11.4.5 NER 实战
- 学会定义一个最小 NER 项目边界
- 学会从 token 标签恢复实体
- 学会做实体级别错误分析
- 通过可运行示例建立信息抽取项目骨架
先建立一张地图
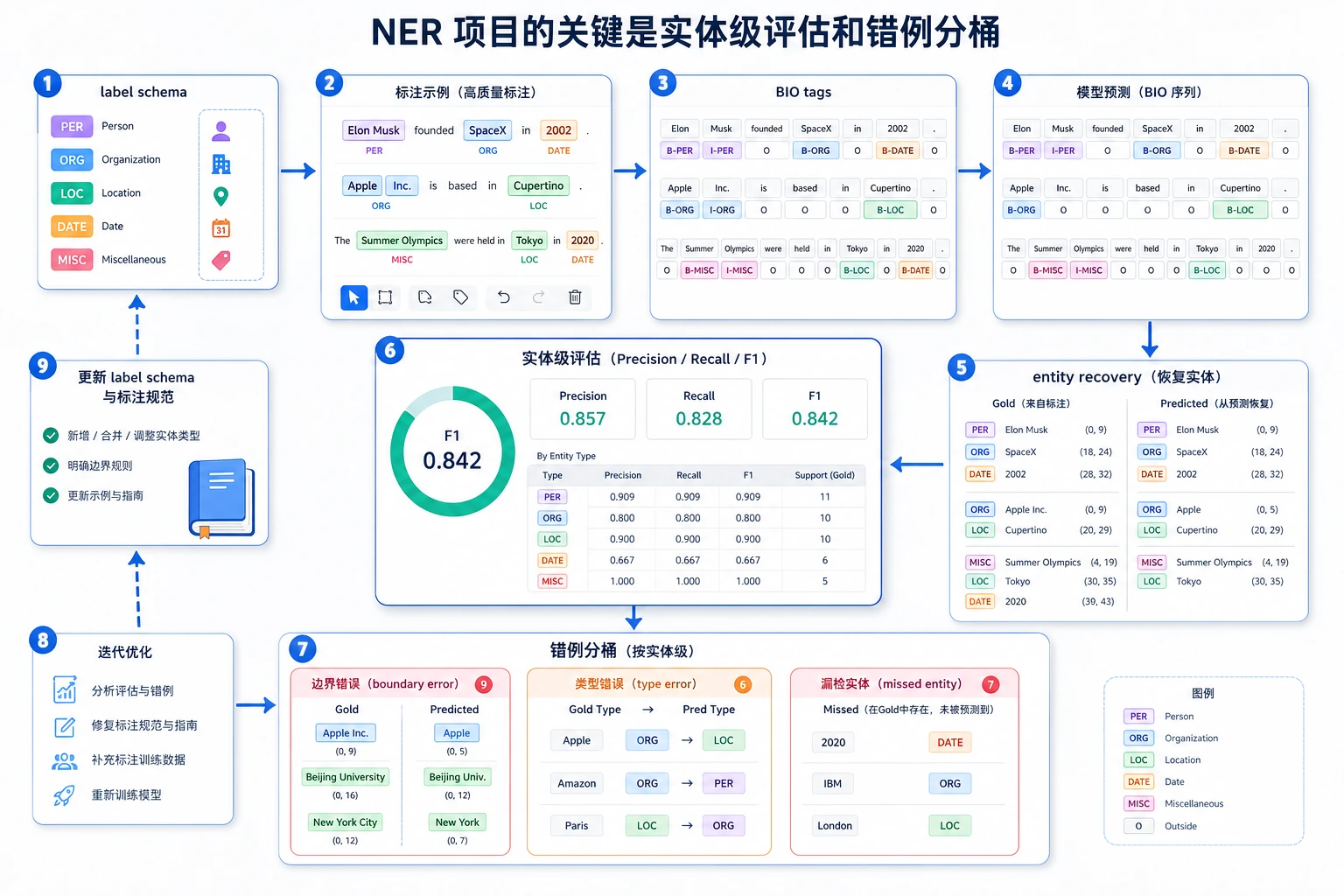
Section titled “先建立一张地图”NER 实战更适合按“标签 -> 实体 -> 评估 -> 迭代”的顺序理解:
flowchart LR A["定义实体类型"] --> B["设计 BIO 标签"] B --> C["模型输出标签序列"] C --> D["恢复实体 span"] D --> E["做实体级评估和错例分析"]所以这节真正想解决的是:
- NER 项目为什么不只是“标签预测”
- 为什么实体恢复和错误分析才更像真实项目
一、项目问题先要定义清楚
Section titled “一、项目问题先要定义清楚”输入:
- 一段简历或候选人简介文本
输出:
- 姓名
- 学校
- 技能
为什么这比“随便抽点实体”更适合练手?
