10.3.4 YOLO 系列
- 理解 YOLO 属于哪类检测器
- 理解单阶段检测和两阶段检测的主要差别
- 理解置信度、框筛选和 NMS 的基本作用
- 建立 YOLO 在工程部署里的价值判断
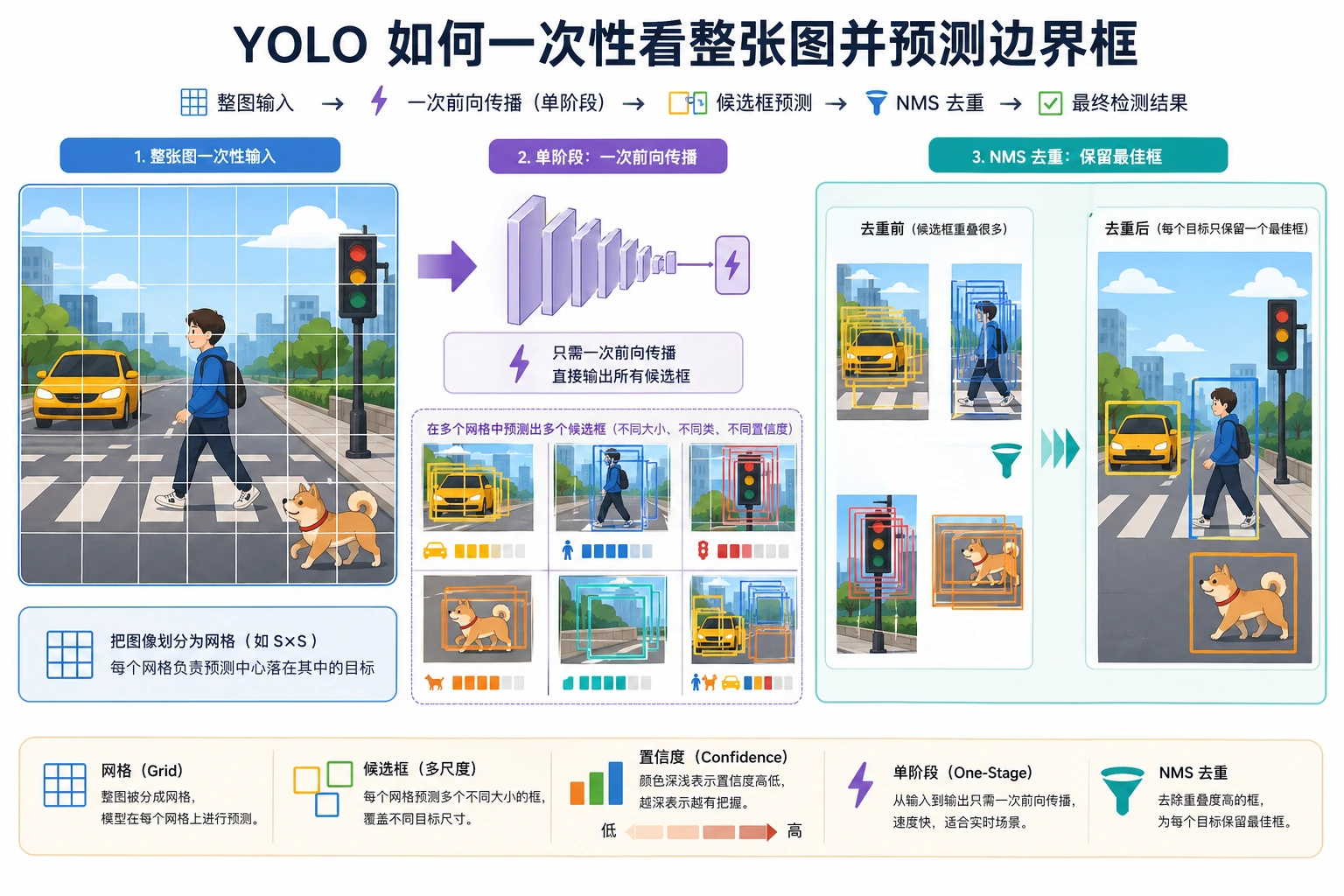
一、YOLO 的核心思路是什么?
Section titled “一、YOLO 的核心思路是什么?”YOLO 想做的是:
- 不分两步
- 直接从图像一次性输出类别和框
为什么这很有吸引力?
Section titled “为什么这很有吸引力?”因为它减少了:
- 额外 proposal 阶段
- 更复杂的检测流水线
所以更容易做到:
- 实时
两阶段检测像先圈可疑区域,再派人逐一核查。 YOLO 更像一眼扫过去,同时报出:
- 哪有目标
- 是什么
二、YOLO 的输出大致长什么样?
