7.5.6 实操:Prompt 评测实验室
到这里,你已经学过 Prompt 基础、高级技巧、结构化输出和 Prompt 实战。下一步不是继续问“这个 Prompt 感觉是不是更好”,而是换成更工程化的问题:
同一批固定测试样例跑下来,哪个 Prompt 版本更稳定通过,为什么?
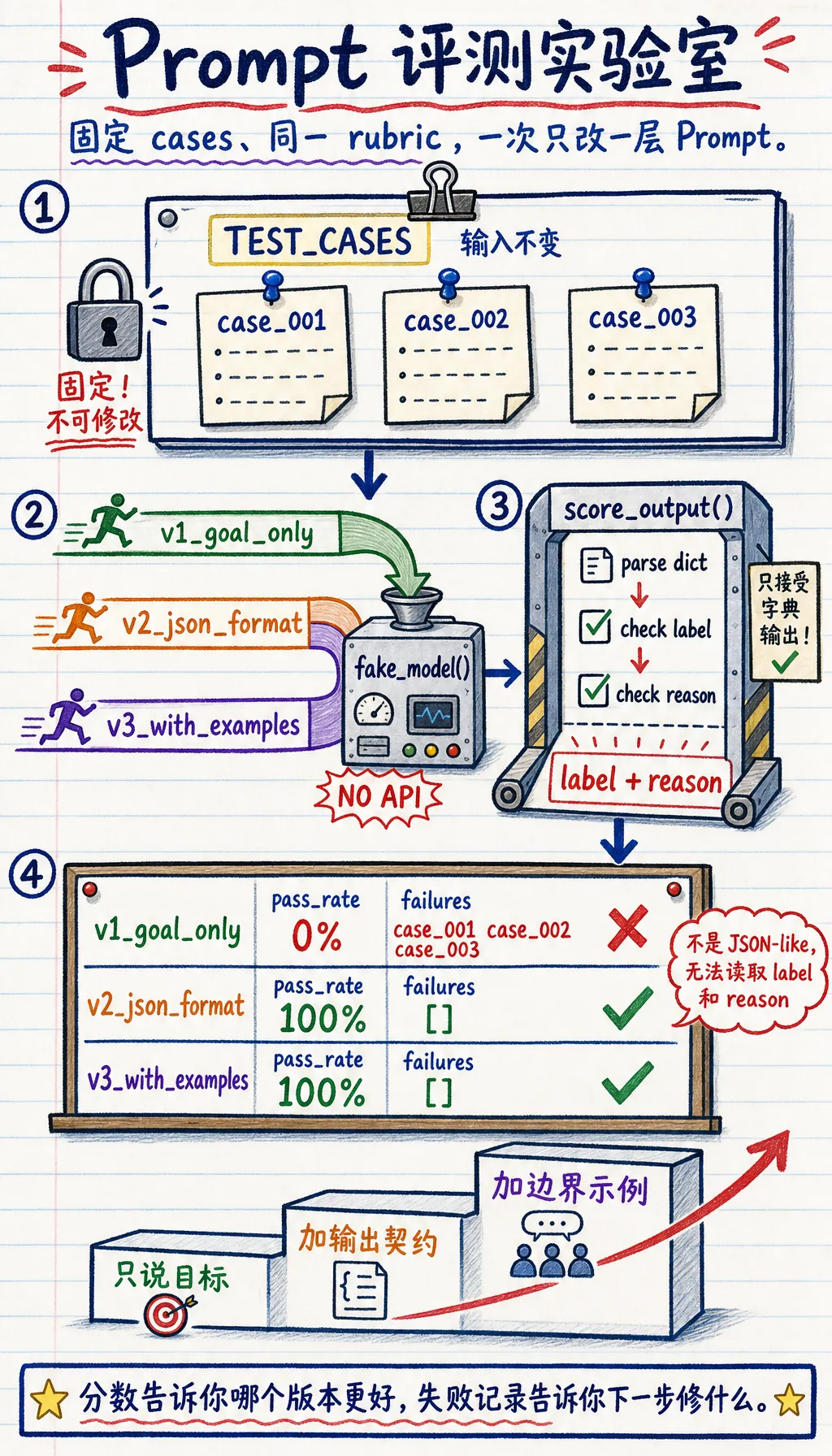
这一节补上什么能力
Section titled “这一节补上什么能力”前面几节教你怎样写更清晰的 Prompt,这一节教你怎样评测它。
核心流程是:
- 准备固定测试样例。
- 准备多个 Prompt 版本。
- 用每个版本跑同一批样例。
- 用同一套评分规则给输出打分。
- 记录失败样例,并决定下一步怎么改。
这就是 Prompt 回归测试的最小实践版。
先澄清几个术语
Section titled “先澄清几个术语”| 术语 | 通俗解释 | 为什么重要 |
|---|---|---|
| 测试样例 | 固定输入加上期望行为 | 避免只凭一个幸运样例判断 Prompt |
| 期望输出 | 好答案应该包含或满足的内容 | 把“看起来不错”变成可检查标准 |
| 评分量规(Rubric) | 评分规则 | 保证不同 Prompt 版本用同一标准比较 |
| 通过率 | 通过样例数除以总样例数 | 用简单指标比较版本 |
| 回归 | 新 Prompt 修好一个样例,却弄坏旧样例 | 所以旧测试样例必须保留 |
| 失败记录 | 记录失败现象和原因 | 把错误转成下一轮优化方向 |
跑一个完全离线的评测实验室
Section titled “跑一个完全离线的评测实验室”下面示例不会调用真实模型,而是用模拟模型帮助你专注理解评测闭环本身。保存为 prompt_eval_lab.py,然后运行:
python prompt_eval_lab.pyTEST_CASES = [ { "id": "case_001", "user_input": "The course is clear and the examples are practical.", "expected_label": "positive", "must_be_json": True, }, { "id": "case_002", "user_input": "The chapter jumps too fast and I feel lost.", "expected_label": "negative", "must_be_json": True, }, { "id": "case_003", "user_input": "The explanation is okay, but the code example does not run.", "expected_label": "negative", "must_be_json": True, },]
PROMPT_VERSIONS = { "v1_goal_only": "Classify the sentiment of the review.", "v2_json_format": ( "Classify the sentiment of the review. " "Return JSON with fields: label, reason." ), "v3_with_examples": ( "Classify the sentiment of the review. " "Return JSON with fields: label, reason. " "Examples: clear and practical -> positive; too fast and lost -> negative." ),}
