11.5.3 NLP 中的注意力机制
- 理解注意力机制出现的背景
- 理解“对齐”和“加权聚合”的核心直觉
- 通过可运行示例理解注意力权重和上下文向量
- 建立注意力和后续 Transformer 之间的连接感
先建立一张地图
Section titled “先建立一张地图”注意力机制这节最适合新人的理解顺序是:
flowchart LR A["固定长度编码向量"] --> B["长句子容易丢信息"] B --> C["解码时重新看输入"] C --> D["给不同位置分不同权重"] D --> E["得到上下文向量"]所以这节真正想解决的是:
- 为什么固定向量会成为瓶颈
- 为什么“动态看输入”会更自然
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把注意力理解成:
- 做阅读理解时一边看题目,一边回原文找最相关的句子
如果没有注意力, 就像你只能在读完全文后的最后一秒,把整篇文章压成一个模糊印象再作答。 这当然会越来越吃力。
有了注意力之后,模型就更像是在做:
- 当前要生成这个词,我该回头重点看输入里的哪一块?
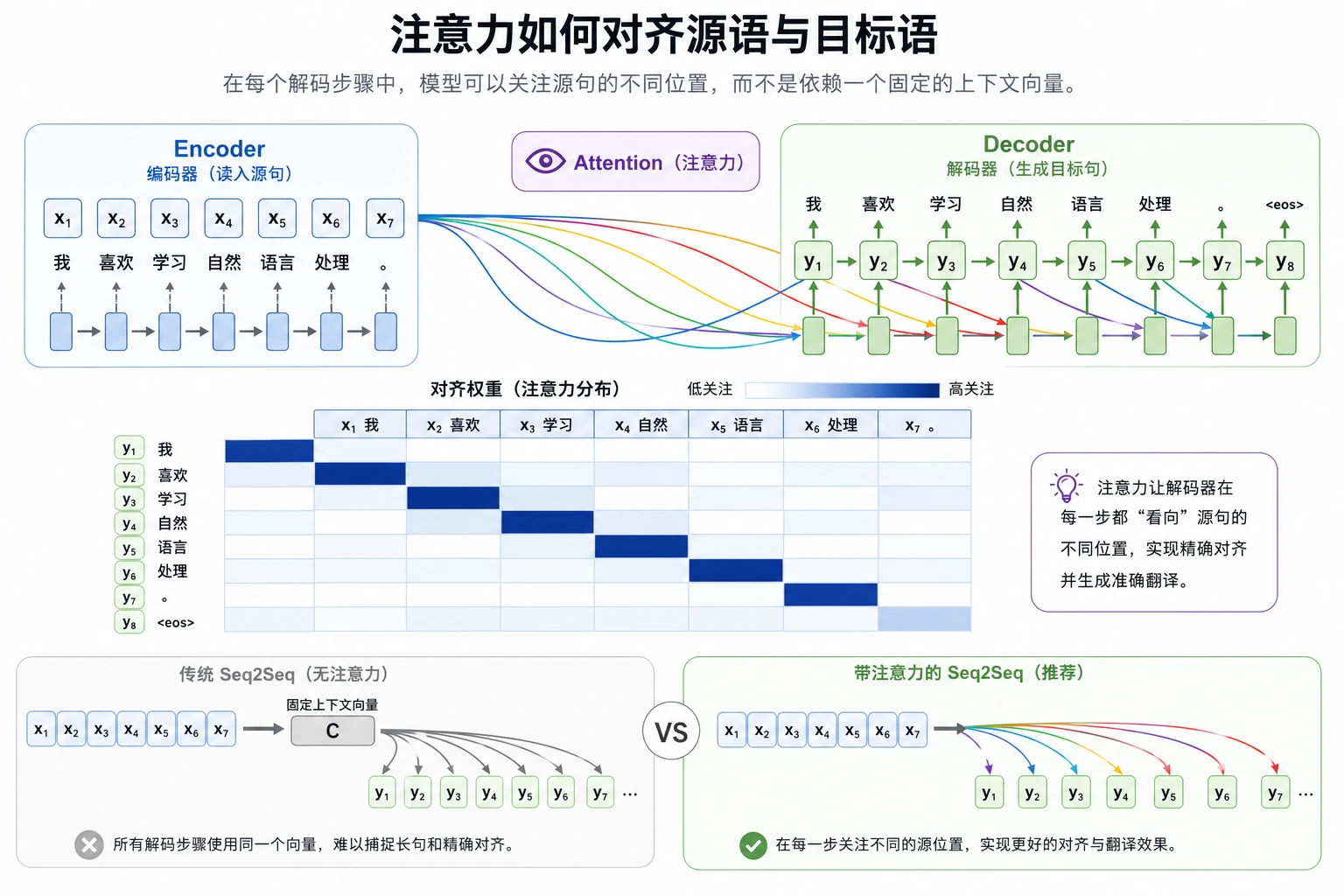
一、为什么 Seq2Seq 需要注意力?
