9.2.4 ReAct 框架
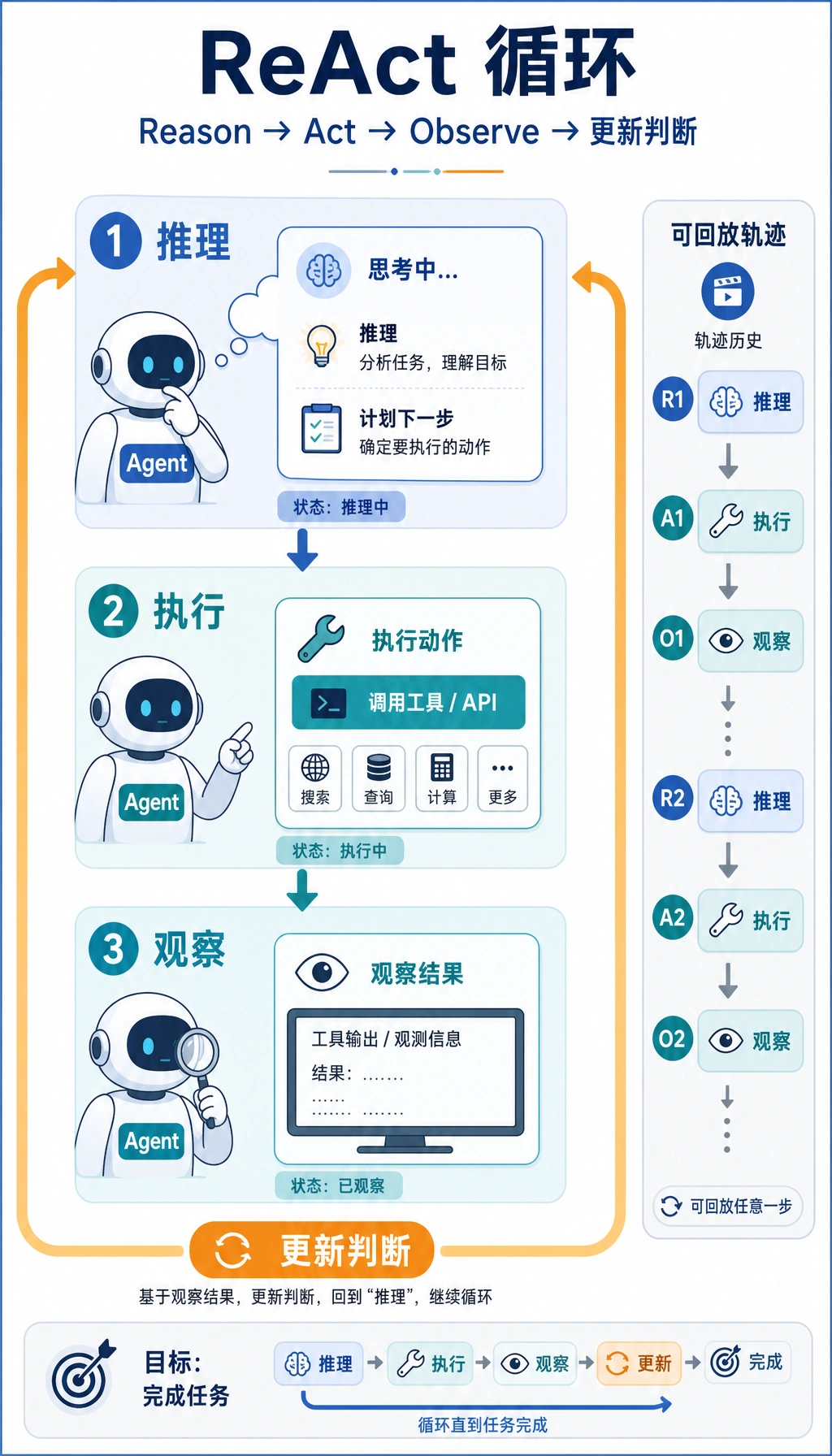
- 理解 ReAct 的核心循环:
Thought -> Action -> Observation - 理解它和纯 CoT 的差别
- 通过可运行示例看懂一个最小 ReAct agent loop
- 理解 ReAct 最适合什么问题,什么情况下会变得笨重
为什么只靠“想”还不够?
Section titled “为什么只靠“想”还不够?”因为很多答案不在模型脑子里
Section titled “因为很多答案不在模型脑子里”例如:
- 今天北京天气怎么样?
- 某个订单现在是什么状态?
- 这两个数精确相加是多少?
