7.6.6 数据标注与数据飞轮
- 理解标注不只是“打标签”,而是在定义任务边界
- 知道如何设计标签体系、标注规范和质检流程
- 学会用一致性指标和难例筛选来检查数据质量
- 理解数据飞轮是如何把线上失败样本转成下一轮训练资产
一、为什么说“数据标注”本质上是在定义任务?
Section titled “一、为什么说“数据标注”本质上是在定义任务?”标签不是文员工作,而是产品决策
Section titled “标签不是文员工作,而是产品决策”假设你的任务是“客服回复质量分类”。
如果你只给标注员一个标签名:
- 好回复
- 坏回复
那每个人心里的标准都不同:
- 有人看礼貌
- 有人看是否解决问题
- 有人看是否符合政策
最后模型学到的就会是一锅混合标准。
所以标签真正应该回答的是:
- 什么算对
- 什么算错
- 边界情况怎么判
类比:模型不是在学标签名,而是在学你背后的规则
Section titled “类比:模型不是在学标签名,而是在学你背后的规则”你可以把每一条标注数据想成:
- 一个经过人类裁决的案例
模型看到的不是“safe/unsafe”这几个字, 而是你通过大量案例暗中表达的判断标准。
因此如果规则本身模糊, 模型不可能学得清楚。
为什么很多微调项目会卡在这里?
Section titled “为什么很多微调项目会卡在这里?”因为团队常常会高估“标签名”的清晰度,低估“标注规范”的重要性。
真正能稳定提升数据质量的,往往不是标注平台,而是:
- 标签定义
- 正反例
- 边界例
- 复核机制
二、先把标签体系设计清楚
Section titled “二、先把标签体系设计清楚”标签尽量和业务动作对应
Section titled “标签尽量和业务动作对应”一个好标签体系,最好能自然映射到后续动作。
例如在客服审核任务里, 比起只分:
- 好
- 坏
更实用的标签可能是:
correct_and_politecorrect_but_too_briefpolicy_violationhallucinated_promise
因为这样的标签更利于后续:
- 错误分析
- 数据补充
- 定向微调
边界样本一定要单独写规则
Section titled “边界样本一定要单独写规则”新人最容易忽略的是:
- 明显正例
- 明显负例
通常不难标。
真正难的是:
- 部分正确
- 语气礼貌但事实错
- 拒答方向对,但措辞生硬
这些边界例如果不写清楚, 一致性一定会掉。
什么时候该做分类标签,什么时候该做偏好对比?
Section titled “什么时候该做分类标签,什么时候该做偏好对比?”如果你的任务重点是:
- 明确类别
- 明确是否违规
分类标签通常更自然。
如果你的任务重点是:
- 两个回答谁更好
- 风格谁更符合预期
偏好对比往往更稳定。
也就是说:
- 分类更适合“绝对标准”
- 偏好更适合“相对优劣”
三、先跑一个真正有用的数据质检脚本
Section titled “三、先跑一个真正有用的数据质检脚本”下面这段代码会做三件现实中非常常用的事:
- 计算两个标注员的一致率
- 计算 Cohen’s kappa
- 找出需要进入下一轮复核或补标的样本
from collections import Counter
