7.4.1 预训练路线图:数据、目标、工程
预训练让模型先学到广泛语言模式。工程视角是:清理数据,选择目标,大规模训练,追踪风险。
先看预训练三角
Section titled “先看预训练三角”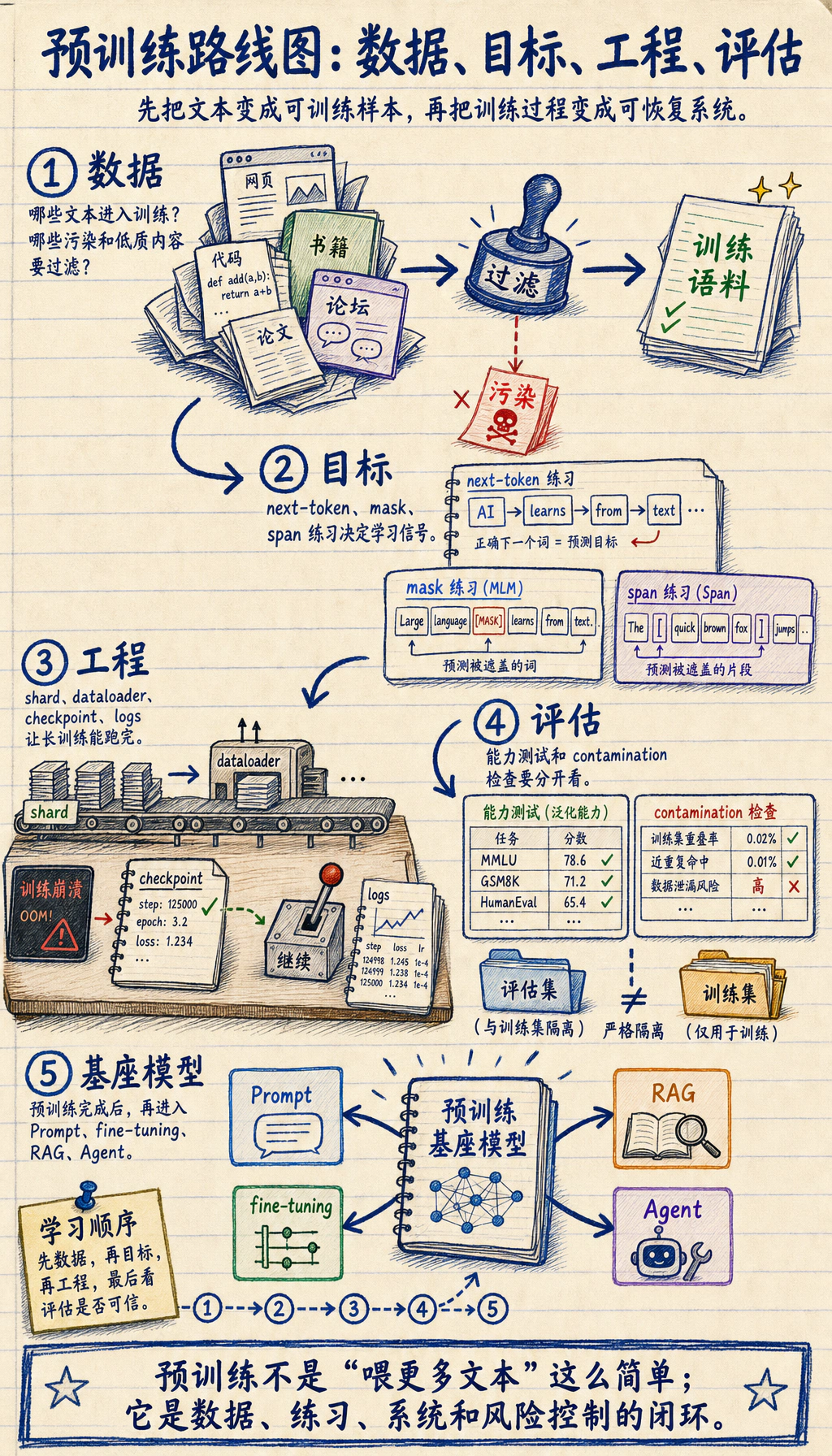
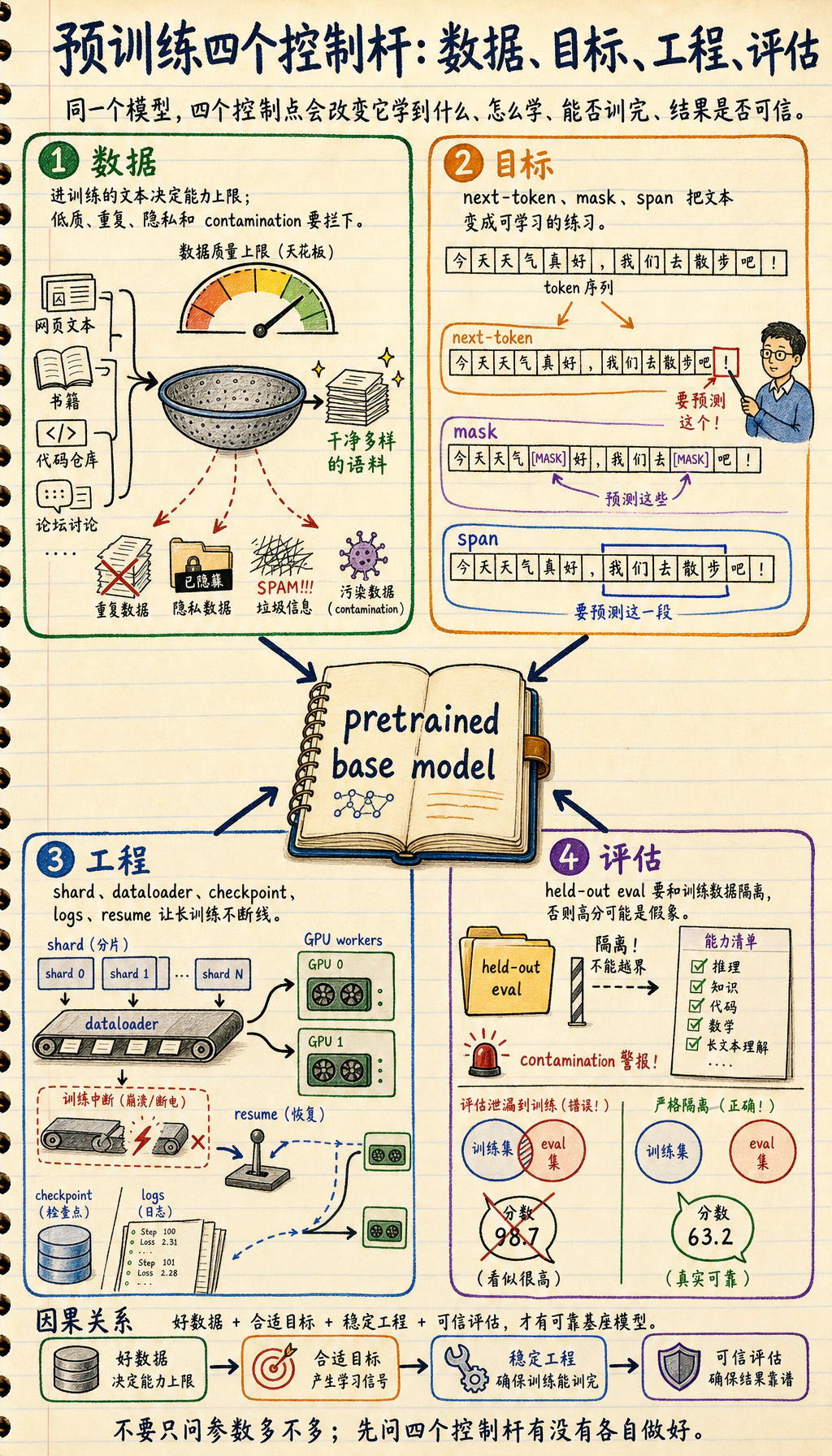
| 部分 | 先问的问题 |
|---|---|
| 数据 | 哪些文本进入训练,哪些必须过滤? |
| 目标 | 哪个预测任务产生学习信号? |
| 工程 | 规模、checkpoint、日志和失败如何处理? |
| 评估 | 模型能做什么,哪里会失败? |
创建 next-token 样本
Section titled “创建 next-token 样本”tokens = ["AI", "learns", "from", "text"]pairs = list(zip(tokens[:-1], tokens[1:]))
