2.1.3 运算符与表达式
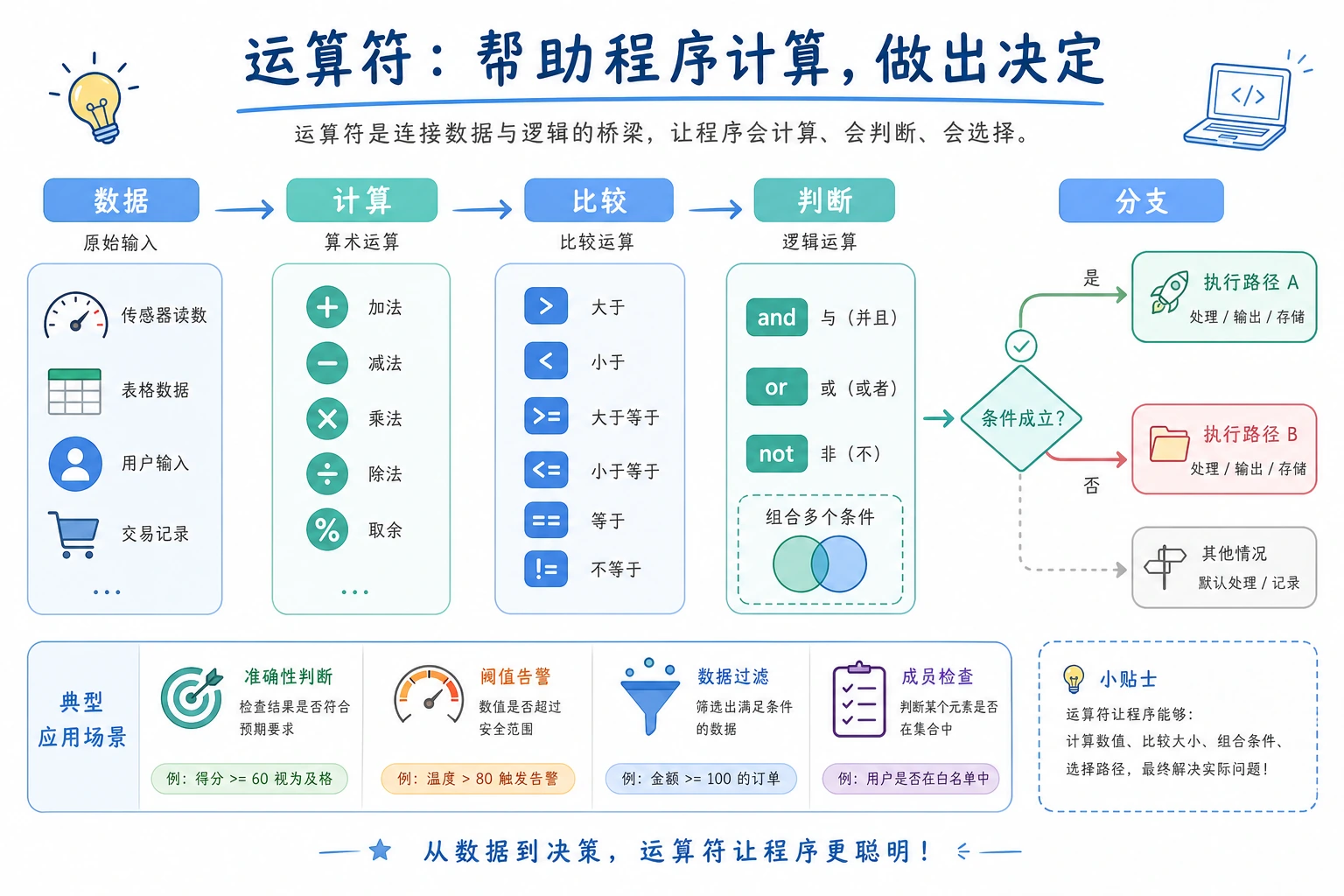
先看这张图:每个判断都从一个表达式开始,表达式通过比较和逻辑运算符变成 True 或 False,再决定程序走哪条分支。
这一节学习如何对数据做计算和判断。运算符不仅用于数学计算,也会出现在模型指标计算、条件筛选、循环判断和数据清洗逻辑里,是把变量组合成程序逻辑的第一步。
- 掌握算术运算符、比较运算符、逻辑运算符
- 理解运算符的优先级
- 学会使用赋值运算符和成员运算符
- 能写出正确的条件表达式
| 你想做什么 | 常用运算符 |
|---|---|
| 计算数值 | +、-、*、/ |
| 比较大小 | >、>=、==、!= |
| 组合条件 | and、or、not |
| 判断是否包含 | in、not in |
先看一个场景
Section titled “先看一个场景”你在开发一个 AI 数据处理脚本,需要:
- 计算模型准确率:
correct / total * 100 - 判断是否达标:
accuracy >= 60 - 检查两个条件:
accuracy >= 60 and loss < 0.5
这些操作都离不开运算符。运算符就是告诉 Python “对数据做什么操作”的符号。
最基础的数学运算:
| 运算符 | 含义 | 示例 | 结果 |
|---|---|---|---|
+ | 加法 | 5 + 3 | 8 |
- | 减法 | 5 - 3 | 2 |
* | 乘法 | 5 * 3 | 15 |
/ | 除法 | 5 / 3 | 1.6667 |
// | 整除 | 5 // 3 | 1 |
% | 取余 | 5 % 3 | 2 |
** | 幂运算 | 5 ** 3 | 125 |
# 场景:计算 AI 模型训练的一些指标
total_samples = 1000 # 总样本数correct = 873 # 正确预测数epochs = 50 # 训练轮数batch_size = 32 # 批次大小
# 计算准确率accuracy = correct / total_samples * 100print(f"准确率: {accuracy}%") # 87.3%
# 计算需要多少个批次才能跑完一个 epochbatches_per_epoch = total_samples // batch_sizeremaining = total_samples % batch_size
print(f"每个 epoch 有 {batches_per_epoch} 个完整批次") # 31print(f"最后一个批次有 {remaining} 个样本") # 8
# 计算指数衰减的学习率initial_lr = 0.01decay = 0.95current_lr = initial_lr * (decay ** epochs)print(f"第 {epochs} 轮的学习率: {current_lr:.6f}") # 0.000769除法的两种形式
Section titled “除法的两种形式”这是新手常混淆的地方:
print(7 / 2) # 3.5 ← 普通除法,结果是 floatprint(7 // 2) # 3 ← 整除,丢掉小数部分print(-7 // 2) # -4 ← 注意!向下取整,不是向零取整
# 取余的妙用print(10 % 3) # 1 ← 10 除以 3 余 1print(15 % 5) # 0 ← 整除时余数为 0
# 判断奇偶数number = 42if number % 2 == 0: print(f"{number} 是偶数") # 42 是偶数比较运算符的结果总是布尔值(True 或 False):
| 运算符 | 含义 | 示例 | 结果 |
|---|---|---|---|
== | 等于 | 5 == 5 | True |
!= | 不等于 | 5 != 3 | True |
> | 大于 | 5 > 3 | True |
