2.2.5 迭代器与生成器
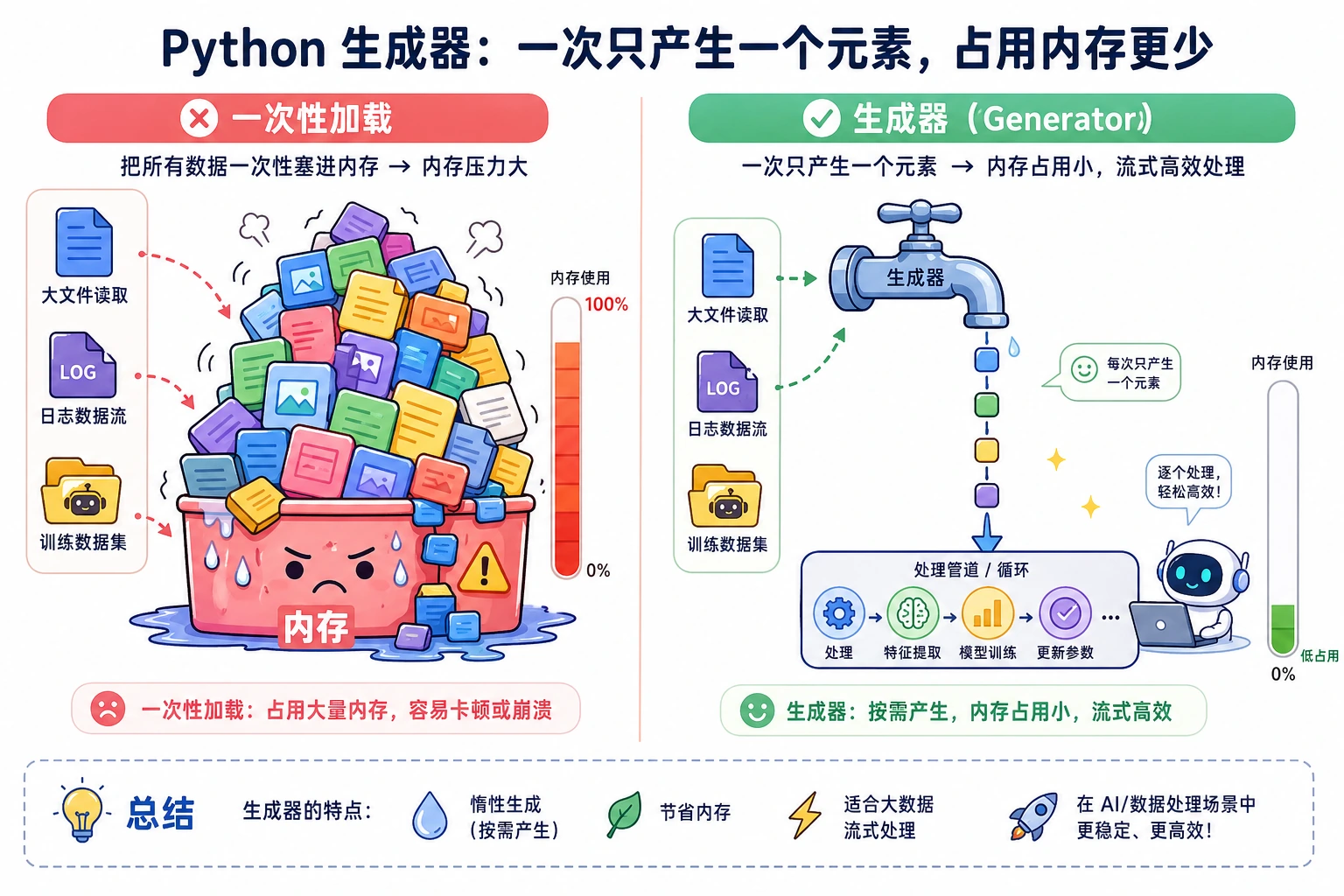
这一节解释 for 循环背后的机制,并引入更省内存的数据处理方式。迭代器和生成器在处理大文件、流式数据、训练数据加载时很有价值,先理解思想,再掌握最常见的 yield 写法。
- 理解迭代器协议(
__iter__和__next__) - 掌握生成器函数(
yield)的用法 - 理解生成器表达式
- 了解为什么生成器在处理大数据时非常重要
什么是迭代?
Section titled “什么是迭代?”你已经用过很多次 for 循环了:
for item in [1, 2, 3]: print(item)
for char in "Hello": print(char)
for key in {"a": 1, "b": 2}: print(key)for...in 能遍历这些东西,是因为它们都是可迭代对象(Iterable)。那么问题来了:for 循环的背后到底发生了什么?
