A.3 AI Development History: 15 Stages and Key Papers
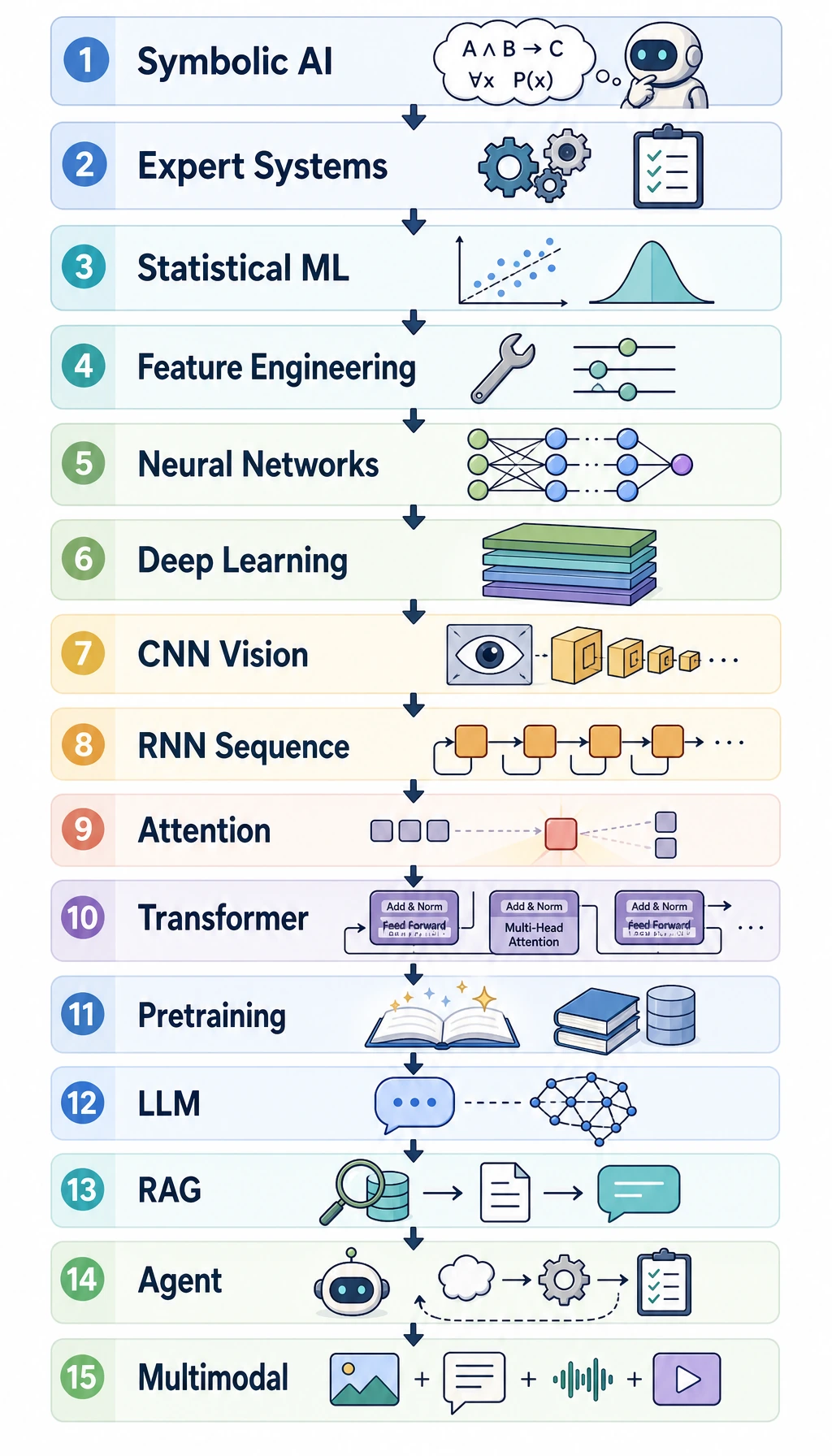
This appendix is optional. Read it when you want a historical “where did this come from?” map, not when you need to memorize papers for the first pass.
Use it in this order:
- Look at the 15-stage picture.
- Scan the stage table.
- Pick only the stage that matches the chapter you are studying.
- Come back later when a paper or algorithm name appears again.
