7.6.4 其他 PEFT 方法【选修】
- 理解 Prompt Tuning、Prefix Tuning、Adapter、IA3 分别在改哪里
- 知道这些方法和 LoRA 的核心差异
- 跑通一个真正与 PEFT 主题相关的 Adapter 最小训练示例
- 建立多任务、低显存、快速切换场景下的选型直觉
一、为什么 LoRA 不是唯一答案?
Section titled “一、为什么 LoRA 不是唯一答案?”PEFT 真正想解决的不是“发明缩写”
Section titled “PEFT 真正想解决的不是“发明缩写””PEFT 的根问题很朴素:
冻结大模型主体,只训练很小一部分参数,还能不能把模型拉向新任务?
只要这个目标不变,“训练哪一小部分参数”就会自然衍生出很多变体。
所以这些方法之间最大的区别,不是名字,而是:
- 可训练参数放在哪里
- 它会影响模型的哪一段信息流
- 训练成本、推理成本、可复用性分别怎样
一个类比:给同一台电脑做轻量改造
Section titled “一个类比:给同一台电脑做轻量改造”你可以把基础模型想成一台已经装好的电脑:
- Prompt Tuning 像是给开机桌面多放几张“隐藏便签”
- Prefix Tuning 像是给每个软件启动前都预先塞一点上下文
- Adapter 像是在主板上插一个很小的扩展卡
- IA3 像是在几个关键旋钮上加可调节的增益控制
它们都不是重做整台电脑, 而是在不同位置加一层可调结构。
为什么现实项目里会需要这些分支?
Section titled “为什么现实项目里会需要这些分支?”因为工程上的约束并不完全一样:
- 有的团队最在意显存
- 有的团队最在意多任务热切换
- 有的团队最在意推理时不要额外拖慢
- 有的团队想让同一个底座挂很多领域适配器
同样是 PEFT,最优方法未必相同。
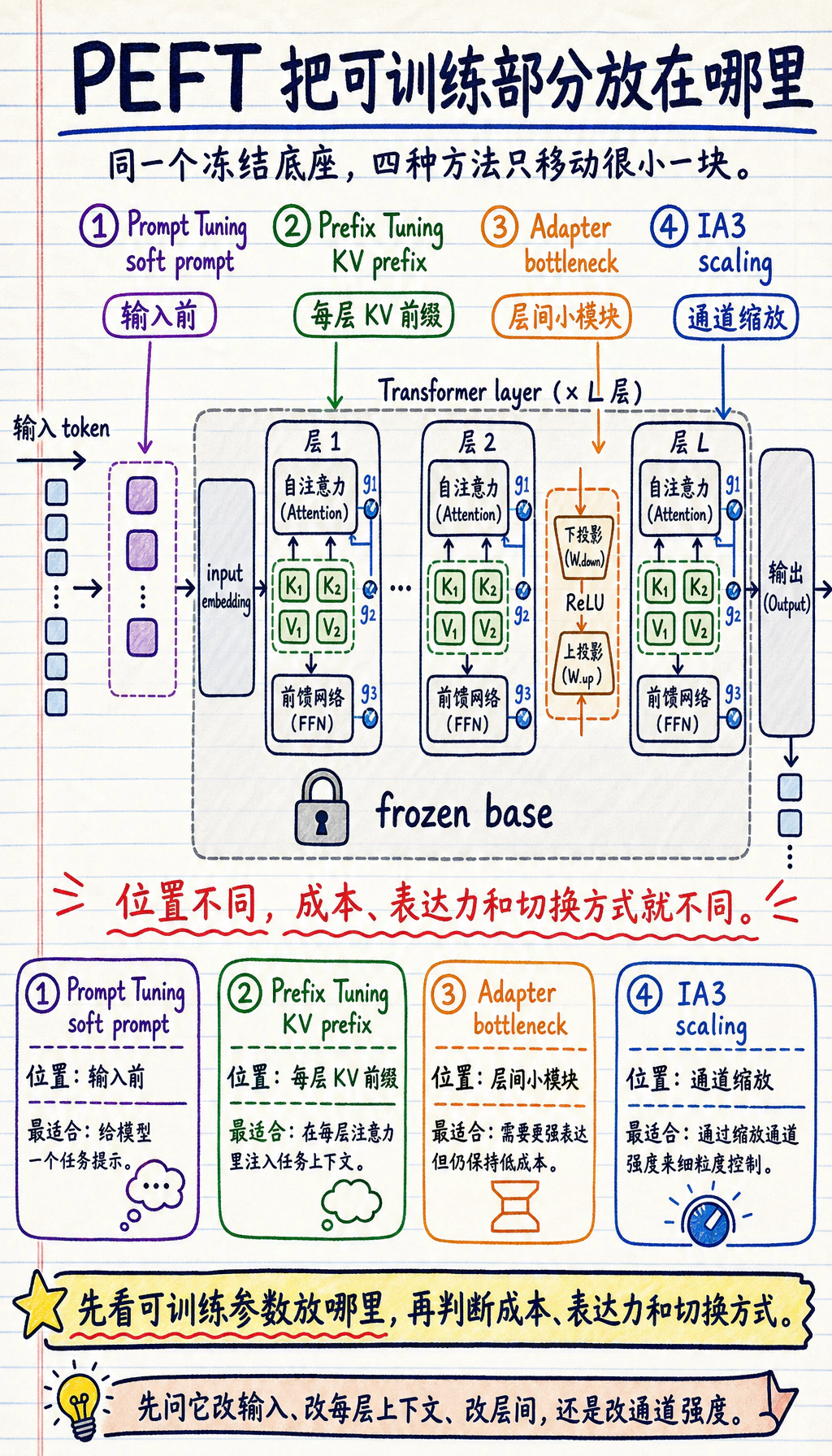
二、先把 PEFT 家族地图理清楚
Section titled “二、先把 PEFT 家族地图理清楚”提示词调优(Prompt Tuning):把可训练部分放在输入前面
Section titled “提示词调优(Prompt Tuning):把可训练部分放在输入前面”Prompt Tuning 的直觉是:
不改模型层内部结构,而是在输入 embedding 前面接上一小段可训练“软提示”。
这里的 prompt 不是你手写的自然语言,而是一组可训练向量。
它的优点是:
- 参数极少
- 实现概念清晰
- 适合任务数量很多、每个任务适配都要很轻的时候
它的局限是:
- 对复杂任务的改造力度有限
- 主要影响输入端,不像层内改造那样深入
前缀调优(Prefix Tuning):给每一层加“前缀上下文”
Section titled “前缀调优(Prefix Tuning):给每一层加“前缀上下文””Prefix Tuning 比 Prompt Tuning 更进一步。
它不是只在输入最前面加向量,而是:
给 Transformer 每一层的注意力模块额外准备一段可训练的 key/value 前缀。
你可以把它理解成:
- Prompt Tuning 更像只在开头塞一句“任务说明”