< | 小于 | 5 < 3 | False |
>= | 大于等于 | 5 >= 5 | True |
<= | 小于等于 | 5 <= 3 | False |
# 场景:判断模型表现accuracy = 87.3loss = 0.35
print(accuracy > 90) # False —— 准确率没超过 90print(accuracy >= 80) # True —— 准确率达到了 80 以上print(loss < 0.5) # True —— 损失值低于 0.5print(accuracy == 87.3) # True —— 准确率恰好是 87.3链式比较(Python 特有)
Section titled “链式比较(Python 特有)”Python 允许链式比较,这在其他语言中是做不到的:
latency_ms = 185
# 判断延迟是否在 API 可接受范围内print(50 <= latency_ms <= 200) # True
# 等价于print(50 <= latency_ms and latency_ms <= 200) # True,但上面的写法更简洁
# 更多示例x = 5print(1 < x < 10) # Trueprint(1 < x < 3) # False逻辑运算符用来组合多个条件:
| 运算符 | 含义 | 说明 |
|---|---|---|
and | 与 | 两个都为真才是真 |
or | 或 | 至少一个为真就是真 |
not | 非 | 取反,真变假,假变真 |
tests_passed = Truehas_review = Truehas_rollback_plan = False
# and:两个条件都满足can_release = tests_passed and has_reviewprint(f"能否发布: {can_release}") # True(测试通过,并且完成评审)
# or:至少满足一个条件has_safety_net = has_review or has_rollback_planprint(f"是否有安全保障: {has_safety_net}") # True(评审已经提供了一层检查)
# not:取反needs_attention = not tests_passedprint(f"是否需要关注: {needs_attention}") # False实际案例:AI 模型评估
Section titled “实际案例:AI 模型评估”accuracy = 92.5loss = 0.15training_time = 3.5 # 小时
# 好模型的标准:准确率 > 90 且 损失 < 0.3is_good_model = accuracy > 90 and loss < 0.3print(f"是好模型吗: {is_good_model}") # True
# 需要重新训练:准确率太低 或 损失太高need_retrain = accuracy < 80 or loss > 1.0print(f"需要重新训练吗: {need_retrain}") # False
# 实用模型:好模型 且 训练时间合理is_practical = is_good_model and not (training_time > 24)print(f"是否实用: {is_practical}") # True
读这张图时,重点看判断顺序:左侧条件如果已经能决定结果,右侧表达式就不会再执行。
Python 的 and 和 or 有一个聪明的特性——短路求值:
# and:如果第一个条件是 False,不会检查第二个条件# 因为第一个已经是 False 了,结果必然是 FalseFalse and print("这句话不会被执行")
# or:如果第一个条件是 True,不会检查第二个条件# 因为第一个已经是 True 了,结果必然是 TrueTrue or print("这句话也不会被执行")这个特性在实际编程中经常用来做安全检查:
# 先检查列表是否为空,再访问元素(避免报错)data = []# 如果 data 为空,len(data) > 0 是 False,后面的不会执行if len(data) > 0 and data[0] > 10: print("第一个元素大于 10")读短路表达式时,顺序非常重要:把最便宜、最安全的检查放在前面,把可能报错或更耗时的访问放在后面。后面学习文件、列表、字典、API 返回值时,这个习惯会反复用到。
除了基本的 =,还有一些简写形式:
| 运算符 | 等价写法 | 示例 |
|---|---|---|
+= | a = a + b | a += 5 |
-= | a = a - b | a -= 3 |
*= | a = a * b | a *= 2 |
/= | a = a / b | a /= 4 |
//= | a = a // b | a //= 3 |
%= | a = a % b | a %= 2 |
**= | a = a ** b | a **= 3 |
completed_tasks = 0
completed_tasks += 2 # completed_tasks = 0 + 2 = 2completed_tasks += 3 # completed_tasks = 2 + 3 = 5completed_tasks -= 1 # completed_tasks = 5 - 1 = 4completed_tasks *= 2 # completed_tasks = 4 * 2 = 8
print(f"已完成任务量: {completed_tasks}") # 8这些简写在循环中特别常用:
# 累加 1 到 100total = 0for i in range(1, 101): total += iprint(f"1 到 100 的和: {total}") # 5050in 和 not in 用来检查某个值是否在一个集合中:
# 在字符串中查找print("Python" in "I love Python") # Trueprint("Java" in "I love Python") # Falseprint("Java" not in "I love Python") # True
# 在列表中查找services = ["login-api", "search-api", "worker"]print("login-api" in services) # Trueprint("billing-api" in services) # False
# 实际应用:检查文件扩展名filename = "model.py"if ".py" in filename: print("这是一个 Python 文件")is 和 is not 用来检查两个变量是否是同一个对象(不是值相等,而是内存中的同一个东西):
a = None
# 检查是否是 None(推荐用 is,不用 ==)print(a is None) # Trueprint(a is not None) # False
# is 和 == 的区别x = [1, 2, 3]y = [1, 2, 3]z = x
print(x == y) # True —— 值相等print(x is y) # False —— 不是同一个对象(两个不同的列表)print(x is z) # True —— z 指向 x,是同一个对象运算符优先级
Section titled “运算符优先级”当一个表达式里有多个运算符时,Python 按照优先级从高到低计算:
| 优先级(高→低) | 运算符 |
|---|---|
| 1(最高) | ** 幂运算 |
| 2 | +x, -x 正负号 |
| 3 | *, /, //, % |
| 4 | +, - |
| 5 | ==, !=, >, <, >=, <= |
| 6 | not |
| 7 | and |
| 8(最低) | or |