The 15-stage map
Section titled “The 15-stage map”| Stage | Beginner meaning | Course anchor |
|---|---|---|
| 1. The AI question | Can a machine show intelligent behavior? | Intro |
| 2. Symbolic AI | Humans write rules; machines reason with rules | Background |
| 3. Expert systems | Domain knowledge becomes rule-based software | System thinking |
| 4. Probability and statistics | Use uncertainty and evidence, not only fixed rules | Chapter 4 |
| 5. Classic machine learning | Learn patterns from data and features | Chapter 5 |
| 6. Early neural networks | A model learns simple decision boundaries | Chapters 5-6 |
| 7. Backpropagation | Multi-layer networks become trainable | Chapter 6 |
| 8. Kernel and ensemble era | SVM, trees, forests, and boosting make ML practical | Chapter 5 |
| 9. Deep learning breakthrough | Data + GPUs + deep networks unlock vision and speech | Chapters 6 and 10 |
| 10. Embeddings and sequence models | Text becomes vectors; sequences become learnable | Chapter 11 |
| 11. Transformer and pretraining | Attention makes large-scale language models practical | Chapters 6-7 |
| 12. LLM and alignment | Models become instruction-following assistants | Chapter 7 |
| 13. RAG | Models connect to external knowledge and citations | Chapter 8 |
| 14. Agent and tool use | Models plan, call tools, and leave traces | Chapter 9 |
| 15. Multimodal and AIGC | AI works across text, image, speech, video, and generation | Chapter 12 |
The pattern is simple: every stage solves a bottleneck from the previous stage, then creates a new engineering problem.