records = [ { "id": 1, "text": "可以先去重置密码,再尝试重新登录。", "label_a": "good", "label_b": "good", "model_confidence": 0.93, }, { "id": 2, "text": "你自己去查吧。", "label_a": "bad", "label_b": "bad", "model_confidence": 0.91, }, { "id": 3, "text": "已经发货也一定可以秒退。", "label_a": "bad", "label_b": "good", "model_confidence": 0.52, }, { "id": 4, "text": "订单完成后可在发票中心申请开票。", "label_a": "good", "label_b": "good", "model_confidence": 0.51, }, { "id": 5, "text": "我不确定是否支持改地址,建议联系人工客服确认。", "label_a": "good", "label_b": "bad", "model_confidence": 0.47, },]
def agreement_rate(labels_a, labels_b): matches = sum(a == b for a, b in zip(labels_a, labels_b)) return matches / len(labels_a)
def cohens_kappa(labels_a, labels_b): n = len(labels_a) observed = agreement_rate(labels_a, labels_b)
counter_a = Counter(labels_a) counter_b = Counter(labels_b) all_labels = sorted(set(labels_a) | set(labels_b)) expected = sum( (counter_a[label] / n) * (counter_b[label] / n) for label in all_labels )
if expected == 1: return 1.0 return (observed - expected) / (1 - expected)
labels_a = [row["label_a"] for row in records]labels_b = [row["label_b"] for row in records]
print("agreement =", round(agreement_rate(labels_a, labels_b), 3))print("kappa =", round(cohens_kappa(labels_a, labels_b), 3))
needs_review = [ row for row in records if row["label_a"] != row["label_b"] or row["model_confidence"] < 0.6]