- Prefix Tuning 则像是每一层在做注意力时,都能看到一段额外的上下文提示
因此它通常比 Prompt Tuning 更有表达力。
Adapter:在层与层之间插小模块
Section titled “Adapter:在层与层之间插小模块”Adapter 的思路很适合新手理解,因为它最像“明确加了一个插件”。
常见结构是:
- 原始隐藏状态先经过一个降维层
- 中间做非线性变换
- 再升回原来的维度
- 通过残差连接加回主干
也就是:
主干冻结,旁边多插一个很小的可训练旁路。
它的工程优点很明显:
- 不用大改原模型主体
- 各个任务可以挂不同 adapter
- 多任务切换时只换小模块即可
IA3:不学大矩阵,而学“缩放系数”
Section titled “IA3:不学大矩阵,而学“缩放系数””IA3 的思路更节制:
不插小网络,也不学大增量,而是只学习少量的逐通道缩放向量。
例如在注意力输出或前馈层激活上做:
- 某些维度放大
- 某些维度压低
这意味着:
- 参数更少
- 训练更轻
- 但可表达能力也相对更克制
四种方法放在一起看
Section titled “四种方法放在一起看”| 方法 | 训练位置 | 主要取舍 |
|---|---|---|
| Prompt Tuning | 输入 embedding 前 | 参数极少,但改造力度有限 |
| Prefix Tuning | 每层注意力的 KV 前缀 | 比软提示表达力更强,但实现复杂 |
| Adapter | 层间小瓶颈模块 | 多任务切换方便,但推理多一小段计算 |
| IA3 | 激活缩放向量 | 很轻量,但对复杂行为变化表达较弱 |
PEFT 家族小词典
Section titled “PEFT 家族小词典”| 术语 | 新人友好的解释 |
|---|---|
| PEFT | Parameter-Efficient Fine-Tuning,参数高效微调,只训练一小部分参数来适配任务 |
| Soft prompt | 可训练向量,不是人能直接读懂的自然语言提示词 |
| KV prefix | 额外可训练的 key/value 向量,让注意力层可以参考 |
| Bottleneck | 先降维再升维的小模块,用来限制参数量 |
| Residual connection | 把小改动结果加回原隐藏状态,避免完全替换主干信息 |
| Activation scaling | 用可学习系数放大或压低某些隐藏维度 |
三、先跑一个真正和 PEFT 相关的 Adapter 示例
Section titled “三、先跑一个真正和 PEFT 相关的 Adapter 示例”下面这个例子会做一件非常具体的事:
- 构造一个很小的文本分类任务
- 冻结基础编码器
- 只训练 Adapter 和分类头
这样你能直接看到:
- 主模型没动
- 少量参数照样能把任务学起来
import torchimport torch.nn as nn
torch.manual_seed(42)