for 循环的本质是这样的:
numbers = [10, 20, 30]
# for 循环写法for n in numbers: print(n)
# 等价的手动写法iterator = iter(numbers) # 1. 获取迭代器print(next(iterator)) # 2. 获取下一个元素 → 10print(next(iterator)) # 3. 获取下一个元素 → 20print(next(iterator)) # 4. 获取下一个元素 → 30# print(next(iterator)) # 5. 没有更多元素了 → 抛出 StopIteration迭代器协议:
iter(对象)→ 获取迭代器next(迭代器)→ 获取下一个元素- 元素用完时抛出
StopIteration异常
自定义迭代器
Section titled “自定义迭代器”class Countdown: """倒计时迭代器"""
def __init__(self, start): self.current = start
def __iter__(self): return self # 返回自身作为迭代器
def __next__(self): if self.current <= 0: raise StopIteration value = self.current self.current -= 1 return value
# 使用for num in Countdown(5): print(num, end=" ")# 输出: 5 4 3 2 1不过手写迭代器比较麻烦——接下来介绍的生成器是更简洁的方式。
生成器函数(Generator)
Section titled “生成器函数(Generator)”生成器是一种特殊的迭代器,用 yield 关键字代替 return。
def countdown(n): """倒计时生成器""" while n > 0: yield n # 暂停,返回 n,下次从这里继续 n -= 1
# 使用方式和迭代器一样for num in countdown(5): print(num, end=" ")# 输出: 5 4 3 2 1yield vs return 的区别
Section titled “yield vs return 的区别”# return:函数执行完毕,一次性返回所有结果def get_squares_return(n): result = [] for i in range(n): result.append(i ** 2) return result
# yield:每次返回一个结果,暂停等待下次调用def get_squares_yield(n): for i in range(n): yield i ** 2
# 使用效果一样print(list(get_squares_return(5))) # [0, 1, 4, 9, 16]print(list(get_squares_yield(5))) # [0, 1, 4, 9, 16]关键区别:
| 特点 | return | yield |
|---|---|---|
| 返回方式 | 一次返回所有 | 每次返回一个 |
| 内存使用 | 全部加载到内存 | 按需生成,几乎不占内存 |
| 执行方式 | 执行完毕 | 暂停/恢复 |
生成器的执行过程
Section titled “生成器的执行过程”def simple_gen(): print("第一步") yield 1 print("第二步") yield 2 print("第三步") yield 3 print("结束")
gen = simple_gen() # 创建生成器,但不执行任何代码
print(next(gen)) # 执行到第一个 yield,打印"第一步",返回 1print(next(gen)) # 从上次暂停处继续,打印"第二步",返回 2print(next(gen)) # 打印"第三步",返回 3# next(gen) # 打印"结束",然后抛出 StopIteration输出:
第一步1第二步2第三步3为什么需要生成器?—— 处理大数据
Section titled “为什么需要生成器?—— 处理大数据”这是生成器最重要的应用场景。
问题:一次性加载太多数据
Section titled “问题:一次性加载太多数据”# 假设你要处理一个 10GB 的文件# 错误做法:一次性读入所有行lines = open("huge_file.txt").readlines() # 💥 内存爆炸!
# 正确做法:用生成器逐行处理def read_large_file(filepath): with open(filepath, "r") as f: for line in f: # 文件对象本身就是迭代器,逐行读取 yield line.strip()
for line in read_large_file("huge_file.txt"): process(line) # 一次只有一行在内存中对比内存使用
Section titled “对比内存使用”import sys
# 列表:所有元素都在内存中big_list = [i ** 2 for i in range(1_000_000)]print(f"列表占用内存: {sys.getsizeof(big_list):,} 字节") # ~8MB
# 生成器:只记住当前状态big_gen = (i ** 2 for i in range(1_000_000))print(f"生成器占用内存: {sys.getsizeof(big_gen):,} 字节") # ~200 字节!8MB vs 200 字节——差了 4 万倍!当数据量更大时(比如处理几百万条训练数据),这个差距就是”程序能跑”和”内存溢出崩溃”的区别。
生成器表达式
Section titled “生成器表达式”列表推导式的 [] 换成 (),就变成了生成器表达式:
# 列表推导式 → 立即生成所有元素squares_list = [x ** 2 for x in range(10)]
# 生成器表达式 → 按需生成squares_gen = (x ** 2 for x in range(10))
print(type(squares_list)) # <class 'list'>print(type(squares_gen)) # <class 'generator'>
# 生成器表达式常用在函数参数中total = sum(x ** 2 for x in range(1000)) # 不需要额外的括号print(total)
tasks = [{"name": "登录 API", "hours": 8}, {"name": "RAG 演示", "hours": 12}]max_hours = max(task["hours"] for task in tasks)print(max_hours)实用生成器模式
Section titled “实用生成器模式”def infinite_counter(start=0, step=1): """无限计数器""" n = start while True: yield n n += step
# 生成前 10 个偶数counter = infinite_counter(0, 2)for _ in range(10): print(next(counter), end=" ")# 0 2 4 6 8 10 12 14 16 18生成器可以链式组合,形成数据处理管道:
def read_lines(filename): """读取文件每一行""" with open(filename) as f: for line in f: yield line.strip()
def filter_comments(lines): """过滤掉注释行""" for line in lines: if not line.startswith("#") and line: yield line