Section titled “为什么这比“随便抽点实体”更适合练手?”因为它边界清楚:
- 类别数不多
- 实体类型明确
- 结果很容易做业务解释
第一个关键点不是模型,而是标签体系
Section titled “第一个关键点不是模型,而是标签体系”例如:
张三->B-NAME清华大学->B-SCHOOL I-SCHOOL ...Python->B-SKILL
这一步一旦含糊,后面模型和评估都会一起乱。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 NER 想成:
- 在一段文字里拿荧光笔圈重点信息
难点不只是“圈出来”,而是:
- 从哪里开始圈
- 到哪里结束
- 这一段到底属于哪一类
这样理解后,为什么 NER 特别容易卡在边界问题,就会自然很多。
二、先做一个可运行标注与解码闭环
Section titled “二、先做一个可运行标注与解码闭环”下面这个示例会做三件事:
- 准备一个小型样本
- 把 BIO 标签解码成实体
- 做简单的预测对比与错误分析
samples = [ { "tokens": ["张三", "毕业于", "清华大学", ",", "熟悉", "Python", "和", "PyTorch"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], }, { "tokens": ["李四", "来自", "北京大学", ",", "掌握", "Java"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "O", "O", "O", "B-SKILL"], },]
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1)
if prefix == "B": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token) else: if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type
if current_tokens: entities.append(("".join(current_tokens), current_type))
return entities
for sample in samples: gold_entities = decode_entities(sample["tokens"], sample["gold_tags"]) pred_entities = decode_entities(sample["tokens"], sample["pred_tags"])
print("tokens:", sample["tokens"]) print("gold :", gold_entities) print("pred :", pred_entities) print("miss :", [x for x in gold_entities if x not in pred_entities]) print()预期输出:
tokens: ['张三', '毕业于', '清华大学', ',', '熟悉', 'Python', '和', 'PyTorch']gold : [('张三', 'NAME'), ('清华大学', 'SCHOOL'), ('Python', 'SKILL'), ('PyTorch', 'SKILL')]pred : [('张三', 'NAME'), ('清华大学', 'SCHOOL'), ('Python', 'SKILL'), ('PyTorch', 'SKILL')]miss : []
