6.7.4 模型压缩 [选修]
- 按“改了系统哪一部分”解释量化、剪枝和蒸馏。
- 根据参数量和数值精度估算模型大小。
- 用小例子测量量化误差。
- 从部署瓶颈选择压缩路线。
- 避免只用大小判断压缩是否成功。
从部署瓶颈开始
Section titled “从部署瓶颈开始”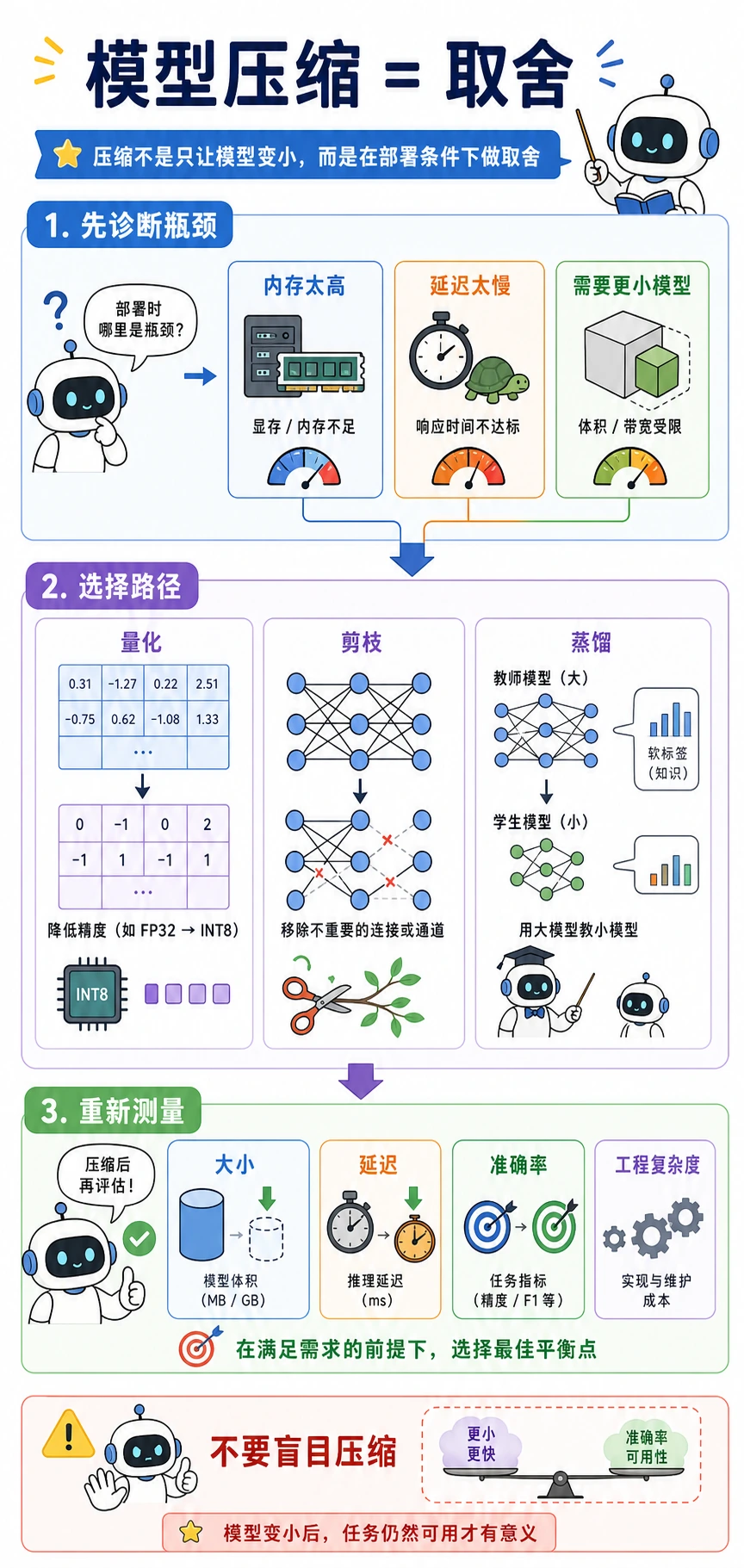
| 瓶颈 | 优先考虑 | 原因 |
|---|---|---|
| 内存太高 | 量化 | 参数数量不变,但每个值用更少 bit |
| 权重/通道明显冗余 | 剪枝 | 移除贡献小的结构 |
| 有大 teacher 且能重训 | 蒸馏 | 训练小 student 模仿行为 |
| 压缩后延迟仍高 | 先 profiling | 瓶颈可能在数据传输或不支持的 kernel |
重要习惯:
测瓶颈选方法重新测大小、延迟和指标
三条压缩路线
Section titled “三条压缩路线”| 方法 | 改变什么 | 常见收益 | 主要风险 |
|---|---|---|---|
| 量化 | 数值精度 | 更小内存,有时推理更快 | 精度下降,硬件支持问题 |
| 剪枝 | 权重、通道或 block | 真正移除结构后计算更少 | 稀疏加速不一定在所有硬件生效 |
| 蒸馏 | 训练目标 | 小模型学到 teacher 行为 | 需要重训和 teacher 输出 |
压缩完成的标准不是“文件变小”,而是压缩后任务仍然能用。
实验 1:量化误差
Section titled “实验 1:量化误差”weights = [0.12, -1.87, 3.44, -0.03]
def fake_quantize(values, scale): return [round(v * scale) / scale for v in values]
def mae(a, b): return sum(abs(x - y) for x, y in zip(a, b)) / len(a)
q8_like = fake_quantize(weights, scale=16)q4_like = fake_quantize(weights, scale=4)
print("quant_error_lab")print("original:", weights)print("q8_like:", q8_like)print("q4_like:", q4_like)print("q8_mae:", round(mae(weights, q8_like), 4))print("q4_mae:", round(mae(weights, q4_like), 4))预期输出:
quant_error_laboriginal: [0.12, -1.87, 3.44, -0.03]q8_like: [0.125, -1.875, 3.4375, 0.0]q4_like: [0.0, -1.75, 3.5, 0.0]q8_mae: 0.0106q4_mae: 0.0825量化越激进,数值误差通常越大。真正的问题是:下游任务指标是否还能接受。
实验 2:估算模型大小
Section titled “实验 2:估算模型大小”import torchfrom torch import nn
model = nn.Sequential( nn.Linear(128, 64), nn.ReLU(), nn.Linear(64, 10),)
param_count = sum(p.numel() for p in model.parameters())
print("model_size_lab")print("params:", param_count)
for name, bits in [("fp32", 32), ("fp16", 16), ("int8", 8), ("int4", 4)]: mb = param_count * bits / 8 / 1024 / 1024 print(f"{name:>4}: {mb:.4f} MB")预期输出:
model_size_labparams: 8906fp32: 0.0340 MBfp16: 0.0170 MBint8: 0.0085 MBint4: 0.0042 MB
这只是参数大小估算。真实部署体积还可能包含 metadata、tokenizer 文件、runtime 开销和推理引擎打包格式。
