 |
| 很多文档、经常更新或必须引用 | RAG | 搜索、元数据和新鲜度很重要 |
| 跨会话保存用户偏好或项目状态 | 记忆 | 不应该每次都重复粘贴 |
| 按用户权限访问私有文档 | RAG + 权限过滤 | 检索必须遵守授权 |
| 一个持续数周工作的复杂 Agent | 混合 | 记忆管状态,RAG 找证据,上下文承载当前任务 |
可运行实验:选择上下文策略
Section titled “可运行实验:选择上下文策略”创建 context_strategy.py,用 Python 3.10 或更高版本运行。
import jsonfrom pathlib import Path
project = { "corpus_tokens": 180_000, "changes_weekly": True, "needs_citations": True, "has_user_preferences": True, "has_private_docs": True, "model_context_limit": 1_000_000,}
def choose_strategy(info): can_fit = info["corpus_tokens"] < info["model_context_limit"] * 0.6 if info["needs_citations"] or info["changes_weekly"] or info["has_private_docs"]: base = "RAG" elif can_fit: base = "long_context" else: base = "RAG"
memory = "project_memory" if info["has_user_preferences"] else "no_persistent_memory"
if base == "RAG" and can_fit: pattern = "hybrid: retrieve first, then pack the most useful evidence into context" elif base == "long_context": pattern = "long context: pack bounded sources and keep a prompt manifest" else: pattern = "RAG: index corpus, retrieve with metadata, cite sources"
return {"base": base, "memory": memory, "pattern": pattern}
plan = { "strategy": choose_strategy(project), "evidence_to_keep": [ "source manifest", "retrieved chunks or packed files", "citation table", "latency and cost note", "memory write/delete rule", ],}
Path("context_strategy.json").write_text(json.dumps(plan, indent=2), encoding="utf-8")print(json.dumps(plan, indent=2))预期输出:
{ "strategy": { "base": "RAG", "memory": "project_memory", "pattern": "hybrid: retrieve first, then pack the most useful evidence into context" }, "evidence_to_keep": [ "source manifest", "retrieved chunks or packed files", "citation table", "latency and cost note", "memory write/delete rule" ]}corpus_tokens 和 model_context_limit 判断资料能不能放进去。但“放得下”不等于“应该直接放”。
needs_citations、changes_weekly 和 has_private_docs 会把选择推向 RAG,因为你需要来源元数据、刷新和授权控制。
has_user_preferences 打开记忆层。记忆不是文档仓库,而是小型持久状态层。
pattern 解释最终设计。很多强系统都是混合式:先检索最有用的证据,再用长上下文让模型围绕更完整的资料包推理。
修改 project,重新运行。
| 场景 | 修改 | 预期方向 |
|---|---|---|
| 一份 PDF 合同审查 | corpus_tokens=80_000, changes_weekly=False, needs_citations=True | 长上下文或带引用表的混合方案 |
| 产品帮助中心 | corpus_tokens=8_000_000, changes_weekly=True | RAG |
| 个人写作助手 | has_user_preferences=True, needs_citations=False | 记忆 + 当前 prompt |
| 内部知识库 | has_private_docs=True | 带权限过滤的 RAG |
每次选择上下文策略时,留下这组材料:
- Source Scope
- 允许使用哪些文档或记忆
- Strategy
- long_context、RAG、memory 或 hybrid
- Why Not Other
- 被拒绝的一个方案和原因
- Trace
- 打包文件或检索 chunk
- Memory Rule
- 什么时候写入、更新或删除记忆
- Failure Case
- 这个策略可能失败的一个例子
长上下文能减少一部分检索工程,但不能替代 RAG 或记忆。边界清晰的阅读用长上下文,需要可搜索和可治理证据用 RAG,需要跨会话状态用记忆,生产系统常常需要混合。
检查理解
能解释为什么“上下文更多”不等于“证据更好”,并能根据资料大小、新鲜度、引用需求、隐私、延迟和持久性选择方案,就算通过本节。