# 不加括号result = 2 + 3 * 4 # 先乘后加:2 + 12 = 14result = 2 ** 3 ** 2 # 幂运算从右到左:2 ** 9 = 512
# 加括号更清晰(推荐)result = (2 + 3) * 4 # 20result = (2 ** 3) ** 2 # 64表达式调试法
Section titled “表达式调试法”当一个条件判断看不懂时,不要一次盯完整表达式。把它拆成中间变量:
accuracy = 87.3loss = 0.35latency_ms = 185
is_accurate_enough = accuracy >= 80is_loss_ok = loss < 0.5is_latency_ok = latency_ms < 250
can_demo = is_accurate_enough and is_loss_ok and is_latency_okprint(is_accurate_enough, is_loss_ok, is_latency_ok, can_demo)这样做有两个好处:第一,打印结果能告诉你到底是哪一个小条件失败;第二,变量名会把业务含义写进代码里,比一长串符号更容易复查。
表达式拆开以后,还可以把每个中间变量打印出来,形成最小调试 trace。以后做数据清洗、模型评估或 API 监控时,很多 bug 都不是算法错,而是某个条件写反、阈值写错、或者 and / or 组合顺序不符合业务预期。
在相信一个条件表达式前,先问三个问题:
- 我是在用
==比较,而不是误写成=赋值吗? - 阈值方向是否清楚,例如
latency_ms < 250,而不是只靠含糊的变量名猜? - 我是否至少测过一个应该通过的例子和一个应该失败的例子?
这个习惯很小,但能避免很多新手 bug。运算符看起来简单,真实程序里的大多数判断却都是由它们拼出来的。
运算符什么时候变成项目逻辑
Section titled “运算符什么时候变成项目逻辑”真实项目里,运算符经常藏在业务规则中。一个模型是否可用,可能取决于 accuracy >= target、loss < limit 和 latency_ms < budget 是否同时成立。一条数据能不能保留,也可能取决于标签是否为空、文件类型是否在允许列表里。
所以这一页不是只背符号。每个运算符都应该让判断更容易阅读、测试和解释。只要某个条件会影响产品结果,就把它拆成有意义的变量,并至少测试一个通过案例和一个失败案例。
合并包含关键判断的代码前,先把条件读成一句人话。如果这句话含糊,就拆成更小的中间变量;如果这句话成立,就构造一个应该通过的输入和一个应该失败的输入。这样你会更早发现阈值方向写反、and/or 组合不对、或者成员判断漏掉边界值。
这也是审查入门 Python 代码的方法。语法可以很短,但判断必须讲得清楚:它在看什么数据、采用什么规则、错误输入会走到哪里。能讲清这些,再谈代码是否优雅。
如果同学只看变量名就无法预测结果,说明这一行表达式承担了太多工作。先拆成中间变量,再给每个变量打印一次结果。这样调试时不需要猜整个表达式哪里错,而是能定位到具体条件。
好的运算符代码不一定最短,而是规则清楚、能测试、能复查、以后能修改。写条件时先追求可解释,再追求简洁。
综合案例:API 延迟检查
Section titled “综合案例:API 延迟检查”把今天学的运算符综合运用一下:
# API 延迟检查service = "登录 API"db_latency = 70 # msapi_latency = 45 # msui_latency = 80 # ms
# 计算平均延迟total_latency = db_latency + api_latency + ui_latencyaverage_latency = total_latency / 3print(f"{service} 平均延迟: {average_latency:.1f} ms") # 65.0
# 判断服务状态is_fast = average_latency < 100is_acceptable = 100 <= average_latency < 250is_slow = 250 <= average_latency < 500is_incident_risk = average_latency >= 500
print(f"快速: {is_fast}") # Trueprint(f"可接受: {is_acceptable}") # Falseprint(f"偏慢: {is_slow}") # Falseprint(f"事故风险: {is_incident_risk}") # False