tokens: ['李四', '来自', '北京大学', ',', '掌握', 'Java']gold : [('李四', 'NAME'), ('北京大学', 'SCHOOL'), ('Java', 'SKILL')]pred : [('李四', 'NAME'), ('Java', 'SKILL')]miss : [('北京大学', 'SCHOOL')]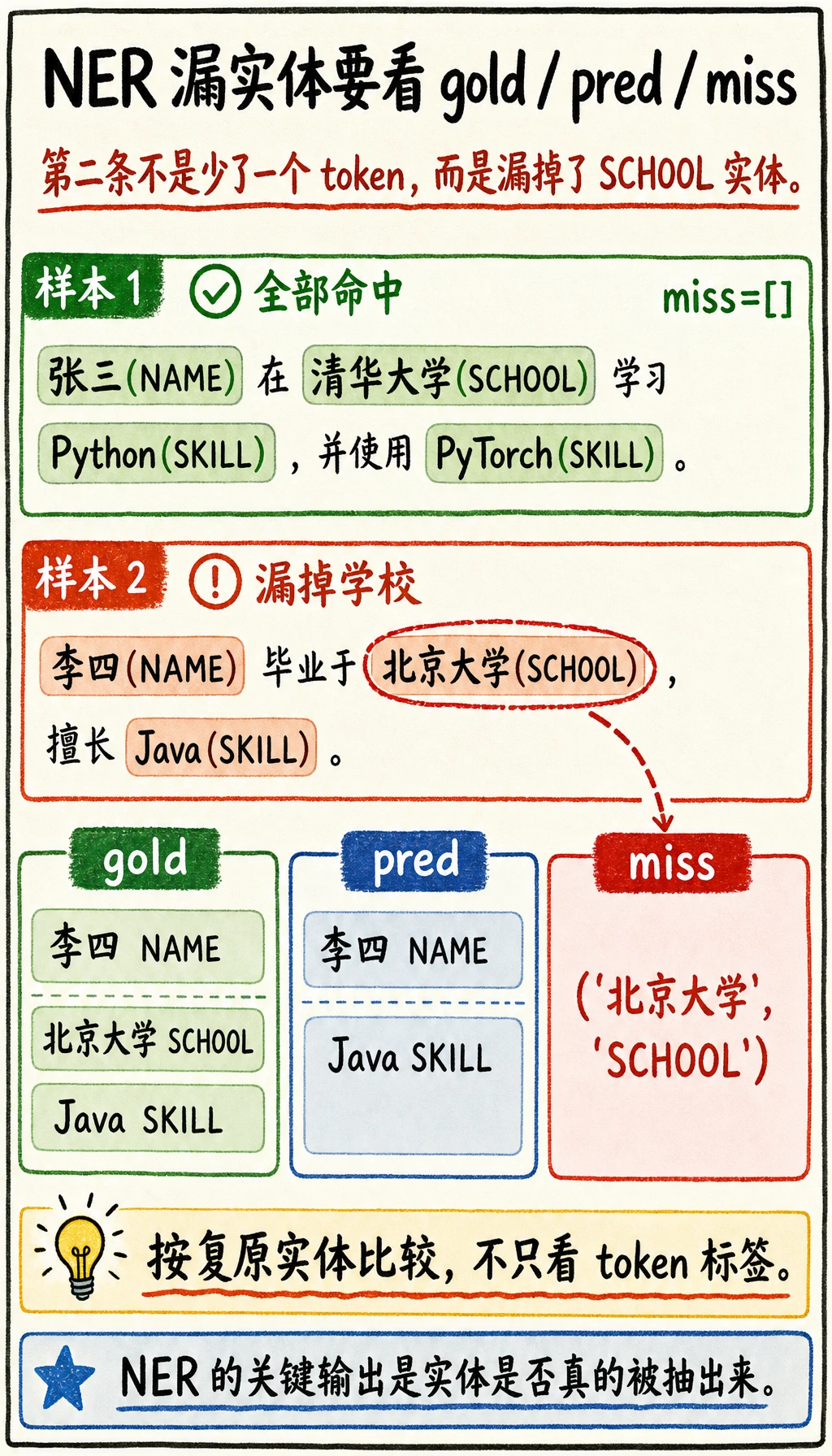
第二条样本漏掉了学校实体。这正说明 NER 项目不能只看 token 标签,而要看最终恢复出来的实体。
这段代码为什么是“项目最小闭环”?
Section titled “这段代码为什么是“项目最小闭环”?”因为它已经包含了:
- 数据表示
- 预测结果
- 实体恢复
- 错误分析
这比只打印一串标签更接近真实项目形态。
为什么这里按实体比较,而不是只按 token 比较?
Section titled “为什么这里按实体比较,而不是只按 token 比较?”因为业务真正关心的通常是:
- 实体有没有抽出来
- 类型对不对
而不是某一个 token 单点是否打对。
再看一个最小“实体日志”示例
Section titled “再看一个最小“实体日志”示例”sample = { "tokens": ["李四", "来自", "北京大学", ",", "掌握", "Java"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "O", "O", "O", "B-SKILL"],}
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1) if prefix == "B": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token)
if current_tokens: entities.append(("".join(current_tokens), current_type))
return entities
gold_entities = decode_entities(sample["tokens"], sample["gold_tags"])pred_entities = decode_entities(sample["tokens"], sample["pred_tags"])
print( { "text": "".join(sample["tokens"]), "gold_entities": gold_entities, "pred_entities": pred_entities, })预期输出:
{'text': '李四来自北京大学,掌握Java', 'gold_entities': [('李四', 'NAME'), ('北京大学', 'SCHOOL'), ('Java', 'SKILL')], 'pred_entities': [('李四', 'NAME'), ('Java', 'SKILL')]}这个日志特别适合初学者,因为它会把一个抽象的标签任务,变成更像真实项目的输出:
- 原文本是什么
- 正确实体有哪些
- 系统到底漏了什么
三、NER 项目最该先看什么指标?
Section titled “三、NER 项目最该先看什么指标?”实体级 Precision / Recall / F1
Section titled “实体级 Precision / Recall / F1”这是最常见也最有意义的一组指标。
为什么 token accuracy 不够?