选择压缩路线
Section titled “选择压缩路线”| 场景 | 第一动作 |
|---|---|
| 模型放不进内存 | 先试量化 |
| 模型能放下但延迟高 | 剪枝前先 profile latency |
| 大量通道看起来冗余 | 考虑结构化剪枝 |
| 小模型必须保留大模型行为 | 用 teacher 做蒸馏 |
| 压缩后指标掉太多 | 降低压缩强度或 fine-tune |
剪枝时,部署上通常更推荐结构化剪枝,因为移除整个通道或 block 比随机稀疏权重更容易被硬件利用。
蒸馏常见模式:
teacher logits 或输出 -> student 学标签 + teacher 行为压缩实验应该报告什么
Section titled “压缩实验应该报告什么”| 指标 | 压缩前 | 压缩后 | 为什么重要 |
|---|---|---|---|
| 模型大小 | 必填 | 必填 | 内存是否改善 |
| 延迟 | 必填 | 必填 | 推理是否真的变快 |
| 吞吐 | 推荐 | 推荐 | 服务能否承载更多请求 |
| 任务指标 | 必填 | 必填 | 质量是否仍可接受 |
| 硬件/runtime | 必填 | 必填 | 压缩效果依赖部署栈 |
不要只报告“int8 可以跑”。没有任务指标和延迟,大小变小不代表成功。
压缩结果要保存为 before/after 报告:
- Compression Method
- 待填写
- Baseline Model
- 待填写
- Compressed Model
- 待填写
- Baseline Size Mb
- 待填写
- Compressed Size Mb
- 待填写
- Baseline Latency Ms
- 待填写
- Compressed Latency Ms
- 待填写
- Baseline Throughput
- 待填写
- Compressed Throughput
- 待填写
- Baseline Metric
- 待填写
- Compressed Metric
- 待填写
- Hardware
- 待填写
- Runtime
- 待填写
- Measurement Command
- 待填写
- Quality Drop Allowed
- 待填写
- Decision
- keep / adjust / reject
- Reason
- 待填写
这能避免一个常见错误:文件变小了,但真实产品反而更慢或更不准。
最重要的是 decision 和 reason。压缩不是越狠越好,而是要说明:在这个硬件和运行时上,压缩后的质量、延迟和体积是否满足产品约束。
| 错误 | 修复 |
|---|---|
| 还没测瓶颈就压缩 | 先测内存、延迟和指标 |
| 以为量化一定加速 | 验证硬件和 runtime 支持 |
| 只算参数大小 | 需要时也算 tokenizer、runtime、打包开销 |
| 用非结构化剪枝后期待自动加速 | 在目标硬件上 benchmark |
| 忽略压缩后的准确率 | 对比压缩前后的任务指标 |
- 把实验 1 中的
scale=16改成scale=32。MAE 会下降吗? - 给实验 2 加第三个 Linear 层,再重新计算模型大小。
- 如果模型能放进内存但太慢,你会优先选哪条路线?
- 写一个压缩前后报告模板,包含 size、latency、throughput 和 metric。
- 解释为什么结构化剪枝通常比非结构化剪枝更容易部署。
参考实现与讲解
scale=32通常量化更细,MAE 可能下降,但具体取决于权重分布和缩放方式。- 新增 Linear 层后,参数量按
in_features x out_features + bias逐层相加,再乘以 dtype 字节数估算大小。 - 如果瓶颈是速度,应优先考虑蒸馏、小模型结构、算子融合、批量策略或结构化剪枝,而不只是减小文件体积。
- 报告应包含压缩前后 size、latency、throughput、核心指标、硬件环境和测量方法。
- 结构化剪枝删除通道、头或层,更容易映射到真实硬件加速;非结构化稀疏需要专门 kernel 才能真正变快。
- 压缩从部署约束开始。
- 量化改变数值精度。
- 剪枝改变模型结构。
- 蒸馏改变训练过程。
- 压缩成功的标准是部署后的质量和延迟仍然满足要求。