# 综合判断is_ready = is_fast and not is_incident_riskprint(f"能否演示: {is_ready}") # True练习 1:延迟状态判断
Section titled “练习 1:延迟状态判断”用比较运算符和逻辑运算符判断延迟状态:
latency_ms = 185
is_fast = latency_ms < 100 # 快速is_acceptable = latency_ms >= 100 and latency_ms < 250is_slow = latency_ms >= 250 and latency_ms < 500is_incident_risk = latency_ms >= 500
# 打印结果print(f"延迟: {latency_ms} ms")print(f"快速: {is_fast}")print(f"可接受: {is_acceptable}")print(f"偏慢: {is_slow}")print(f"事故风险: {is_incident_risk}")修改 latency_ms 的值,试试不同延迟的结果。
练习 2:闰年判断
Section titled “练习 2:闰年判断”闰年规则:能被 4 整除但不能被 100 整除,或者能被 400 整除。
year = 2024
# 提示:用 % 判断能否整除,用 and、or 组合条件is_leap = ___ # 补全这个表达式
print(f"{year} 是闰年吗?{is_leap}")练习 3:三角形判断
Section titled “练习 3:三角形判断”判断三条边能否构成三角形(任意两边之和大于第三边):
a, b, c = 3, 4, 5
# 补全判断条件is_triangle = ___
print(f"边长 {a}, {b}, {c} 能构成三角形吗?{is_triangle}")参考实现与讲解
- 当
latency_ms = 185时,只有“可接受”分支应该为真。再用80、320、650测试其他分支。 - 闰年表达式可以写成
year % 4 == 0 and year % 100 != 0 or year % 400 == 0。加括号会更容易读。 - 三角形条件是
a + b > c and a + c > b and b + c > a。 - 至少测试反例和正例:
1, 2, 3为假,3, 4, 5为真,2, 2, 3为真。 - 较长的逻辑表达式建议加括号,即使运算符优先级本身可以正确执行。
学完这一页,至少保留这张证据卡:
- 概念
- 变量、类型、运算符、输入/输出、分支、循环、结构、函数或模块
- 代码
- 用于说明该概念的最小可运行 Python 代码片段
- 输出
- 打印值、类型、分支结果、循环 trace,或返回值
- 失败检查
- 类型不匹配、缩进错误、越界、可变数据或导入路径问题
- 期望产出
- 代码和打印结果,证明概念可行
| 运算符类型 | 常用符号 | 用途 |
|---|---|---|
| 算术 | +, -, *, /, //, %, ** | 数学计算 |
| 比较 | ==, !=, >, <, >=, <= | 条件判断,结果是 True/False |
| 逻辑 | and, or, not | 组合多个条件 |
| 赋值 | =, +=, -=, *= 等 | 给变量赋值 |
| 成员 | in, not in | 检查元素是否在集合中 |
| 身份 | is, is not | 检查是否是同一个对象 |