Section titled “为什么 token accuracy 不够?”因为序列里往往很多都是:
O
只看 token accuracy 很容易显得“很高”, 但真正的实体抽取效果可能并不好。
一个极简实体召回例子
Section titled “一个极简实体召回例子”samples = [ { "tokens": ["张三", "毕业于", "清华大学", ",", "熟悉", "Python", "和", "PyTorch"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], }, { "tokens": ["李四", "来自", "北京大学", ",", "掌握", "Java"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "O", "O", "O", "B-SKILL"], },]
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1) if prefix == "B": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token)
if current_tokens: entities.append(("".join(current_tokens), current_type))
return entities
def entity_recall(gold_entities, pred_entities): if not gold_entities: return 1.0 hit = sum(entity in pred_entities for entity in gold_entities) return hit / len(gold_entities)
for sample in samples: gold_entities = decode_entities(sample["tokens"], sample["gold_tags"]) pred_entities = decode_entities(sample["tokens"], sample["pred_tags"]) print(entity_recall(gold_entities, pred_entities))预期输出:
1.00.6666666666666666第一条样本实体全中;第二条样本只抽出了 3 个实体中的 2 个,所以实体级 recall 会下降,即使很多 O 位置仍然是对的。
第一次做 NER 项目时,最稳的默认顺序
Section titled “第一次做 NER 项目时,最稳的默认顺序”更稳的顺序通常是:
- 先把实体类型收窄
- 先把标签标准写清楚
- 先做实体恢复和实体级评估
- 再去换更强模型
这样会比一开始就急着上 BERT 更容易把项目做稳。
四、NER 项目最常见的失败点
Section titled “四、NER 项目最常见的失败点”例如学校名只抽了一半。
例如把技能识别成学校。
例如样本 2 里把 北京大学 漏掉了。
为什么这很适合做错误分析?
Section titled “为什么这很适合做错误分析?”因为 NER 的错误通常很具体, 非常适合逐条看、逐类修。
一个新人很值得先用的错误分桶方式
Section titled “一个新人很值得先用的错误分桶方式”第一次做错例分析时,最值得先分的通常就是:
- 边界错
- 类型错
- 漏实体
这三类已经足够帮助你判断:
- 是数据标注问题
- 是模型表示问题
- 还是后处理规则不够
五、真实项目下一步该怎么走?
Section titled “五、真实项目下一步该怎么走?”尤其是:
- 长实体
- 稀有实体
- 容易混淆类型
从规则 / 经典模型升级到更强模型
Section titled “从规则 / 经典模型升级到更强模型”例如:
- BiLSTM + CRF
- BERT token classification
加入后处理规则
Section titled “加入后处理规则”很多业务项目里, 合理的后处理规则能明显提升实体质量。
如果把它做成项目,最值得展示什么
Section titled “如果把它做成项目,最值得展示什么”最值得展示的通常不是:
- 一串标签预测结果
而是:
- 原始文本
- gold 实体
- 预测实体
- 漏抽和错抽案例
- 你下一步准备优先修哪类错误
这样别人会更容易感觉到:
- 你做的是信息抽取项目
- 不只是训练了一个序列标注模型
六、最常见误区
Section titled “六、最常见误区”误区一:只看 token 级指标
Section titled “误区一:只看 token 级指标”NER 更该看实体级效果。
误区二:一开始就想覆盖所有实体类型
Section titled “误区二:一开始就想覆盖所有实体类型”更稳的做法通常是:
- 先选 2~4 类核心实体做透
误区三:标签体系一开始不定清楚
Section titled “误区三:标签体系一开始不定清楚”标签边界不清,数据和评估都会一起发散。
学完这一页,至少保留这张证据卡:
- 模式
- 实体类型、BIO 标签,或序列标注规则
- 预测
- 词级标签和提取的片段
- 指标
- 实体精确率/召回率/F1 和边界情况
- 失败检查
- 跨度边界、嵌套实体、未知词或标注不一致
- 期望产出
- 金标与预测 span 对照表,至少包含一个漏判
这节最重要的是建立一个实战习惯:
做 NER 项目时,先把实体类型、标签体系、实体恢复和实体级错误分析做扎实,再去追求更复杂模型。
这样你留下的会是一个真正可解释、可改进的信息抽取项目,而不是只会跑训练脚本的半成品。
- 给示例再加一个
ORG或TITLE实体类型,扩展样本。 - 想一想:为什么 NER 项目更适合看实体级指标,而不是 token accuracy?
- 如果系统经常把长学校名只抽一半,你会优先改数据、改模型,还是加后处理?为什么?
- 你会如何把这个简历抽取项目进一步扩成作品集展示?
项目交付参考与讲解
- 增加
ORG或TITLE时,先定义边界规则:组织名、职位名和周围修饰词到底算不算实体。 - NER 更适合用实体级指标,因为用户拿到的是抽出的实体,不是孤立 token 标签。
- 长学校名只抽出一半时,先检查标注一致性,再补样本或后处理;只有目标清楚后才考虑换模型。
- 作品集展示应包含标签 schema、样例、实体级指标、错误分桶、修复方案和小型前后对比日志。