for source, target in pairs: print(f"{source} -> {target}")预期输出:
AI -> learnslearns -> fromfrom -> text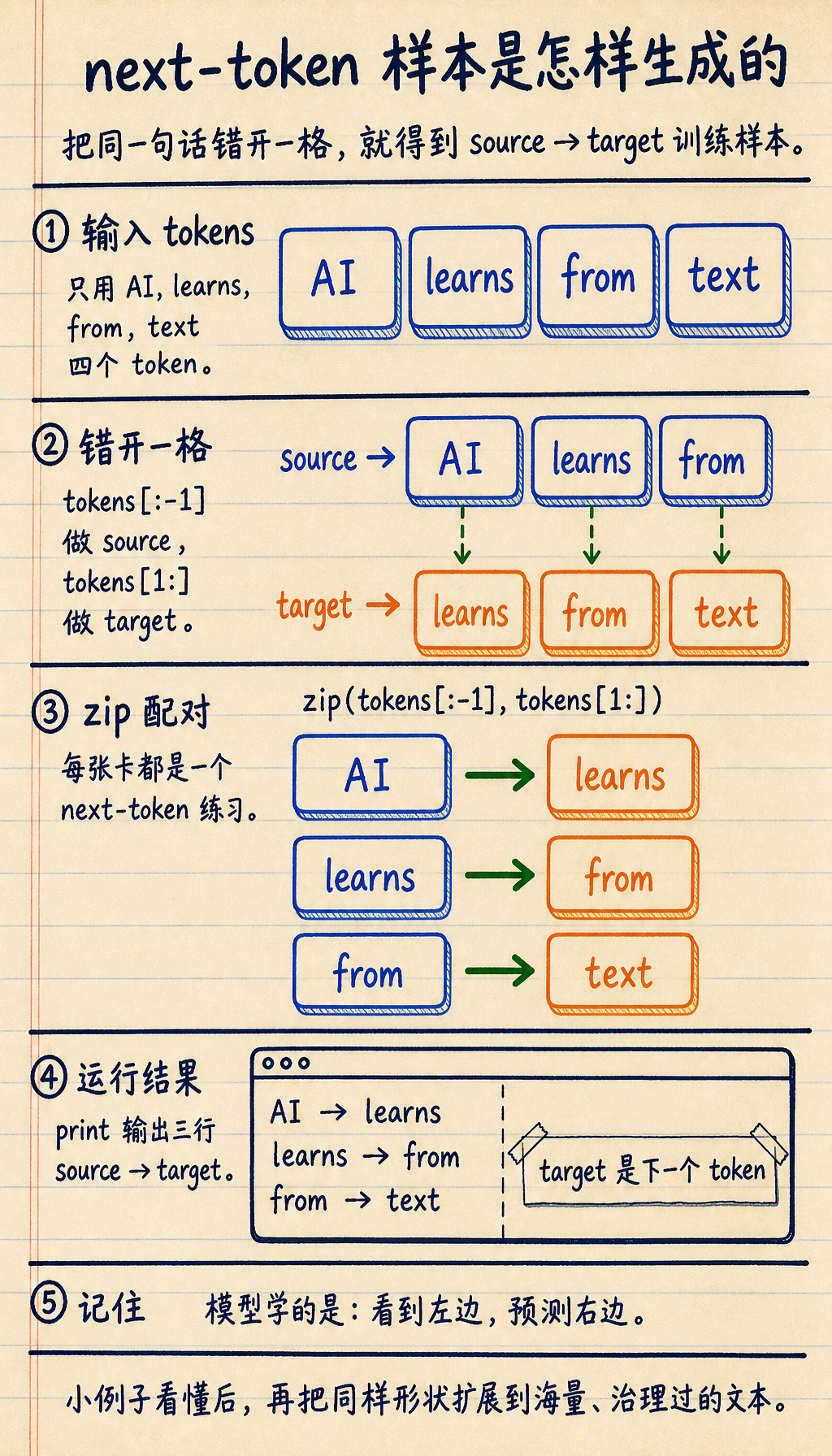
这个小例子就是 next-token prediction 的形状。真实预训练会把它扩展到海量文本,并配合严格的数据治理。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 7.4.2 预训练数据 | 来源、过滤、去重、污染 |
| 2 | 7.4.3 预训练方法 | next-token prediction、loss、scaling |
| 3 | 7.4.4 预训练工程 | 分布式训练、checkpoint、监控 |
| 4 | 7.4.5 租 GPU 训练手搓 GPT-2 | 选平台、开环境、用 device: cuda 逐行跑通 mini GPT-2 |
学完这一页,至少保留这张证据卡:
- 三角关系
- 数据、目标和工程都很重要
- 样本对
- 来自同一句话的下一个 token 训练对
- 数据风险
- 污染、重复或低质量混合
- 目标说明
- 目标决定行为和架构匹配
- 工程说明
- 分片、断点续训、吞吐量和监控
- 实操桥接
- 能在免费或低价 GPU 上跑通一个 mini GPT-2 训练脚本
能解释数据、目标和工程分别如何影响最终模型,知道数据污染为什么会让评估误导人,并说清为什么 mini GPT-2 实验里 CPU 只是冒烟测试、device: cuda 才是正式训练证据,就算通过。
检查思路与讲解
- 合格答案要说明 token、上下文、attention、prompt 和生成行为如何组成一次请求到回答的路径。
- 证据至少包含一个可复现 prompt 或结构化输出测试,并说明输出为什么通过或失败。
- 自检时要区分 prompt、RAG、微调和对齐:优先使用能解决已观察问题的最轻方案。