samples = [ ("refund my order", 0), ("need a refund", 0), ("cancel and refund", 0), ("login failed again", 1), ("cannot login account", 1), ("password login problem", 1),]label_names = ["refund", "login"]
vocab = {"<pad>": 0}for text, _ in samples: for token in text.split(): if token not in vocab: vocab[token] = len(vocab)
max_len = max(len(text.split()) for text, _ in samples)
def encode(text): ids = [vocab[token] for token in text.split()] ids += [0] * (max_len - len(ids)) return ids
x = torch.tensor([encode(text) for text, _ in samples], dtype=torch.long)y = torch.tensor([label for _, label in samples], dtype=torch.long)
class FrozenBaseEncoder(nn.Module): def __init__(self, vocab_size, hidden_dim=16): super().__init__() self.embedding = nn.Embedding(vocab_size, hidden_dim) self.proj = nn.Linear(hidden_dim, hidden_dim)
for param in self.parameters(): param.requires_grad = False
def forward(self, token_ids): emb = self.embedding(token_ids) mask = (token_ids != 0).unsqueeze(-1) pooled = (emb * mask).sum(dim=1) / mask.sum(dim=1).clamp(min=1) hidden = torch.tanh(self.proj(pooled)) return hidden
class AdapterClassifier(nn.Module): def __init__(self, vocab_size, hidden_dim=16, bottleneck_dim=4, num_labels=2): super().__init__() self.base = FrozenBaseEncoder(vocab_size, hidden_dim) self.adapter_down = nn.Linear(hidden_dim, bottleneck_dim) self.adapter_up = nn.Linear(bottleneck_dim, hidden_dim) self.classifier = nn.Linear(hidden_dim, num_labels)
