7.4.5 租 GPU 训练手搓 GPT-2
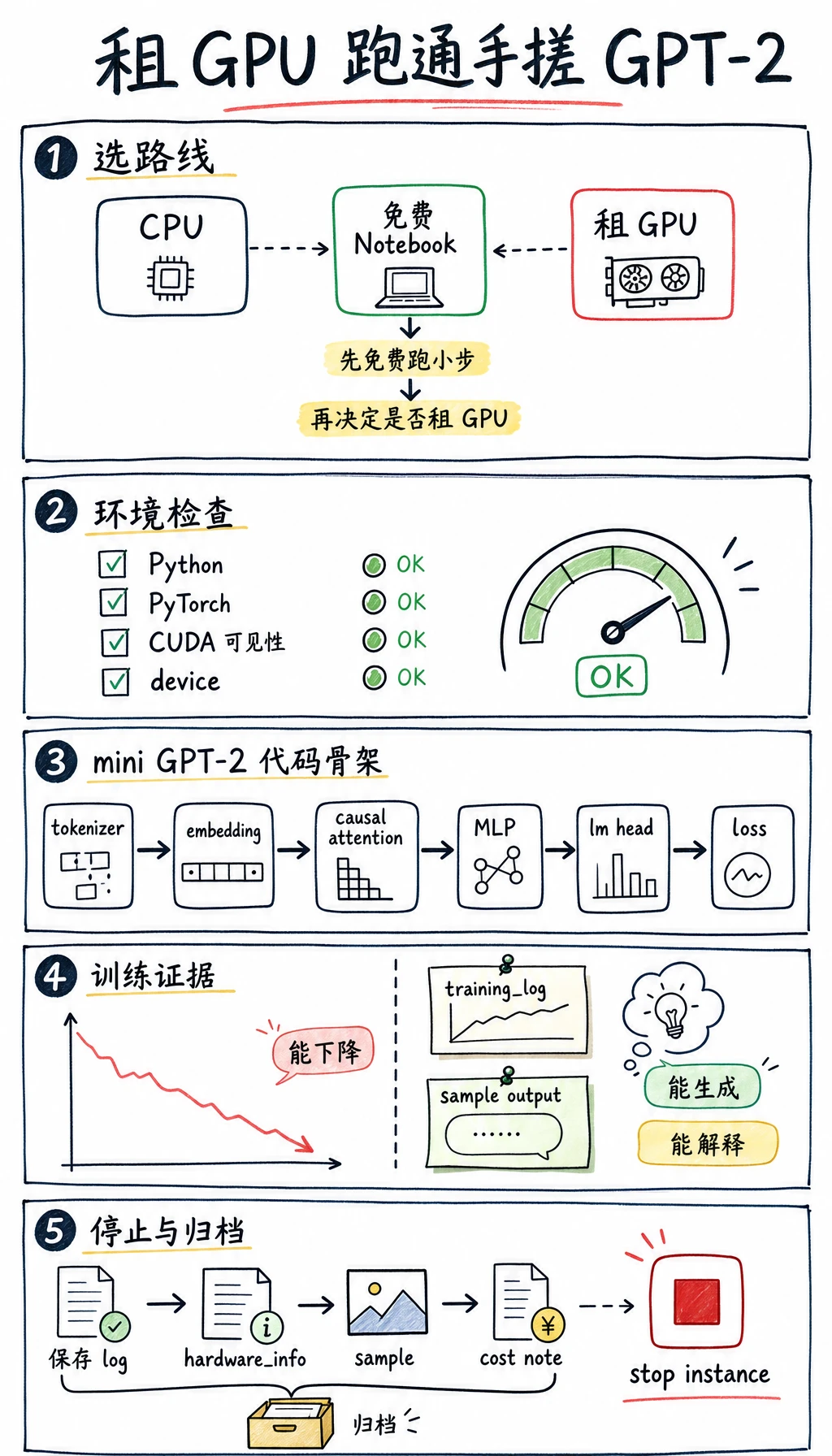
- 知道什么时候用免费 Notebook,什么时候租一张低价 GPU。
- 能创建 Python、PyTorch 和 CUDA 可用的训练环境。
- 能在 GPU 上运行一个单文件 mini GPT-2 训练脚本。
- 能逐段解释 embedding、causal self-attention、MLP、loss、checkpoint 和 generate。
- 能保存训练日志、硬件信息、checkpoint 路径、生成样例和关机证明,作为学习证据。
一、先选 GPU 方案
Section titled “一、先选 GPU 方案”不要一开始就追求大卡。课程实验要优先保证每个人能跑通。
| 方案 | 适合谁 | 推荐用法 | 注意点 |
|---|---|---|---|
| Kaggle Notebook | 免费优先、公开课程 | 打开 GPU,运行 mini GPT-2 | 配额会变化,不保证随时有卡 |
| Colab 免费版 | 快速试跑 | 验证代码和日志 | GPU 型号和时长不稳定 |
| Lightning AI 免费层 | 想要更像云开发环境 | 保存项目、反复实验 | 免费额度用完要等待或付费 |
| AutoDL / RunPod | 想稳定跑 1-3 小时 | 租 RTX 4090、L4、A10 或 A5000 | 记得关机和删除实例 |
| A100 / H100 | 研究完整预训练成本 | 只做演示或高阶挑战 | 不适合作为必修租赁要求 |
本节推荐配置
Section titled “本节推荐配置”| 实验目标 | 最低配置 | 更舒服的配置 |
|---|---|---|
| 冒烟测试脚本 | CPU 或免费 Notebook | 任意能 import PyTorch 的机器 |
| 通过本节 | 任意可见 CUDA GPU,例如 T4 | T4、L4、A10、4090、A5000 |
| loss 明显下降 | 免费 T4 跑 300-800 步 | 4090、A5000 跑 1000-3000 步 |
| 体验更大模型 | 16GB 显存 | 24GB 显存 |
这节默认参数很小,即使用 CPU 也能进入训练循环,但 CPU 完成只算预检。正式通过本节,至少要有一份出现 device: cuda 的训练日志。这个要求不是为了追求大模型,而是为了练会真实训练流程:环境检查、显存纪律、日志、checkpoint、证据带回和停止计费。
二、租 GPU 前的检查清单
Section titled “二、租 GPU 前的检查清单”开始付费前,先确认四件事:
- 预算:这次实验最多花多少钱,例如 10-30 元。
- 机器:优先选 16GB 或 24GB 显存,不必选最贵卡。
- 镜像:选择 PyTorch 镜像,最好已经带 CUDA。
- 退出:知道在哪里关机、停止计费、删除实例。
常见选择:
免费路线:Kaggle / Colab -> 打开 GPU -> 上传或新建脚本 -> 运行国内低价路线:AutoDL -> 选 PyTorch 镜像 -> 开 Jupyter 或 SSH -> 运行国际低价路线:RunPod -> 选 PyTorch template -> 开 terminal -> 运行成本控制原则:先用 CPU 或免费 Notebook 做短冒烟测试,再用 GPU 做正式训练。不要在 import、路径或 CUDA 镜像没配好时开始烧钱。
三、打开环境并检查 PyTorch
Section titled “三、打开环境并检查 PyTorch”在 Notebook 或远程终端里运行:
python -Vpython - <<'PY'import torchprint("torch:", torch.__version__)print("cuda available:", torch.cuda.is_available())print("device:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "cpu")PY预期输出类似:
torch: 2.x.xcuda available: Truedevice: Tesla T4如果显示 cuda available: False,不要急着训练。先检查 Notebook 是否打开 GPU,或者云机器是否选了 CUDA 版 PyTorch 镜像。
四、新建单文件脚本
Section titled “四、新建单文件脚本”新建 mini_gpt2_train.py,先完整复制下面代码。第一次学习时不要急着改参数,先保证它能运行。
import mathimport timefrom dataclasses import dataclass
import torchimport torch.nn as nnimport torch.nn.functional as F
text = """To build a language model, we ask it to predict the next token.The model reads previous tokens, mixes context with attention, and produces logits.Small experiments teach the same training loop as large models."""