这些问题都依赖:
- 实时外部信息
- 精确工具能力
如果模型只靠自己“猜”, 就会出现:
- 幻觉
- 过度自信
- 算错
ReAct 的本质:边想边拿新信息
Section titled “ReAct 的本质:边想边拿新信息”它的典型循环是:
Thought我现在缺什么信息?Action我该调用哪个工具?Observation工具返回了什么?- 再进入下一轮思考
这让 Agent 不再只是“脑补答案”, 而是可以逐步靠近真实环境。
一个类比:像做调查,而不是闭门写作
Section titled “一个类比:像做调查,而不是闭门写作”纯 CoT 更像在草稿纸上推题。 ReAct 更像做调查:
- 先想应该去查什么
- 去拿证据
- 再根据证据继续判断
ReAct 和 CoT 的根本差别
Section titled “ReAct 和 CoT 的根本差别”CoT 偏“内部推导”
Section titled “CoT 偏“内部推导””核心问题是:
- 如何拆步骤
- 如何保持中间状态
ReAct 偏“推导 + 外部交互”
Section titled “ReAct 偏“推导 + 外部交互””它额外多了一层:
- 什么时候该向外部要信息
所以 ReAct 更像:
- CoT + 工具循环
为什么这对 Agent 特别关键?
Section titled “为什么这对 Agent 特别关键?”因为 Agent 不只是做静态问答。 它经常要:
- 查知识库
- 调数据库
- 算数
- 执行命令
这些都要求它在思考过程中不断接入外部世界。
先跑一个真正的 ReAct 最小闭环
Section titled “先跑一个真正的 ReAct 最小闭环”下面这个例子会模拟一个小型电商助手。 用户问:
- 退款规则是什么?
- 订单金额
299 + 15最终会退多少?
Agent 需要:
- 先查退款政策
- 再调用计算器
- 最后整合出答案
import astimport operator
OPS = { ast.Add: operator.add, ast.Sub: operator.sub, ast.Mult: operator.mul, ast.Div: operator.truediv,}
def safe_calculate(expression): def visit(node): if isinstance(node, ast.Expression): return visit(node.body) if isinstance(node, ast.Constant) and isinstance(node.value, (int, float)): return node.value if isinstance(node, ast.BinOp) and type(node.op) in OPS: return OPS[type(node.op)](visit(node.left), visit(node.right)) if isinstance(node, ast.UnaryOp) and isinstance(node.op, ast.USub): return -visit(node.operand) raise ValueError("unsupported_expression")
return visit(ast.parse(expression, mode="eval"))
def search_policy(topic): policies = { "refund": "未发货订单可直接申请退款,款项原路返回,通常 3 到 7 个工作日到账。", } return policies.get(topic, "未找到相关政策。")
def calculator(expression): return str(safe_calculate(expression))
def policy(state): trace = state["trace"] question = state["question"]
if not any(item["action"] == "search_policy" for item in trace): return { "thought": "我需要先确认退款政策,再回答规则部分。", "action": "search_policy", "args": {"topic": "refund"}, }
if not any(item["action"] == "calculator" for item in trace): return { "thought": "我已经知道政策了,接下来计算退款金额 299 + 15。", "action": "calculator", "args": {"expression": "299 + 15"}, }
policy_text = next(item["observation"] for item in trace if item["action"] == "search_policy") amount = next(item["observation"] for item in trace if item["action"] == "calculator")
return { "thought": "信息已经足够,可以给出最终回答。", "action": None, "answer": f"{policy_text} 本单预计退款金额为 {amount} 元。", }
TOOLS = { "search_policy": search_policy, "calculator": calculator,}
def run_react(question, max_steps=5): state = {"question": question, "trace": []}
for _ in range(max_steps): decision = policy(state)
if decision["action"] is None: return state["trace"], decision["answer"]
tool_name = decision["action"] observation = TOOLS[tool_name](**decision["args"])
state["trace"].append( { "thought": decision["thought"], "action": tool_name, "args": decision["args"], "observation": observation, } )
return state["trace"], "达到最大步数,未能完成任务。"
trace, answer = run_react("退款规则是什么?订单金额 299 + 15 最终会退多少?")
print("trace:")for item in trace: print(item)print("\nfinal answer:")print(answer)预期输出:
trace:{'thought': '我需要先确认退款政策,再回答规则部分。', 'action': 'search_policy', 'args': {'topic': 'refund'}, 'observation': '未发货订单可直接申请退款,款项原路返回,通常 3 到 7 个工作日到账。'}{'thought': '我已经知道政策了,接下来计算退款金额 299 + 15。', 'action': 'calculator', 'args': {'expression': '299 + 15'}, 'observation': '314'}
final answer:未发货订单可直接申请退款,款项原路返回,通常 3 到 7 个工作日到账。 本单预计退款金额为 314 元。
这段代码最应该怎么读?
Section titled “这段代码最应该怎么读?”建议按这个顺序:
- 先看
policy理解 agent 每轮如何决定“下一步” - 再看
TOOLS理解外部能力从哪来 - 最后看
run_react理解完整循环如何把 trace 逐步积累起来
trace 为什么这么重要?
Section titled “trace 为什么这么重要?”因为 ReAct 不是一次出答案, 而是逐步推进。
有了 trace,你才能知道:
- 想了什么
- 调了什么
- 看到了什么
- 为什么最后会给出这个答案
这对调试非常关键。
为什么 ReAct 往往比“直接一次调用工具”更强?