def forward(self, token_ids): hidden = self.base(token_ids) adapted = hidden + self.adapter_up(torch.tanh(self.adapter_down(hidden))) logits = self.classifier(adapted) return logits
model = AdapterClassifier(vocab_size=len(vocab))optimizer = torch.optim.Adam( [p for p in model.parameters() if p.requires_grad], lr=0.05,)criterion = nn.CrossEntropyLoss()
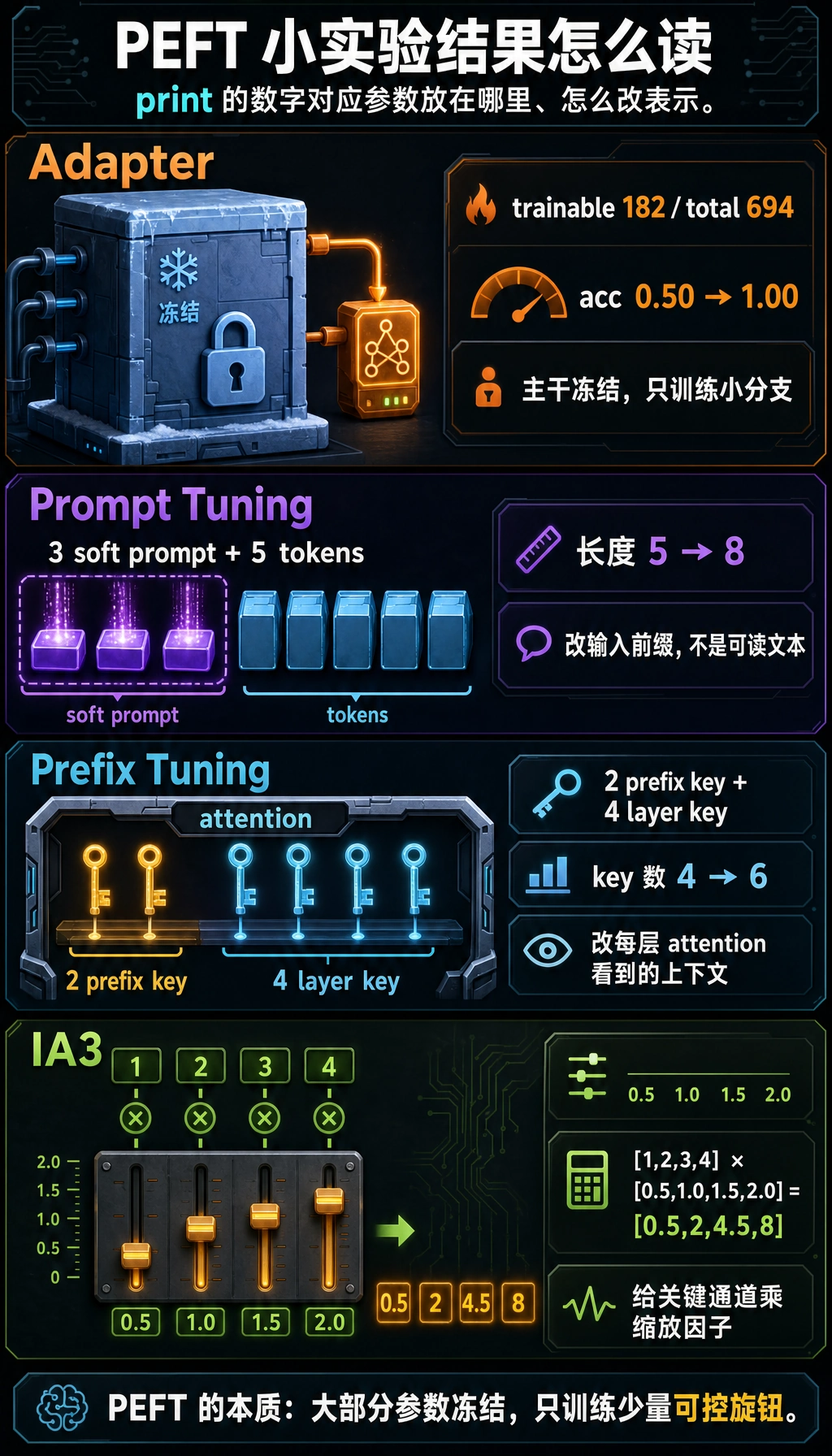
total_params = sum(p.numel() for p in model.parameters())trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print("total params =", total_params)print("trainable params =", trainable_params)
for step in range(201): logits = model(x) loss = criterion(logits, y)
optimizer.zero_grad() loss.backward() optimizer.step()
if step % 50 == 0: preds = logits.argmax(dim=-1) acc = (preds == y).float().mean().item() print(f"step={step:03d} loss={loss.item():.4f} acc={acc:.2f}")
with torch.no_grad(): preds = model(x).argmax(dim=-1) for text, pred in zip([text for text, _ in samples], preds.tolist()): print(f"{text:22s} -> {label_names[pred]}")预期输出:
total params = 694trainable params = 182step=000 loss=0.7183 acc=0.50step=050 loss=0.0000 acc=1.00step=100 loss=0.0000 acc=1.00step=150 loss=0.0000 acc=1.00step=200 loss=0.0000 acc=1.00refund my order -> refundneed a refund -> refundcancel and refund -> refundlogin failed again -> logincannot login account -> loginpassword login problem -> login这段代码到底在教什么?