Section titled “二、YOLO 的输出大致长什么样?”通常可以粗略理解成一组候选框,每个候选都带:
- 类别
- 置信度
- 边界框坐标
后面再通过筛选和 NMS,得到最终结果。
一个更适合新人的类比
Section titled “一个更适合新人的类比”可以先把 YOLO 想成:
- 模型先扫完整张图
- 然后一次性报出“哪里像有东西、像什么、框大概在哪”
这和两阶段检测很不一样。 两阶段更像:
- 先到处圈可疑区域
- 再对每个区域做细查
而 YOLO 更像:
一眼看完,再把候选目标整体报出来。
一个很适合初学者先记的判断表
Section titled “一个很适合初学者先记的判断表”| 你现在关心什么 | 更值得先看哪一层 |
|---|---|
| 为什么它快 | 单阶段路线和短推理链 |
| 为什么会有一堆框 | 候选框输出 |
| 为什么结果会重叠 | NMS 和阈值 |
| 为什么实时项目爱用它 | 工程部署和生态成熟度 |
这个表很适合新人,因为它会把 YOLO 从“版本名集合”重新变成几个具体问题。
一个最小“候选框输出”示意
Section titled “一个最小“候选框输出”示意”下面这个例子不是在模拟真实 YOLO 网络, 而是在帮你建立一个很关键的直觉:
- 模型输出通常不是“最终答案”
- 而是一批带分数的候选框
predictions = [ {"class": "person", "score": 0.93, "box": (12, 18, 80, 160)}, {"class": "person", "score": 0.87, "box": (15, 20, 82, 158)}, {"class": "dog", "score": 0.78, "box": (120, 60, 190, 150)},]
for pred in predictions: print(pred)预期输出:
{'class': 'person', 'score': 0.93, 'box': (12, 18, 80, 160)}{'class': 'person', 'score': 0.87, 'box': (15, 20, 82, 158)}{'class': 'dog', 'score': 0.78, 'box': (120, 60, 190, 150)}前两个框都是 person 候选,而且位置很接近。下面的 NMS 示例正是用来处理这种情况。
这段输出最值得先记住的不是字段名, 而是:
- 单阶段检测经常天然会吐出很多候选
- 后处理本来就是检测链的一部分
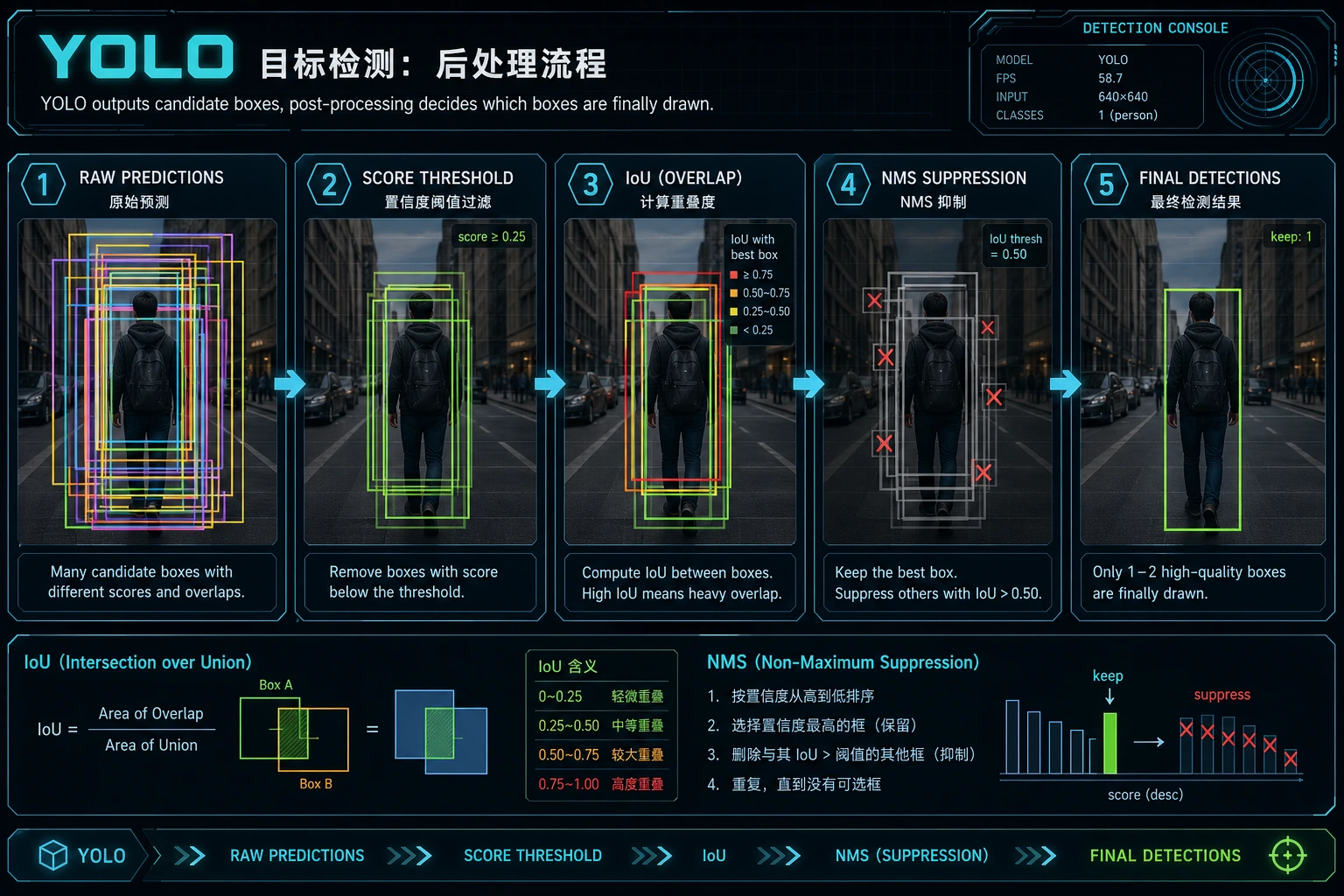
三、先跑一个最小 NMS 直觉示例
Section titled “三、先跑一个最小 NMS 直觉示例”def iou(box_a, box_b): ax1, ay1, ax2, ay2 = box_a bx1, by1, bx2, by2 = box_b
inter_x1 = max(ax1, bx1) inter_y1 = max(ay1, by1) inter_x2 = min(ax2, bx2) inter_y2 = min(ay2, by2)
inter_w = max(0, inter_x2 - inter_x1) inter_h = max(0, inter_y2 - inter_y1) inter_area = inter_w * inter_h