Section titled “为什么 ReAct 往往比“直接一次调用工具”更强?”因为真实问题经常不是一步完成。 工具调用顺序可能依赖前一步结果。
例如这里:
- 要先确认政策
- 再算金额
- 再组织回答
这就是 ReAct 最擅长的结构。
ReAct 什么时候最好用?
Section titled “ReAct 什么时候最好用?”任务需要多轮观察
Section titled “任务需要多轮观察”例如:
- 先搜再算
- 先查再比
- 先看状态再决定下一步
工具调用顺序不是固定死的
Section titled “工具调用顺序不是固定死的”如果每个任务都严格是:
- 查 A
- 查 B
- 输出
那普通 workflow 也许就够了。
ReAct 更适合:
- 当前一步结果会影响下一步选择
你需要过程可追踪
Section titled “你需要过程可追踪”因为 ReAct 天然有:
- thought
- action
- observation
这让它很适合做:
- 调试
- 回放
- 错误分析
ReAct 最常见的问题是什么?
Section titled “ReAct 最常见的问题是什么?”如果 agent 老是在:
- 想
- 调
- 再想
- 再调
就会出现:
- 慢
- 贵
- 容易跑偏
ReAct 不保证每轮都选对工具。 它可能会:
- 查错知识源
- 重复调用
- 调一个其实没必要的工具
Observation 整合失败
Section titled “Observation 整合失败”即使工具返回了对的信息, agent 也可能:
- 忽略关键字段
- 误读结果
- 最后整合错
这说明 ReAct 的难点不只是“有没有工具”, 还有“能不能读懂工具输出”。
工程上怎么让 ReAct 更稳?
Section titled “工程上怎么让 ReAct 更稳?”让动作 结构约束 足够清楚
Section titled “让动作 结构约束 足够清楚”工具描述越清楚, agent 越不容易乱调。
限制最大步数
Section titled “限制最大步数”避免无意义循环的一个最简单办法就是:
- 明确
max_steps
对 observation 做结构化
Section titled “对 observation 做结构化”如果工具返回的是乱糟糟的一大段自然语言, agent 更容易误读。
更稳的方式通常是:
- 返回结构化字段
例如:
{"refund_days": "3-7", "channel": "original_payment"}
误区一:ReAct 就是“会调用工具”
Section titled “误区一:ReAct 就是“会调用工具””不够准确。 ReAct 的关键是:
- 推理和行动交替推进
误区二:只要有 追踪,就一定可靠
Section titled “误区二:只要有 追踪,就一定可靠”trace 可追踪,但不自动保证正确。
误区三:所有 Agent 都应该用 ReAct
Section titled “误区三:所有 Agent 都应该用 ReAct”不一定。 如果流程高度固定, 显式工作流可能更简单、更稳。
什么时候不适合 ReAct?
Section titled “什么时候不适合 ReAct?”| 场景 | 更稳的替代方式 |
|---|---|
| 步骤固定、没有分支 | 普通 workflow 或函数链 |
| 高风险写操作 | 先审批,再执行,不让 Agent 自由探索 |
| 成本和延迟特别敏感 | 固定工具路线,减少多轮试探 |
| 工具输出很难可靠解释 | 先做结构化解析和规则校验 |
所以 ReAct 不是默认答案。它适合“下一步依赖观察”的任务;如果任务路径本来就清楚,显式流程通常更便宜、更容易测试。
学完这一页,至少保留这张证据卡:
- 任务目标
- Agent 想要解决什么
- 计划或轨迹
- 推理步骤、计划、ReAct 轨迹或执行图
- 观察
- 每次操作后发生了什么变化
- 失败检查
- 虚构步骤、过时观察、循环或未经验证的结论
- 评估动作
- 与期望结果对比并修正计划
这节最重要的不是把 ReAct 当成一个流行名词,
而是理解它为什么重要:
当任务需要边思考边向外部世界拿信息时,ReAct 能把“推理”和“行动”组织成一条逐步收集证据、逐步靠近答案的循环。
只要这层理解清楚了, 你后面再看更复杂的 Agent 轨迹、工具策略和多步执行框架,就会更顺。
- 给示例再加一个工具,例如
check_order_status,让 agent 多一步判断。 - 为什么说 ReAct 更适合“下一步动作依赖上一轮 observation”的任务?
- 如果工具输出很乱,ReAct 为什么更容易出错?
- 想一个更适合固定 工作流、而不太适合 ReAct 的任务。
参考实现与讲解
check_order_status应该增加一个新的 action 选择,并返回会影响下一步判断的 observation。- ReAct 适合每次 observation 都可能改变计划的任务,例如搜索结果、工具错误、缺失字段、权限结果或计算输出都会影响下一步。
- 工具输出混乱时,observation 很难被准确解释,下一步 action 就可能基于错误信号做出。
- 密码重置、发票创建、审批流这类步骤严格固定的任务,通常比开放式 ReAct 循环更适合 workflow。