def parse_numbers(lines): """将每行转为数字""" for line in lines: try: yield float(line) except ValueError: continue # 跳过无法转换的行
# 管道组合:读取 → 过滤 → 转换# 内存中始终只有一行数据!sample = ["# note", "1", "2.5", "bad", "4"]numbers = parse_numbers(filter_comments(sample))total = sum(numbers)print(total)def batch(iterable, size): """将数据分成固定大小的批次""" batch_data = [] for item in iterable: batch_data.append(item) if len(batch_data) == size: yield batch_data batch_data = [] if batch_data: # 最后不满一批的数据 yield batch_data
# 模拟训练数据的批量处理data = list(range(1, 11)) # [1, 2, 3, ..., 10]
for b in batch(data, 3): print(f"处理批次: {b}")# 处理批次: [1, 2, 3]# 处理批次: [4, 5, 6]# 处理批次: [7, 8, 9]# 处理批次: [10]itertools:迭代器工具箱
Section titled “itertools:迭代器工具箱”Python 标准库的 itertools 提供了很多实用的迭代器工具:
import itertools
# chain:连接多个迭代器for item in itertools.chain([1, 2], [3, 4], [5, 6]): print(item, end=" ") # 1 2 3 4 5 6
# islice:切片迭代器(对生成器很有用)gen = (x ** 2 for x in range(100))first_five = list(itertools.islice(gen, 5))print(first_five) # [0, 1, 4, 9, 16]
# zip_longest:长度不等时填充tasks = ["登录 API", "RAG 演示", "图表视图"]owners = ["Mina", "Kai"]for task, owner in itertools.zip_longest(tasks, owners, fillvalue="未分配"): print(f"{task}: {owner}")# 登录 API: Mina, RAG 演示: Kai, 图表视图: 未分配
# product:笛卡尔积for combo in itertools.product(["红", "蓝"], ["大", "小"]): print(combo)# ('红', '大'), ('红', '小'), ('蓝', '大'), ('蓝', '小')
# count:无限计数for i in itertools.islice(itertools.count(10, 5), 5): print(i, end=" ") # 10 15 20 25 30综合案例:AI 数据加载器
Section titled “综合案例:AI 数据加载器”import random
def data_loader(dataset, batch_size=32, shuffle=True): """ 模拟 AI 训练的数据加载器。 用生成器实现,内存友好。 """ indices = list(range(len(dataset)))
if shuffle: random.shuffle(indices)
for start in range(0, len(indices), batch_size): batch_indices = indices[start:start + batch_size] batch_data = [dataset[i] for i in batch_indices] yield batch_data
# 模拟数据集dataset = [f"sample_{i}" for i in range(100)]
# 训练循环for epoch in range(3): print(f"\n=== Epoch {epoch + 1} ===") for batch_idx, batch in enumerate(data_loader(dataset, batch_size=32)): print(f" Batch {batch_idx + 1}: {len(batch)} 个样本 " f"(首个: {batch[0]}, 末个: {batch[-1]})")练习 1:斐波那契生成器
Section titled “练习 1:斐波那契生成器”def fibonacci(n=None): """生成斐波那契数。n 为 None 时生成无限序列。""" count = 0 a, b = 0, 1 while n is None or count < n: yield a a, b = b, a + b count += 1
for num in fibonacci(10): print(num, end=" ")# 0 1 1 2 3 5 8 13 21 34练习 2:文件搜索器
Section titled “练习 2:文件搜索器”from pathlib import Path
def search_files(directory, pattern): """递归生成匹配 pattern 的文件路径。""" yield from Path(directory).rglob(pattern)
for filepath in search_files(".", "*.py"): print(filepath)练习 3:滑动窗口
Section titled “练习 3:滑动窗口”def sliding_window(data, window_size): """生成固定大小的滑动窗口。""" for index in range(len(data) - window_size + 1): yield data[index:index + window_size]
for window in sliding_window([1, 2, 3, 4, 5], 3): print(window)参考实现与讲解
fibonacci(n)应该逐个yield数值,并在传入n时只生成前n个结果。示例循环应按顺序打印前十个斐波那契数。search_files应使用Path(directory).rglob(pattern)和yield from,这样文件会以惰性方式流式返回,而不是一次性收集。sliding_window应生成连续的固定大小切片。如果窗口比输入还长,循环体不会执行,这就是正确的空结果。
学完这一页,至少保留这张证据卡:
- 模式
- 类、异常、文件 IO、函数式流水线、生成器或类型提示
- 代码产物
- 最小可运行示例和一个真实使用场景
- 输出
- 打印的对象状态、捕获的错误、保存的文件、yield 的值,或类型检查备注
- 失败检查
- 隐藏变异、吞掉异常、文件路径问题、懒迭代器混淆或误导性标注
- 期望产出
- 带调试说明的小型高级 Python 示例
| 概念 | 说明 | 关键点 |
|---|---|---|
| 迭代器 | 实现了 __iter__ 和 __next__ 的对象 | for 循环的底层机制 |
| 生成器函数 | 包含 yield 的函数 | 创建迭代器的简洁方式 |
| 生成器表达式 | (x for x in iterable) | 列表推导式的惰性版本 |
| yield | 暂停函数并返回值 | 下次调用时从暂停处继续 |
| itertools | 标准库的迭代器工具箱 | chain, islice, product 等 |