area_a = (ax2 - ax1) * (ay2 - ay1) area_b = (bx2 - bx1) * (by2 - by1) union = area_a + area_b - inter_area return inter_area / union if union > 0 else 0.0
predictions = [ {"box": (10, 10, 30, 30), "score": 0.95}, {"box": (12, 12, 31, 31), "score": 0.88}, {"box": (60, 60, 90, 90), "score": 0.91},]
def nms(preds, iou_threshold=0.5): preds = sorted(preds, key=lambda x: x["score"], reverse=True) kept = []
while preds: best = preds.pop(0) kept.append(best) preds = [ pred for pred in preds if iou(best["box"], pred["box"]) < iou_threshold ]
return kept
print(nms(predictions))预期输出:
[{'box': (10, 10, 30, 30), 'score': 0.95}, {'box': (60, 60, 90, 90), 'score': 0.91}]中间那个框被移除,是因为它和分数最高的第一个框重叠太多。第三个框被保留,是因为它离得很远,更像另一个目标。
这个例子最关键的价值是什么?
Section titled “这个例子最关键的价值是什么?”它说明检测输出并不是直接就能用。 很多时候模型会给出:
- 一堆重叠候选框
而 NMS 的作用就是:
- 保留最有代表性的那几个
为什么这对 YOLO 特别重要?
Section titled “为什么这对 YOLO 特别重要?”因为 YOLO 这种单阶段路线天然会产生很多候选, 后处理筛选就是整个检测链的一部分。
再看一个最小“阈值先筛一轮”示例
Section titled “再看一个最小“阈值先筛一轮”示例”predictions = [ {"class": "person", "score": 0.93}, {"class": "person", "score": 0.48}, {"class": "dog", "score": 0.78},]
def filter_by_score(preds, threshold=0.5): return [pred for pred in preds if pred["score"] >= threshold]
print(filter_by_score(predictions, threshold=0.5))预期输出:
[{'class': 'person', 'score': 0.93}, {'class': 'dog', 'score': 0.78}]低分的 person 候选被移除了。真实项目里,调整这个阈值会直接影响漏检和误检之间的平衡。
这个示例很适合初学者,因为它会帮助你看到:
- 检测系统通常不是直接拿全部候选去画框
- 而是会先用分数和规则筛一轮
四、为什么 YOLO 在工程上这么受欢迎?