chars = sorted(set(text))stoi = {ch: i for i, ch in enumerate(chars)}itos = {i: ch for ch, i in stoi.items()}data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long)
def decode(ids): return "".join(itos[int(i)] for i in ids)
def get_batch(batch_size, block_size, device): max_start = len(data) - block_size - 1 starts = torch.randint(0, max_start, (batch_size,)) x = torch.stack([data[i : i + block_size] for i in starts]).to(device) y = torch.stack([data[i + 1 : i + block_size + 1] for i in starts]).to(device) return x, y
@dataclassclass GPTConfig: vocab_size: int block_size: int = 64 n_layer: int = 2 n_head: int = 2 n_embd: int = 64 dropout: float = 0.1
class CausalSelfAttention(nn.Module): def __init__(self, config): super().__init__() assert config.n_embd % config.n_head == 0 self.n_head = config.n_head self.head_size = config.n_embd // config.n_head self.qkv = nn.Linear(config.n_embd, 3 * config.n_embd) self.proj = nn.Linear(config.n_embd, config.n_embd) self.dropout = nn.Dropout(config.dropout) mask = torch.tril(torch.ones(config.block_size, config.block_size)) self.register_buffer("mask", mask.view(1, 1, config.block_size, config.block_size))
def forward(self, x): B, T, C = x.shape q, k, v = self.qkv(x).split(C, dim=2) q = q.view(B, T, self.n_head, self.head_size).transpose(1, 2) k = k.view(B, T, self.n_head, self.head_size).transpose(1, 2) v = v.view(B, T, self.n_head, self.head_size).transpose(1, 2)
scores = q @ k.transpose(-2, -1) / math.sqrt(self.head_size) scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf")) weights = F.softmax(scores, dim=-1) weights = self.dropout(weights) out = weights @ v out = out.transpose(1, 2).contiguous().view(B, T, C) return self.proj(out)
class Block(nn.Module): def __init__(self, config): super().__init__() self.ln1 = nn.LayerNorm(config.n_embd) self.attn = CausalSelfAttention(config) self.ln2 = nn.LayerNorm(config.n_embd) self.mlp = nn.Sequential( nn.Linear(config.n_embd, 4 * config.n_embd), nn.GELU(), nn.Linear(4 * config.n_embd, config.n_embd), nn.Dropout(config.dropout), )
def forward(self, x): x = x + self.attn(self.ln1(x)) x = x + self.mlp(self.ln2(x)) return x
class MiniGPT(nn.Module): def __init__(self, config): super().__init__() self.config = config self.token_emb = nn.Embedding(config.vocab_size, config.n_embd) self.pos_emb = nn.Embedding(config.block_size, config.n_embd) self.blocks = nn.ModuleList([Block(config) for _ in range(config.n_layer)]) self.ln_f = nn.LayerNorm(config.n_embd) self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
def forward(self, idx, targets=None): B, T = idx.shape positions = torch.arange(T, device=idx.device) x = self.token_emb(idx) + self.pos_emb(positions) for block in self.blocks: x = block(x) x = self.ln_f(x) logits = self.lm_head(x)
loss = None if targets is not None: loss = F.cross_entropy(logits.view(B * T, -1), targets.view(B * T)) return logits, loss
@torch.no_grad() def generate(self, idx, max_new_tokens): for _ in range(max_new_tokens): idx_cond = idx[:, -self.config.block_size :] logits, _ = self(idx_cond) logits = logits[:, -1, :] probs = F.softmax(logits, dim=-1) next_id = torch.multinomial(probs, num_samples=1) idx = torch.cat([idx, next_id], dim=1) return idx