Section titled “这段代码到底在教什么?”它不是在教你“怎么做一个完整生产级微调”,而是在刻意把重点钉在 Adapter 本身:
FrozenBaseEncoder全部冻结adapter_down和adapter_up是新增小模块classifier负责把适配后的表示映射到标签
真正关键的是这一句:
adapted = hidden + self.adapter_up(torch.tanh(self.adapter_down(hidden)))这就是典型的 Adapter 思路:
- 主干表示先保留
- 旁边走一个小瓶颈分支
- 再以残差方式加回去
为什么这比“只打印方法名”强得多?
Section titled “为什么这比“只打印方法名”强得多?”因为你现在能直接观察三件事:
- 可训练参数只占很小一部分
- 主模型不动,任务仍然能拟合
- 新增能力来自插入的小模块,而不是重训整网
这三点正是 Adapter 的本体。
四、再看三个更短的结构示意
Section titled “四、再看三个更短的结构示意”提示词调优(Prompt Tuning):输入前面拼接软提示
Section titled “提示词调优(Prompt Tuning):输入前面拼接软提示”import torch
token_embeddings = torch.randn(1, 5, 8)soft_prompt = torch.randn(1, 3, 8, requires_grad=True)
combined = torch.cat([soft_prompt, token_embeddings], dim=1)print("原始长度:", token_embeddings.shape[1])print("拼接后长度:", combined.shape[1])预期输出:
原始长度: 5拼接后长度: 8这里最该记住的是:
- soft prompt 本身不是可读文本
- 它是一组训练出来的向量
- 模型看到的是“额外输入 token 的 embedding”
前缀调优(Prefix Tuning):不是改输入长度,而是改每层注意力上下文
Section titled “前缀调优(Prefix Tuning):不是改输入长度,而是改每层注意力上下文”import torch
layer_keys = torch.randn(1, 4, 8)prefix_keys = torch.randn(1, 2, 8, requires_grad=True)
all_keys = torch.cat([prefix_keys, layer_keys], dim=1)print("注意力原始 key 数量:", layer_keys.shape[1])print("加入 prefix 后 key 数量:", all_keys.shape[1])预期输出:
注意力原始 key 数量: 4加入 prefix 后 key 数量: 6这个示意对应的直觉是:
- 普通注意力只看原序列
- Prefix Tuning 让每层注意力额外看到一段可训练前缀
IA3:不是加模块,而是给关键通道乘缩放因子
Section titled “IA3:不是加模块,而是给关键通道乘缩放因子”import torch
hidden = torch.tensor([[1.0, 2.0, 3.0, 4.0]])gate = torch.tensor([0.5, 1.0, 1.5, 2.0], requires_grad=True)
scaled = hidden * gateprint("before:", hidden)print("after :", scaled)预期输出:
before: tensor([[1., 2., 3., 4.]])after : tensor([[0.5000, 2.0000, 4.5000, 8.0000]], grad_fn=<MulBackward0>)IA3 的核心不是“变复杂”,而是“只在最关键的位置做轻量调节”。
五、到底该怎么选?