needs_review = sorted(needs_review, key=lambda row: row["model_confidence"])print("\nreview queue:")for row in needs_review: print( f"id={row['id']} confidence={row['model_confidence']:.2f} " f"labels=({row['label_a']}, {row['label_b']}) text={row['text']}" )预期输出:
agreement = 0.6kappa = 0.167
review queue:id=5 confidence=0.47 labels=(good, bad) text=我不确定是否支持改地址,建议联系人工客服确认。id=4 confidence=0.51 labels=(good, good) text=订单完成后可在发票中心申请开票。id=3 confidence=0.52 labels=(bad, good) text=已经发货也一定可以秒退。为什么这段代码不是“废示例”?
Section titled “为什么这段代码不是“废示例”?”因为它对应的是数据团队每天都会做的三件事:
- 看标注员是否一致
- 看模型在哪些样本上最不确定
- 把争议样本拉出来重点复核
如果你只盯“总样本量”,却不看这些信息, 数据质量会很容易停留在表面。
为什么 agreement 还不够?
Section titled “为什么 agreement 还不够?”因为有时类别非常不平衡。
例如 90% 样本都属于 good,
那两个标注员即便都很偷懒,也能得到看起来很高的一致率。
这就是为什么很多团队还会看:
- Cohen’s kappa
它会尝试扣除“碰巧一致”的成分。
为什么低置信度样本要进复核队列?
Section titled “为什么低置信度样本要进复核队列?”因为这类样本往往意味着:
- 模型拿不准
- 规则边界模糊
- 或者样本本身比较脏
它们正是下一轮数据增益最大的地方。
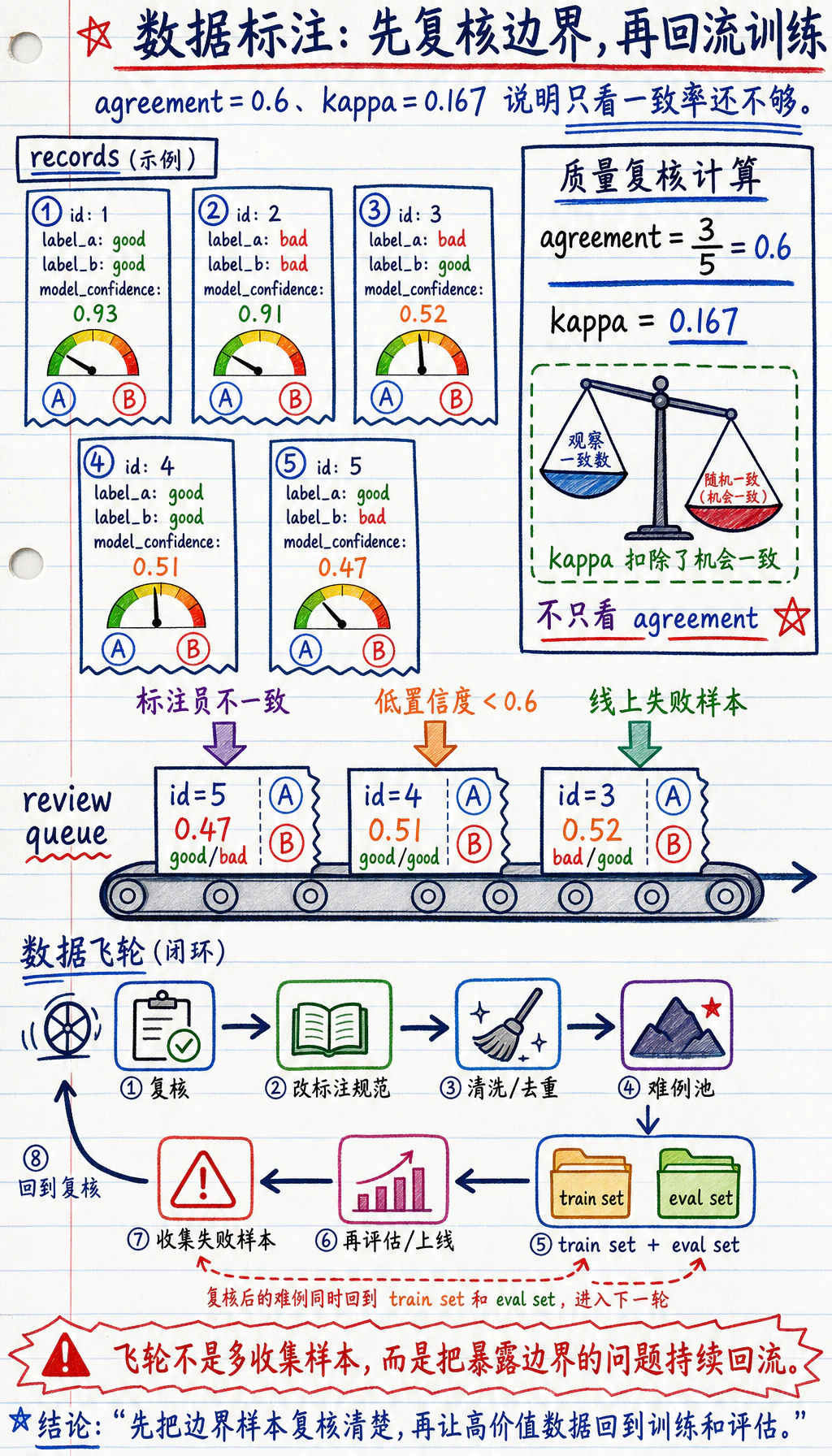
四、什么叫“数据飞轮”?
Section titled “四、什么叫“数据飞轮”?”最小闭环长什么样?
Section titled “最小闭环长什么样?”一个典型的数据飞轮通常是:
- 模型上线
- 收集失败样本
- 清洗和去重
- 复标或补标
- 加入下一轮训练集
- 再评估、再上线
飞轮的重点不是“循环”这两个字, 而是每一轮回来的数据都更贴近真实问题。
为什么线上失败样本特别值钱?
Section titled “为什么线上失败样本特别值钱?”因为它们往往具备两个特点:
- 来自真实用户
- 正好打中当前系统最薄弱的地方
和人工凭空编一批样本相比, 这种数据更有针对性。
飞轮最怕什么?
Section titled “飞轮最怕什么?”最怕三件事:
- 失败样本收不上来
- 收上来后没人分类归因
- 归因后没有进入下一轮训练或评估
如果只收集、不回流, 那就不叫飞轮,只是积压。
五、怎样把飞轮做得更稳?
