E.A C++ 与模型部署路线图
当 Python 模型已经能跑,但延迟、内存、打包或服务成本变成真正问题时,再回来学这个选修模块。
先看部署路线
Section titled “先看部署路线”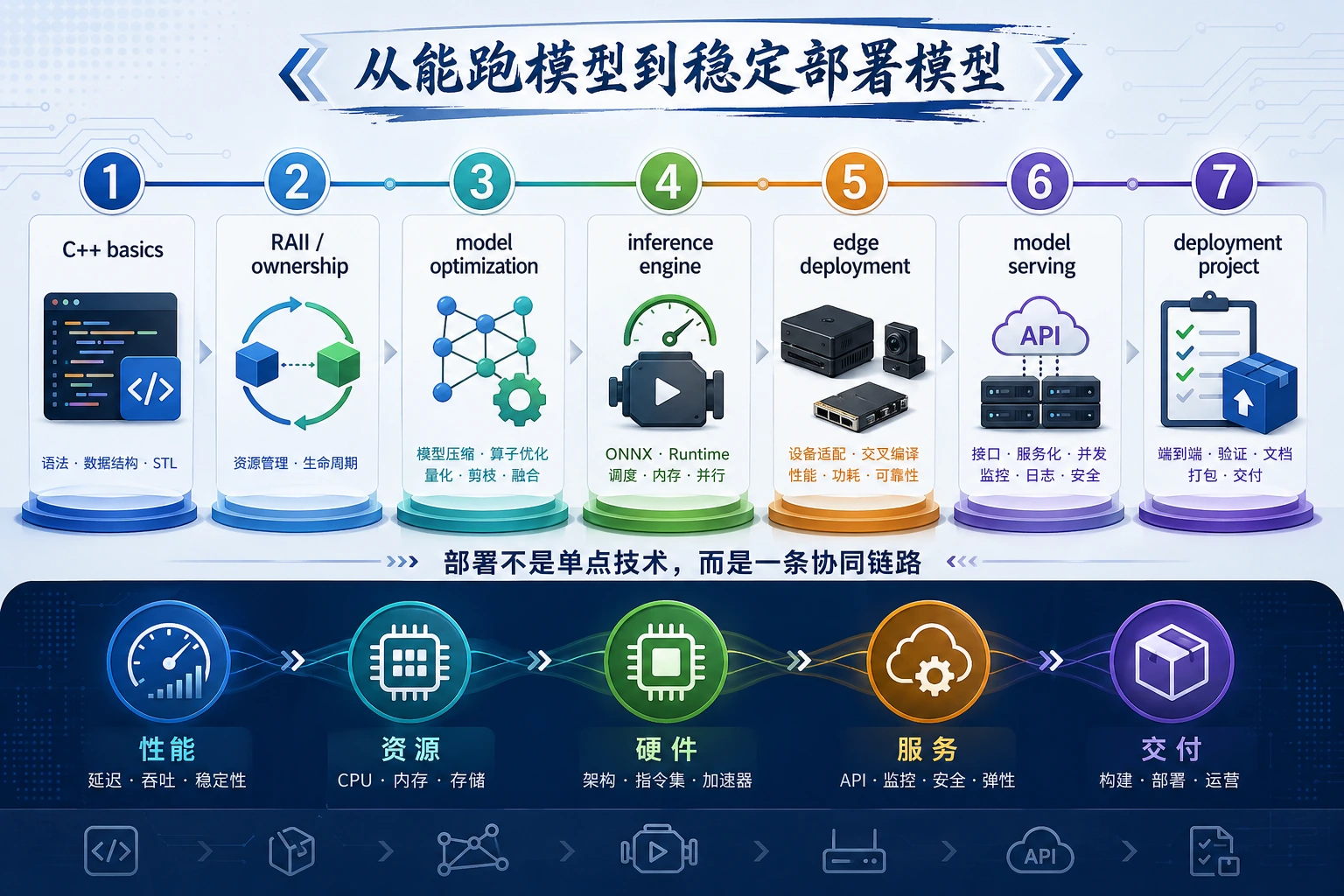
核心问题很简单:你能不能把模型输出变成快速、可度量、可部署的推理路径。
跑最小 C++ 推理步骤
Section titled “跑最小 C++ 推理步骤”创建 demo.cpp:
#include <iostream>#include <vector>
int main() { std::vector<float> logits = {1.2f, 0.3f, 2.1f}; int best_index = 0;
for (int i = 1; i < static_cast<int>(logits.size()); ++i) { if (logits[i] > logits[best_index]) { best_index = i; } }
std::cout << "best_class=" << best_index << "\n"; std::cout << "score=" << logits[best_index] << "\n"; return 0;}运行:
c++ -std=c++17 demo.cpp -o demo./demo预期输出:
best_class=2score=2.1这是最小部署习惯:输入类似 tensor 的数值,计算决策,打印可复现结果。
如何在真实项目里使用本模块
Section titled “如何在真实项目里使用本模块”把本模块当成部署评审路线,而不是 C++ 知识清单。先确认模型要运行在哪里,再看 runtime、模型格式、内存、延迟、服务接口和回滚证据。每一页都应该留下一个能被别人重跑的小产物。
如果现在只有 Python 原型,也可以先不急着重写。先记录 baseline 指标,再判断 C++、推理引擎、量化或服务化到底解决了哪个真实约束。
学习这个模块时,每一页都问同一个问题:这个动作让部署更快、更稳、更省,还是更容易排障?如果答案说不清,就先回到指标。部署学习最怕只记工具名,却没有证明工具解决了什么问题。
最终交付时,把每页证据串成一条线:约束、方案、指标、失败样本和复现命令。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 课程 | 练习产物 |
|---|---|---|
| 1 | E.A.1 C++ 基础 | 编译并运行一个小推理辅助程序 |
| 2 | E.A.2 C++ 进阶 | 解释 ownership、RAII 和安全释放资源 |
| 3 | E.A.3 模型优化 | 比较延迟、内存和精度取舍 |
| 4 | E.A.4 推理引擎 | 根据硬件和模型格式选择引擎 |
| 5 | E.A.5 边缘部署 | 说出边缘约束并导出检查表 |
| 6 | E.A.6 模型服务化 | 设计带版本和指标的服务 |
| 7 | E.A.7 项目 | 交付一个小型部署证据包 |
你能编译一个 C++ 示例,解释部署取舍,记录延迟或内存证据,并把结果接到 选修实操工作坊,就算通过本模块。
学完这一页,至少保留这张证据卡:
- 部署目标
- 本地推理、边缘设备、模型服务器或优化实验
- 工件
- C++ 代码片段、基准测试、模型工件、服务配置或部署说明
- 指标
- 延迟、内存、吞吐量、模型大小、准确率下降或可靠性
- 失败检查
- ABI/构建问题、硬件不匹配、量化损失或服务瓶颈
- 期望产出
- 可复现的部署或优化证据,而不只是理论笔记
检查思路与讲解
一个合格答案会说明为什么这里适合用 C++:更稳定的运行时、更可控的内存,以及更贴近部署目标的路径。证据可以是一次编译输出、一条延迟或内存记录,再加上一句说明它为什么能接到后续实操工作坊。
如果只写“能运行”,还不够。要把可复现产物和部署取舍一起留下来。