Section titled “一、为什么 Seq2Seq 需要注意力?”固定长度编码容易丢信息
Section titled “固定长度编码容易丢信息”如果输入是:
- 很长的句子
- 复杂的段落
只把它压成一个固定向量, 解码器后面会很吃力。
解码器在不同时间步关注点应该不同
Section titled “解码器在不同时间步关注点应该不同”例如翻译时:
- 生成第 1 个词时关注输入前半
- 生成后面的词时关注输入别的位置
所以“整个输出过程只看同一个向量”并不自然。
注意力的核心直觉
Section titled “注意力的核心直觉”每次生成输出时, 都根据当前解码状态去问:
- 输入序列里谁和我最相关?
然后把相关位置加权聚合成当前上下文。
二、先跑一个最小注意力示例
Section titled “二、先跑一个最小注意力示例”import math
encoder_states = [ [1.0, 0.0], [0.5, 0.5], [0.0, 1.0],]
query = [0.7, 0.3]
def dot(a, b): return sum(x * y for x, y in zip(a, b))
def softmax(values): exps = [math.exp(v) for v in values] total = sum(exps) return [round(v / total, 4) for v in exps]
scores = [dot(state, query) for state in encoder_states]weights = softmax(scores)
context = [0.0, 0.0]for w, state in zip(weights, encoder_states): context = [context[i] + w * state[i] for i in range(len(context))]
print("scores :", [round(x, 4) for x in scores])print("weights:", weights)print("context:", [round(x, 4) for x in context])预期输出:
scores : [0.7, 0.5, 0.3]weights: [0.4018, 0.3289, 0.2693]context: [0.5663, 0.4337]最高权重落在第一个 encoder state 上,但 context 向量仍然混合了所有位置。Attention 不是硬查表,而是带权读取。
这段代码最该看什么?
Section titled “这段代码最该看什么?”三步最关键:
query和每个encoder_state打分softmax得到注意力权重- 用权重对 encoder states 做加权平均
为什么这已经体现了注意力本质?
Section titled “为什么这已经体现了注意力本质?”因为它回答了两个核心问题:
- 该看谁
- 看多少
这就是注意力最重要的直觉。
新人第一次学注意力,最该先记哪三件事?
Section titled “新人第一次学注意力,最该先记哪三件事?”query代表当前想找什么score代表每个输入位置和当前需求有多相关weights经过 softmax 后,决定“每个位置看多少”
再看一个最小“输出词对输入词”的对齐示例
Section titled “再看一个最小“输出词对输入词”的对齐示例”source_tokens = ["i", "love", "nlp"]attention_weights = [0.1, 0.2, 0.7]
for token, weight in zip(source_tokens, attention_weights): print({"source_token": token, "weight": weight})预期输出:
{'source_token': 'i', 'weight': 0.1}{'source_token': 'love', 'weight': 0.2}{'source_token': 'nlp', 'weight': 0.7}这说明在当前输出步,模型主要在看 nlp 这个输入位置。
这个示例虽然比真实模型简单很多, 但很适合帮助新人先建立一个图像化感觉:
- 生成当前输出词时
- 模型不是平均看所有输入
- 而是会把更多注意力放到更相关的位置上
三、注意力为什么会显著改善 Seq2Seq?