Section titled “四、为什么 YOLO 在工程上这么受欢迎?”很多场景直接要求:
- 摄像头实时检测
- 边缘设备快速响应
YOLO 这类路线很适合这种需求。
结构相对统一
Section titled “结构相对统一”对很多工程同学来说,它比复杂多阶段管线更容易落地。
社区和工程生态成熟
Section titled “社区和工程生态成熟”这让它在真实项目里更常被优先尝试。
第一次做实时检测项目时,为什么很多团队会先试 YOLO?
Section titled “第一次做实时检测项目时,为什么很多团队会先试 YOLO?”因为 YOLO 往往同时满足了几个很现实的条件:
- 上手快
- 推理链短
- 社区模型多
- 部署资料多
也就是说,它的吸引力不只是精度, 而是:
它特别容易先跑出一个“工程上能看见效果”的版本。
如果把 YOLO 放进项目里,最值得先展示什么
Section titled “如果把 YOLO 放进项目里,最值得先展示什么”最值得展示的通常不是:
- 只贴一张检测效果图
而是:
- baseline 检测结果
- 阈值调整前后对比
- NMS 前后框变化
- 误检、漏检、小目标案例
这样别人会更容易看出:
- 你理解的是检测链路
- 不只是调用了一个现成模型
五、最容易踩的坑
Section titled “五、最容易踩的坑”误区一:YOLO 就等于目标检测
Section titled “误区一:YOLO 就等于目标检测”YOLO 是重要路线,但不是全部。
误区二:速度快就一定最适合
Section titled “误区二:速度快就一定最适合”还要看:
- 小目标表现
- 框定位质量
- 部署约束
误区三:后处理不重要
Section titled “误区三:后处理不重要”NMS、阈值设置这些后处理会直接影响最终体验。
六、第一次做 YOLO 项目时,最稳的默认顺序
Section titled “六、第一次做 YOLO 项目时,最稳的默认顺序”第一次把 YOLO 放进项目里,通常更稳的顺序是:
- 先把类别边界和标注规范定清楚
- 先用默认模型和默认阈值跑出 baseline
- 先看误检、漏检、小目标表现
- 再调阈值和 NMS
- 最后再考虑更换更大模型或更复杂增强
这个顺序很重要,因为很多新人最容易犯的错是:
- 一上来就换模型
- 但根本没看清 baseline 到底错在哪
一个新人可直接照抄的排查顺序
Section titled “一个新人可直接照抄的排查顺序”如果 YOLO 项目效果不理想,更稳的排查顺序通常是:
- 先看类别边界和标注规范
- 再看 score threshold 和 NMS
- 再看误检 / 漏检主要集中在哪类目标
- 最后再考虑换更大模型或更复杂增强
这样通常比直接换版本号更有效。
学完这一页,至少保留这张证据卡:
- 输入图像
- 带有真实或期望目标的检测样本
- 预测
- 框、标签、置信分数、IoU 和阈值设置
- 指标
- 精确率/召回率、mAP、误报和漏报
- 失败检查
- 小目标、重叠、NMS、标签差或置信度阈值问题
- 期望产出
- 带标注的图片,以及检测指标或错误分组
这节最重要的是建立一个工程判断:
YOLO 代表的是单阶段、实时友好的检测路线,它之所以广泛流行,不只是因为“能检测”,而是因为“更容易在工程里快速检测”。
这节最该带走什么
Section titled “这节最该带走什么”- YOLO 最重要的不是版本号,而是它代表的单阶段实时路线
- 它的输出通常是一批候选框,后处理是检测链的一部分
- 第一次做项目时,先把 baseline 的误检和漏检看清,再谈模型升级
- 调整示例里的
iou_threshold,看看保留框数如何变化。 - 用自己的话解释:为什么单阶段检测更容易做到实时?
- 为什么 NMS 对检测任务很重要?
- 想一想:什么时候你可能不会优先选 YOLO?
解题思路与讲解
- 在 NMS 里,
iou_threshold越高,通常抑制越不严格,留下的重叠框可能更多;阈值越低,抑制越激进。 - 一阶段检测更容易做到实时,因为框和类别在一次前向传播中直接预测,不需要单独的 proposal 阶段。
- NMS 很重要,因为检测器常会为同一个目标输出多个重叠框。NMS 会保留最可信的框,并去掉重复框。
- 如果项目更看重严格的小目标精度、精细定位、严重遮挡处理,或非实时的高精度复核,就不一定优先选 YOLO。