Section titled “五、到底该怎么选?”如果你最在意任务切换和模块化
Section titled “如果你最在意任务切换和模块化”优先想到:
- Adapter
因为它天然适合:
- 一个底座模型
- 挂很多小适配器
- 按任务切换加载
如果你最在意参数再少一点
Section titled “如果你最在意参数再少一点”可以先关注:
- Prompt Tuning
- IA3
这类方法非常轻,但要注意:
- 参数更少不等于效果一定更好
- 任务复杂时,表达能力可能不够
如果你希望干预更深入一些
Section titled “如果你希望干预更深入一些”可以看:
- Prefix Tuning
因为它影响的不只是输入最前面,而是每一层注意力读上下文的方式。
如果你想要一个“默认优先尝试”的工业方案
Section titled “如果你想要一个“默认优先尝试”的工业方案”现实里很多团队还是会先尝试:
- LoRA / QLoRA
原因很简单:
- 生态成熟
- 工具链丰富
- 社区经验多
所以这节不是要你抛弃 LoRA, 而是让你知道:
LoRA 只是 PEFT 地图里最常用的一块,不是全部。
六、这些误区特别常见
Section titled “六、这些误区特别常见”误区一:参数越少越高级
Section titled “误区一:参数越少越高级”不一定。 参数少意味着:
- 训练便宜
但也可能意味着:
- 表达力更受限制
误区二:方法名越多越说明自己懂了
Section titled “误区二:方法名越多越说明自己懂了”真正要会的是:
- 它改哪里
- 影响哪段信息流
- 为什么适合当前任务
误区三:把“可训练模块”当成唯一重点
Section titled “误区三:把“可训练模块”当成唯一重点”别忘了任务成败还强依赖:
- 数据质量
- 模板格式
- 评估方式
- 是否真的需要微调
学完这一页,至少保留这张证据卡:
- 方法家族
- adapter、prefix/prompt tuning、IA3 或类 LoRA 路线
- 已更改部分
- 哪些参数或 Prompt 被训练
- 拟合
- 此方法适用的场景
- 取舍
- 质量、内存、延迟和工程复杂度
- 决策
- 与 LoRA 和提示基线比较
这一节最该带走的不是四个名词,而是一条主线:
PEFT 的本质,是在尽量不动大模型主体的前提下,选择一个合适的位置放入少量可训练能力。
你以后再遇到新的 PEFT 变体时,也可以先用同样的问题去拆:
- 它把可训练参数放在哪?
- 它会影响输入、层内还是层间?
- 它换来了什么工程收益,又牺牲了什么?
只要这三件事看清楚,方法名就不再会显得神秘。
- 用自己的话解释 Prompt Tuning、Prefix Tuning、Adapter、IA3 分别改的是模型的哪一部分。
- 如果你要给一个底座模型同时适配 20 个不同业务任务,为什么 Adapter 往往很有吸引力?
- 把本节 Adapter 代码中的
bottleneck_dim改大或改小,观察可训练参数数量怎么变化。 - 想一想:如果你的硬件很紧张,但任务又比较复杂,你会优先尝试哪种 PEFT 方法?为什么?
参考实现与讲解
- Prompt Tuning 学的是靠近输入的 soft prompt 向量;Prefix Tuning 学的是影响 attention 的 prefix state;Adapter 在层内插入小型可训练模块;IA3 学的是调节 activation 的缩放向量。
- Adapter 可以让每个任务保留一个小型 task-specific 模块,同时共享同一个底座模型。相比维护很多完整模型副本,它更方便存储、切换和管理多任务。
bottleneck_dim越大,adapter 容量和可训练参数越多;越小则更省显存,也更不容易过拟合,但可能不足以承载复杂行为变化。- 硬件很紧、任务又复杂时,LoRA 或紧凑 Adapter 往往是实用的第一选择。纯 Prompt Tuning 更便宜,但任务需要较深行为适配时可能太弱。