def fake_model(prompt_version, user_input): text = user_input.lower()
if prompt_version == "v1_goal_only": if "clear" in text or "practical" in text: return "positive" return "negative"
if prompt_version == "v2_json_format": if "clear" in text or "practical" in text: return {"label": "positive", "reason": "The review praises clarity or practicality."} return {"label": "negative", "reason": "The review describes a learning problem."}
if "does not run" in text: return {"label": "negative", "reason": "Broken code blocks learning progress."} if "clear" in text or "practical" in text: return {"label": "positive", "reason": "The review praises useful teaching design."} return {"label": "negative", "reason": "The review describes confusion or frustration."}
def score_output(case, output): format_ok = isinstance(output, dict) and "label" in output and "reason" in output if not format_ok: return { "passed": False, "format_ok": False, "label_ok": False, "reason": "Output is not parseable JSON-like data.", }
label_ok = output["label"] == case["expected_label"] reason_ok = isinstance(output["reason"], str) and len(output["reason"]) >= 10 passed = format_ok and label_ok and reason_ok
return { "passed": passed, "format_ok": format_ok, "label_ok": label_ok, "reason": "ok" if passed else "Label or explanation did not meet the rubric.", }
def run_eval(): report = []
for version in PROMPT_VERSIONS: passed = 0 failures = []
for case in TEST_CASES: output = fake_model(version, case["user_input"]) score = score_output(case, output) passed += int(score["passed"]) if not score["passed"]: failures.append( { "case_id": case["id"], "output": output, "reason": score["reason"], } )
pass_rate = passed / len(TEST_CASES) report.append({"version": version, "pass_rate": pass_rate, "failures": failures})
return report
for row in run_eval(): print("-" * 60) print("version :", row["version"]) print("pass_rate:", f"{row['pass_rate']:.0%}") print("failures :", row["failures"])预期输出:
------------------------------------------------------------version : v1_goal_onlypass_rate: 0%failures : [{'case_id': 'case_001', 'output': 'positive', 'reason': 'Output is not parseable JSON-like data.'}, {'case_id': 'case_002', 'output': 'negative', 'reason': 'Output is not parseable JSON-like data.'}, {'case_id': 'case_003', 'output': 'negative', 'reason': 'Output is not parseable JSON-like data.'}]------------------------------------------------------------version : v2_json_formatpass_rate: 100%failures : []------------------------------------------------------------version : v3_with_examplespass_rate: 100%failures : []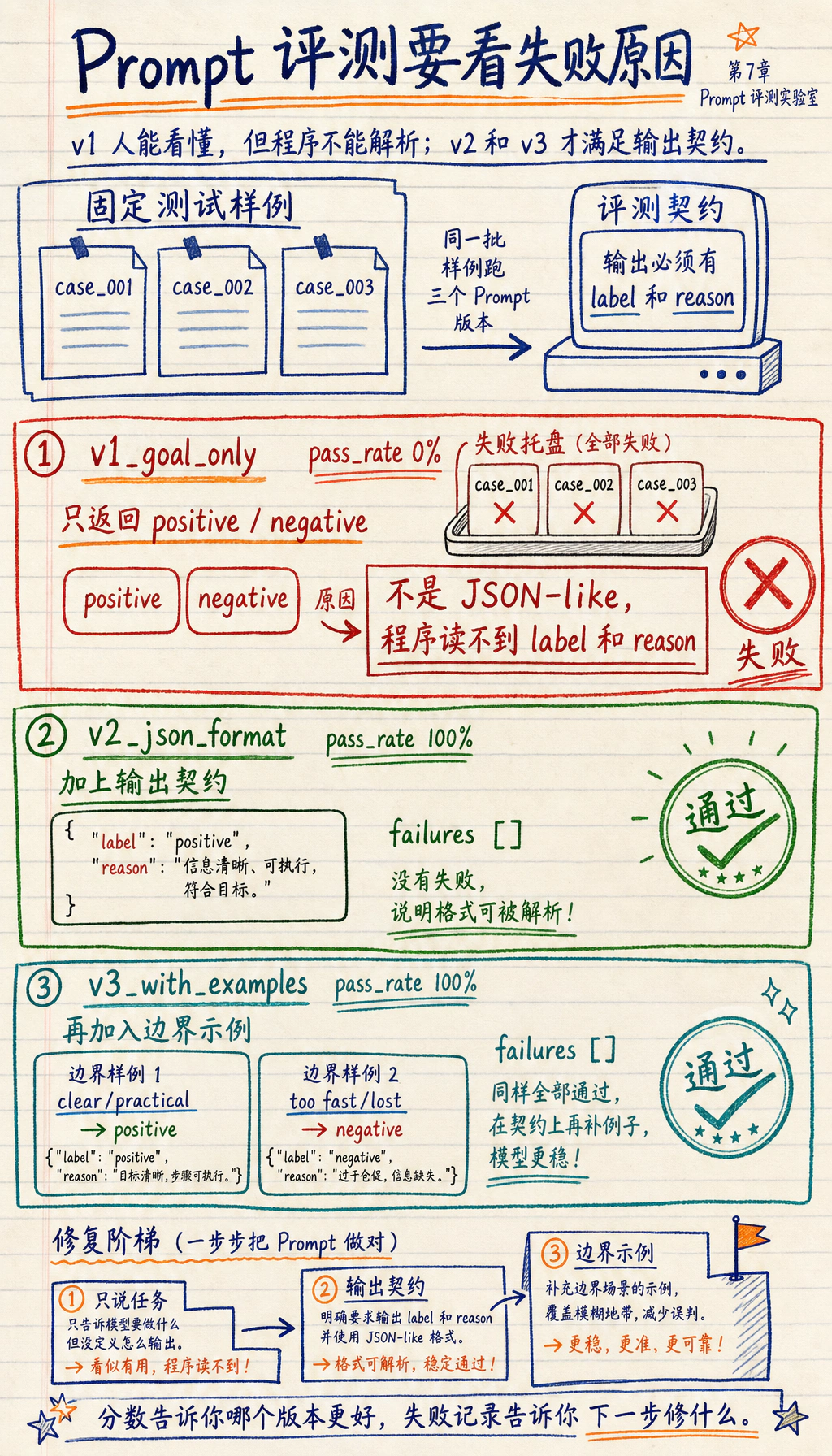
v1 可能分类正确,但仍然不满足产品要求
Section titled “v1 可能分类正确,但仍然不满足产品要求”v1_goal_only 返回了标签,但没有返回类似 JSON 的可解析数据。如果下游程序需要 label 和 reason,即使语义上分类正确,这个输出仍然失败。
这是一个重要工程经验:
模型回答人能看懂,不代表程序能稳定使用。
v2 修复格式问题
Section titled “v2 修复格式问题”v2_json_format 增加了输出字段,所以程序可以读取 label 和 reason。这对应真实 Prompt 调试:先把任务说清楚,再把输出契约说清楚。
v3 用示例处理边界情况
Section titled “v3 用示例处理边界情况”v3_with_examples 适合边界模糊的任务。真实项目中,当标签差异很微妙时,示例特别有价值,例如 bug_report 和 learning_confusion,或 refund_policy 和 after_sales。
不只记录分数,还要记录失败原因
Section titled “不只记录分数,还要记录失败原因”通过率告诉你哪个版本更好,失败记录告诉你下一步该修什么。
可以在项目 README 里放这样的小表:
| Prompt 版本 | 失败类型 | 证据 | 下一步修复 |
|---|---|---|---|
| v1 | 格式失败 | 输出是纯文本 | 要求 JSON 字段 |
| v2 | 边界风险 | 混合评价可能误判 | 增加 2-3 个边界示例 |
| v3 | 仍未覆盖 | 还没有长文本样例 | 增加长文本和噪声输入 |
这个习惯很重要,否则 Prompt 工作很容易变成一团“感觉还行”的雾。
后面怎样换成真实模型评测
Section titled “后面怎样换成真实模型评测”当你把 fake_model() 换成真实模型调用时,尽量保持其他评测流程稳定。
不要一次同时改变:
- 模型
- 提示词(Prompt)
- 测试样例
- 评分规则
- 输出 结构约束
如果变量一起变,你就很难解释结果。
学完这一页,至少保留这张证据卡:
- 评估用例
- 固定输入集
- 提示词版本
- 基线提示词和改进提示词
- 评分表
- 通过率或评分量表分数
- 失败备注
- 一个失败输出及其可能原因
- 下一步
- 加入更难的案例或连接一个真实模型
- 增加两个测试样例:一个非常短的输入,一个长的混合评价输入。
- 增加
confidence字段,并更新评分函数要求它存在。 - 让
v2_json_format在某个边界样例上失败,并写一条失败记录。 - 只有在离线闭环跑清楚后,再把
fake_model()替换成你自己的 LLM 调用。 - 把 report 输出保存进项目笔记,作为 Prompt 评测证据。
项目交付参考与讲解
- 很短输入用于测试 prompt 面对稀疏信息时是否稳定;长的混合评价用于测试它能否拆分多个情绪或主题。
- 加入
confidence后,schema 和评分函数都应该要求它存在,否则模型仍可以省略重要的不确定性信号。 - 有用的失败记录应包含输入、prompt 版本、错误输出、可能原因和下一步改动。目标是从失败中学习,不是掩盖失败。
- 先保留
fake_model()可以让评测循环保持确定性。测试集、评分和报告稳定后,再接真实 LLM。 - 保存的报告应包含测试样例、prompt 版本、分数、失败样例和下一轮实验计划,这才是 prompt 评测证据。
Prompt 工程不只是写一条更好的指令。更成熟的流程是:
固定测试集、一次只改一层 Prompt、用同一套 Rubric 给输出打分,并记录失败证据。
当你能做到这一点,就不再是凭感觉调 Prompt,而是在搭建一个小型、可重复的 Prompt 评测系统。