def main(): device = "cuda" if torch.cuda.is_available() else "cpu" torch.manual_seed(42)
config = GPTConfig(vocab_size=len(chars)) model = MiniGPT(config).to(device) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
steps = 500 if device == "cuda" else 120 batch_size = 64 if device == "cuda" else 16 print("device:", device) print("cuda_name:", torch.cuda.get_device_name(0) if device == "cuda" else "not available") print("parameters:", sum(p.numel() for p in model.parameters()))
start_time = time.time() for step in range(1, steps + 1): x, y = get_batch(batch_size, config.block_size, device) logits, loss = model(x, y) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step()
if step == 1 or step % 50 == 0: elapsed = time.time() - start_time print(f"step {step:04d} | loss {loss.item():.4f} | elapsed {elapsed:.1f}s")
checkpoint = { "model_state": model.state_dict(), "config": config.__dict__, "stoi": stoi, "itos": itos, } torch.save(checkpoint, "mini_gpt2_checkpoint.pt") print("checkpoint: mini_gpt2_checkpoint.pt")
prompt = torch.tensor([[stoi["T"]]], dtype=torch.long, device=device) generated = model.generate(prompt, max_new_tokens=180)[0].cpu() print("\n--- sample ---") print(decode(generated))
if __name__ == "__main__": main()运行:
python mini_gpt2_train.py | tee gpu_train_log.txt你应该看到类似:
device: cudacuda_name: Tesla T4parameters: about 100kstep 0001 | loss 3.5832 | elapsed 0.2sstep 0050 | loss 3.1120 | elapsed 1.6s...checkpoint: mini_gpt2_checkpoint.pt--- sample ---To build a language model...输出不需要像人类文章。只要 GPU 日志里 loss 往下降,checkpoint 已保存,并且能生成字符,就说明训练循环跑通了。
五、逐段讲解这份代码
Section titled “五、逐段讲解这份代码”1. 文本和 tokenizer
Section titled “1. 文本和 tokenizer”chars = sorted(set(text))stoi = {ch: i for i, ch in enumerate(chars)}itos = {i: ch for ch, i in stoi.items()}data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long)这里用字符级 tokenizer。真实 GPT-2 用 BPE token,但教学时先用字符能减少依赖,让你专注模型结构。
stoi是 string to index,把字符转成整数。itos是 index to string,把整数转回字符。data是整段训练文本的 token id 序列。
2. next-token batch
Section titled “2. next-token batch”x = data[i : i + block_size]y = data[i + 1 : i + block_size + 1]x 是输入,y 是答案。模型看到第 0 到第 T-1 个 token,要预测第 1 到第 T 个 token。
这就是 causal language modeling 的最小形状。
3. 配置对象
Section titled “3. 配置对象”class GPTConfig: vocab_size: int block_size: int = 64 n_layer: int = 2 n_head: int = 2 n_embd: int = 64这些参数决定模型大小:
block_size:一次最多看多少 token。n_layer:有几个 Transformer block。n_head:attention 分成几个头。n_embd:每个 token 的向量维度。
完整 GPT-2 只是这些数字更大,结构思想相同。
4. QKV 和多头 attention
Section titled “4. QKV 和多头 attention”q, k, v = self.qkv(x).split(C, dim=2)q = q.view(B, T, self.n_head, self.head_size).transpose(1, 2)x 的形状是 [B, T, C]:
B是 batch size。T是序列长度。C是 embedding 维度。
qkv 一次性生成 query、key、value,再把 C 拆成多个 head。拆完后形状变成 [B, head, T, head_size],每个头可以学习不同的上下文关系。
5. Causal mask
Section titled “5. Causal mask”mask = torch.tril(torch.ones(config.block_size, config.block_size))scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf"))torch.tril 生成下三角矩阵。它的意思是:当前位置只能看自己和之前的 token,不能偷看未来答案。
这就是 GPT 这类 decoder-only 模型能做 next-token prediction 的关键规则。
6. Transformer block
Section titled “6. Transformer block”x = x + self.attn(self.ln1(x))x = x + self.mlp(self.ln2(x))每个 block 做两件事:
- attention 混合上下文。
- MLP 对每个位置的表示做非线性变换。
外面的 x + 是残差连接,让信息和梯度更容易通过深层网络。
7. token embedding 和 position embedding
Section titled “7. token embedding 和 position embedding”x = self.token_emb(idx) + self.pos_emb(positions)token embedding 告诉模型“这个 token 是什么”。position embedding 告诉模型“这个 token 在第几个位置”。没有位置信息,模型很难区分 AI learns 和 learns AI。
8. logits 和 loss
Section titled “8. logits 和 loss”logits = self.lm_head(x)loss = F.cross_entropy(logits.view(B * T, -1), targets.view(B * T))logits 的形状是 [B, T, vocab_size]。每个位置都会预测下一个 token 的概率分布。
cross_entropy 会比较预测和真实答案。训练的目标就是让正确下一个 token 的概率越来越高。
9. 训练循环
Section titled “9. 训练循环”logits, loss = model(x, y)optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()这四行就是神经网络训练的核心循环:
- forward 算预测和 loss。
- 清空旧梯度。
- backward 计算新梯度。
- optimizer 更新参数。
10. checkpoint
Section titled “10. checkpoint”torch.save(checkpoint, "mini_gpt2_checkpoint.pt")真实训练要留下可恢复产物。这个小 checkpoint 不是产品级模型,但它证明你得到的是一份训练后的权重,而不只是终端输出。
11. generate
Section titled “11. generate”logits = logits[:, -1, :]probs = F.softmax(logits, dim=-1)next_id = torch.multinomial(probs, num_samples=1)生成时只看最后一个位置的预测分布,抽样得到下一个 token,再把它接回输入,循环生成。
这就是“一个 token 一个 token 往外吐”的机制。
六、GPU 训练 runbook
Section titled “六、GPU 训练 runbook”Kaggle 或 Colab
Section titled “Kaggle 或 Colab”- 新建 Notebook。
- 在设置里打开 GPU。
- 运行 PyTorch 检查代码,确认
cuda available: True。 - 新建一个 cell,写入
mini_gpt2_train.py。 - 运行
python mini_gpt2_train.py | tee gpu_train_log.txt。 - 下载或复制
gpu_train_log.txt和mini_gpt2_checkpoint.pt。 - 保存硬件信息、loss 行、checkpoint 行和 sample。
AutoDL 或 RunPod
Section titled “AutoDL 或 RunPod”- 选择 PyTorch 镜像。
- 选择 16GB 或 24GB 显存机器。
- 启动后打开 JupyterLab 或 SSH terminal。
- 运行 PyTorch 检查代码。
- 保存脚本并运行训练。
- 带回
gpu_train_log.txt和mini_gpt2_checkpoint.pt。 - 训练结束后立刻关机,确认停止计费。
CPU 冒烟测试不是最终通过
Section titled “CPU 冒烟测试不是最终通过”CPU 适合检查文件存在、import 正常、训练循环能开始。它不是本节最终通过标准。如果证据里只有 device: cpu,请标记为“冒烟测试完成,GPU 正式训练待完成”。
七、常见问题
Section titled “七、常见问题”| 现象 | 可能原因 | 处理 |
|---|---|---|
cuda available: False | 没开 GPU 或镜像不对 | 切换 Notebook 加速器,或重建 CUDA/PyTorch 镜像 |
CUDA out of memory | batch、block 或模型太大 | 先减 batch_size,再减 block_size 或 n_embd |
| loss 不下降 | 步数太少、学习率不合适、数据太短 | 先跑 500 步,再观察整体趋势 |
| 生成文本混乱 | 模型太小、数据太少 | 正常现象,本节目标是跑通机制 |
| 账单继续增加 | 实例没关 | 停止实例,并在平台控制台确认状态 |
八、可以怎样扩展
Section titled “八、可以怎样扩展”跑通后,每次只改一个变量:
| 改动 | 观察什么 |
|---|---|
n_layer 从 2 改 4 | 参数量和速度如何变化 |
n_embd 从 64 改 128 | loss 是否下降更快,显存是否增加 |
| 换一段中文语料 | 字符表大小、生成文本有什么变化 |
block_size 从 64 改 128 | 上下文更长是否更慢 |
| 训练步数从 500 改 2000 | sample 是否更像训练文本 |
不要同时改很多参数。否则你不知道是哪个变化带来了效果。
学完这一页,至少保留这张证据卡:
- 平台选择
- Kaggle/Colab/Lightning/AutoDL/RunPod 中选择了哪一个
- 硬件信息
- torch 版本、cuda 是否可用、GPU 型号
- 训练日志
- device cuda,以及 step、loss、elapsed 至少三行
- Checkpoint
- mini_gpt2_checkpoint.pt 已保存或带回
- 代码定位
- 能指出 embedding、attention、loss、checkpoint、generate 在脚本里的位置
- 成本记录
- 如果租 GPU,记录开机时长和花费,并确认已关机
能在 GPU 上完成一次 device: cuda 的 mini_gpt2_train.py 训练,保存 gpu_train_log.txt 和 mini_gpt2_checkpoint.pt,并用自己的话解释“输入 token 如何经过 embedding、attention、MLP、lm head、checkpoint,最后用 cross entropy 学会预测下一个 token”,就算通过。CPU 运行即使完成,也只算冒烟测试。
检查思路与讲解
- 不要求生成优美文本。mini GPT-2 的目标是把路径跑通,而不是得到可用聊天模型。
- 合格日志至少要包含
device: cuda、硬件信息、参数量、若干步 loss、checkpoint 路径和一段 sample。 - 如果使用租用 GPU,学习证据里必须写明实例已停止,避免无意识计费。
- CPU 能跑通仍然有价值,但不是本节最终通过。