Section titled “五、怎样把飞轮做得更稳?”先做失败类型分桶
Section titled “先做失败类型分桶”把线上问题分成几类,常常比单纯堆样本更有效。
例如:
- 格式错误
- 幻觉
- 政策违规
- 过度拒答
- 漏关键字段
这样下一轮你就知道该补哪一类数据。
再做去重和代表性采样
Section titled “再做去重和代表性采样”真实线上数据很容易重复。 如果用户大量重复问同一类问题,你不应该机械地把所有样本都塞回训练集。
更好的做法通常是:
- 去掉近重复
- 保留代表性样本
- 给稀有但高风险问题更高优先级
别忘了版本管理
Section titled “别忘了版本管理”每一轮数据最好都记清楚:
- 从哪里来
- 为什么加入
- 属于哪一类错误
- 是否已经人工复核
否则到后面你会很难回答:
这次提升到底是因为方法变了,还是因为数据变了?
六、标注规范到底该写到什么程度?
Section titled “六、标注规范到底该写到什么程度?”至少要有正例、反例和边界例
Section titled “至少要有正例、反例和边界例”一个好规范通常至少包含:
- 标签定义
- 适用条件
- 明确正例
- 明确反例
- 易混边界例
最好能回答“为什么”
Section titled “最好能回答“为什么””如果规范只写:
- 遇到这种情况打
bad
但没写为什么, 标注员在遇到相似但不完全相同的情况时就会摇摆。
规范本身也要迭代
Section titled “规范本身也要迭代”随着项目推进,你会不断发现:
- 旧规则覆盖不到的新场景
- 原标签过粗
- 两个标签容易混淆
这时要更新的,不只是数据, 还有规范本身。
七、这些误区特别容易踩
Section titled “七、这些误区特别容易踩”误区一:先大量标,再说规则
Section titled “误区一:先大量标,再说规则”规则没定清楚就大规模开标, 通常会导致返工量极大。
误区二:只盯一致率,不看争议原因
Section titled “误区二:只盯一致率,不看争议原因”一致率低只是表象。 更重要的是知道:
- 是规范不清
- 还是样本太脏
- 或者标签体系本身就不合理
误区三:把飞轮理解成“不断加更多数据”
Section titled “误区三:把飞轮理解成“不断加更多数据””飞轮不是纯堆量, 而是不断把最有价值的失败样本转成高质量训练资产。
学完这一页,至少保留这张证据卡:
- 标签规则
- 任务定义和允许的输出
- 质量检查
- 重复、冲突、空白,或模糊标签的数量
- 指导原则
- 能消除歧义的一条规则
- 飞轮
- 模型失败 → 标签修正 → 重新训练/评估
- 风险
- 糟糕的标签会更高效地教会模型坏行为
这一节最重要的结论是:
数据标注不是微调前的一道杂务,而是任务定义、质量控制和持续迭代能力的核心。
真正有生命力的数据体系,通常同时具备三件事:
- 规则清楚
- 质检到位
- 失败样本能稳定回流
当这三件事都成立时, 你的模型质量才会出现持续、可解释的提升。
- 为一个你熟悉的任务设计 3 到 5 个标签,并写出每个标签的正例和反例。
- 参考本节代码,自己手动构造一批双人标注数据,算一下一致率和 kappa。
- 想一想:你的项目里哪些线上失败样本最值得优先回流到训练集?
- 如果两个标注员总在同一类样本上争议,你会先改规范、改标签体系,还是直接投票裁决?为什么?
项目交付参考与讲解
- 好标签应彼此可区分、能指导动作,并用边界案例说明。正例和反例要让判断规则可见,而不只是重复标签名。
- 一致率显示原始一致程度,kappa 会扣除随机一致的影响。如果一致性低,常见原因是说明不清、标签重叠或样本本身模糊。
- 优先回流高频失败、高风险失败,以及代表稳定模式的失败样本。偶发的小错误通常不如反复影响真实用户的失败模式有价值。
- 应先检查规范或标签体系是否含糊。投票可以解决单个样本,但持续争议说明任务定义本身需要修复。