Section titled “三、注意力为什么会显著改善 Seq2Seq?”它缓解了信息瓶颈
Section titled “它缓解了信息瓶颈”输入不再只能通过一个固定向量传递给解码器。
它让输入输出对齐更自然
Section titled “它让输入输出对齐更自然”很多翻译任务本来就有“某个输出词大致对应输入哪些词”的结构。 注意力让这种对齐更容易学到。
这也是从经典 Seq2Seq 走向 Transformer 的桥梁
Section titled “这也是从经典 Seq2Seq 走向 Transformer 的桥梁”后面 Transformer 把注意力推广得更彻底, 但这节的直觉基础是一样的。
第一次学这节时,最值得先看的不是公式,而是流程
Section titled “第一次学这节时,最值得先看的不是公式,而是流程”更稳的理解顺序通常是:
- 先看固定编码为什么会卡住
- 再看 query 在“问什么”
- 再看 score 和 weight 怎样分配注意力
- 最后再去看上下文向量怎么被算出来
这样会比一上来就盯矩阵公式更容易稳住。
四、最容易踩的坑
Section titled “四、最容易踩的坑”误区一:注意力只是一个加权平均小技巧
Section titled “误区一:注意力只是一个加权平均小技巧”不止。 它改变了模型如何访问输入信息。
误区二:有注意力就再也不会丢信息
Section titled “误区二:有注意力就再也不会丢信息”不是。 长序列仍然会有难题,只是瓶颈被显著缓解。
误区三:注意力就是 Transformer
Section titled “误区三:注意力就是 Transformer”注意力是更大的概念,Transformer 是在其上发展出的完整架构。
如果把它做成笔记或项目,最值得展示什么
Section titled “如果把它做成笔记或项目,最值得展示什么”最值得展示的通常不是:
- 一行“用了 attention”
而是:
- 输入序列
- 当前输出位置
- 各输入位置的权重
- 哪些位置被重点关注
这样别人一眼就能看出:
- 你理解的是注意力在“怎么对齐输入”
- 不只是知道它是个热门词
学完这一页,至少保留这张证据卡:
- 源目标
- 源文本、目标文本和任务类型
- 解码输出
- 生成的摘要、翻译、转写或序列结果
- 对齐说明
- 注意力、CTC 路径、coverage,或复制的源证据
- 失败检查
- 遗漏、重复、幻觉、对齐错误或评估薄弱
- 期望产出
- 生成文本,以及事实性或对齐性复核说明
这节最重要的是建立一个桥接直觉:
注意力机制让解码器在生成每一步时都能重新查看输入序列里最相关的位置,从而缓解固定编码向量的信息瓶颈。
只要这层理解清楚,你后面再学 Transformer 的自注意力就会轻松很多。
这节最该带走什么
Section titled “这节最该带走什么”- 注意力不是小技巧,而是在改变模型访问输入信息的方式
- 它最重要的价值是缓解固定编码的信息瓶颈
- 这节一旦看懂,后面 Transformer 会顺很多
- 改一改
query,看看注意力权重会如何变化。 - 用自己的话解释:为什么 Seq2Seq 会需要“动态看输入”而不是只看固定向量?
weights为什么要经过 softmax?- 想一想:这节的注意力和后面 Transformer 的自注意力,核心相同点是什么?
参考实现与讲解
- 改变
query会改变哪些 source vectors 得到高 attention;要看 weights,而不只看最终 context vector。 - Seq2Seq 需要动态查看输入,因为不同输出步骤通常依赖不同源词。
- softmax 让权重为正且归一化,使 context vector 成为更容易解释和训练的加权混合。
- 它和 Transformer self-attention 的共同核心是 query-key-value 匹配:通过比较表示来选择相关信息。