Read the main storyline as a relay
Section titled “Read the main storyline as a relay”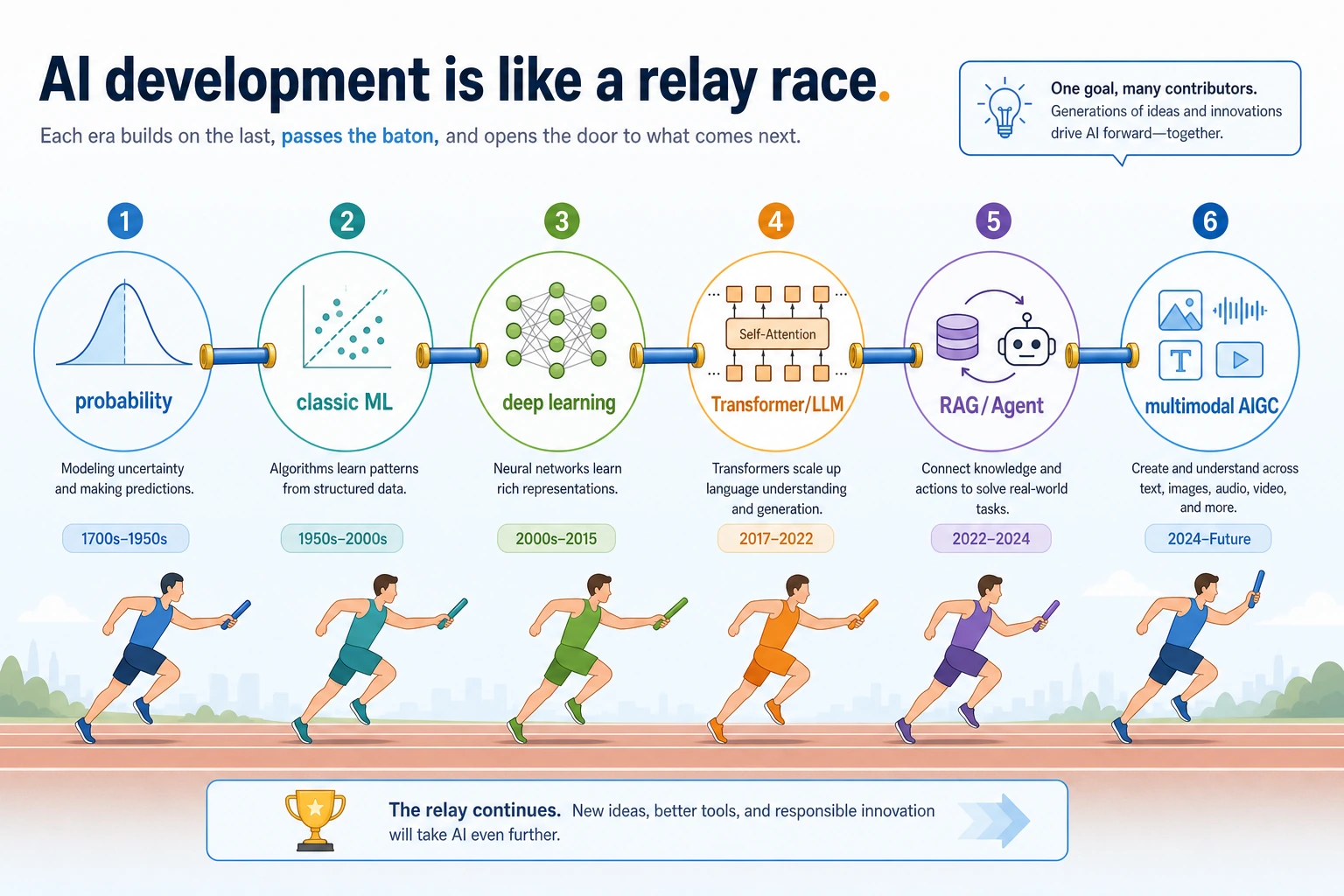
AI history is easier to remember as a relay than as a list of names:
| Relay handoff | What changed |
|---|---|
| Rules -> probability | Systems moved from fixed logic to uncertain evidence |
| Probability -> ML | Models started learning patterns from data |
| ML -> deep learning | Features became learned, not fully hand-designed |
| Deep learning -> Transformer | Sequence modeling became easier to scale |
| LLM -> RAG / Agent | Models connected to knowledge, tools, and workflows |
| Text -> multimodal | AI started understanding and generating multiple media types |
Six turning points worth remembering
Section titled “Six turning points worth remembering”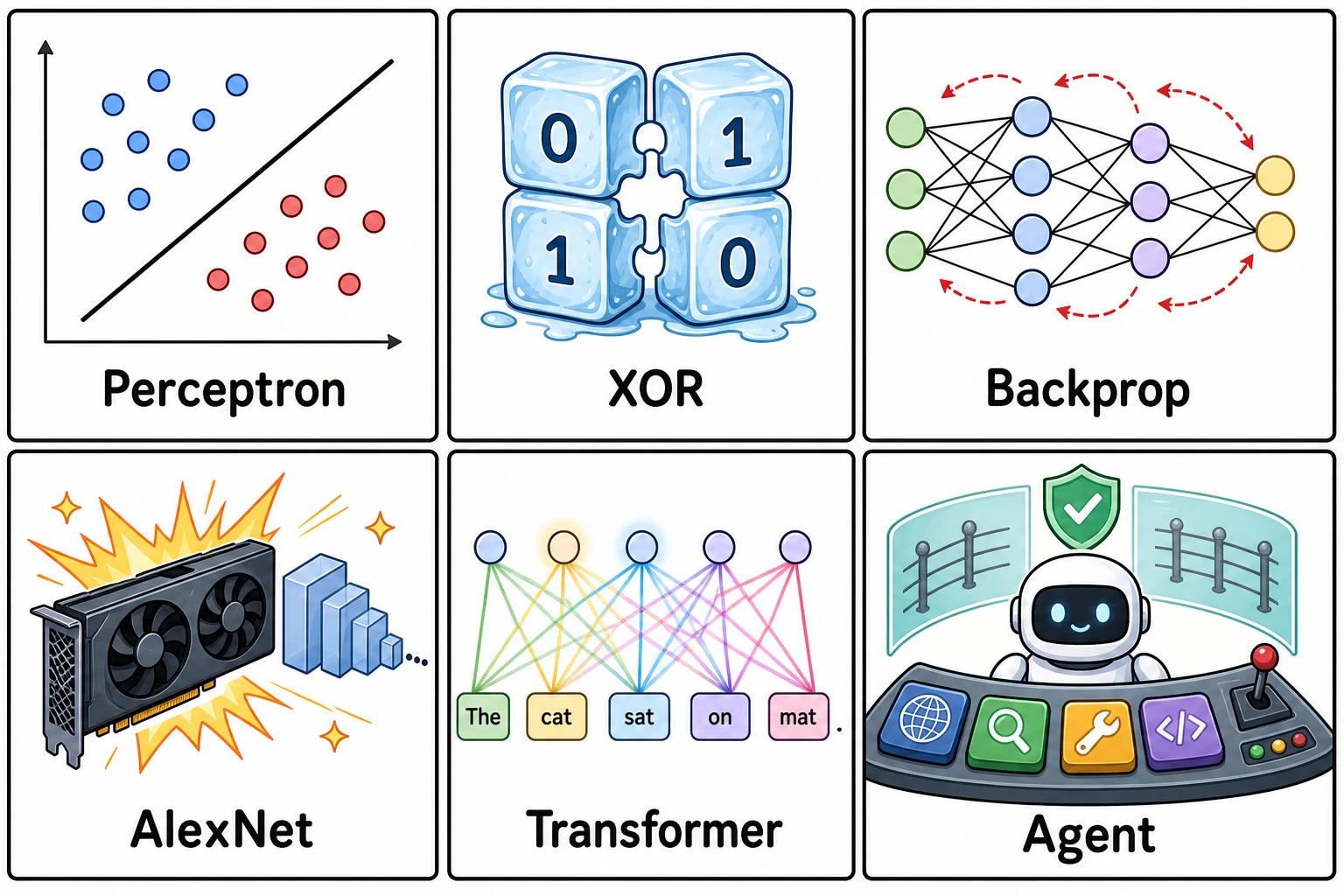
| Turning point | Why beginners should care |
|---|---|
| Perceptron | The first strong feeling that machines might learn from data |
| XOR limitation | A reminder that simple linear models are not enough |
| Backpropagation | Multi-layer neural networks became trainable in practice |
| AlexNet | Data, GPUs, and deep CNNs made deep learning explode |
| Transformer | Attention replaced the old sequence-modeling main line |
| RAG / Agent | Models moved from answering text to using knowledge and tools |
Do not memorize every year first. Remember the shape: hope, setback, repair, scale, and engineering.
How to read a paper node
Section titled “How to read a paper node”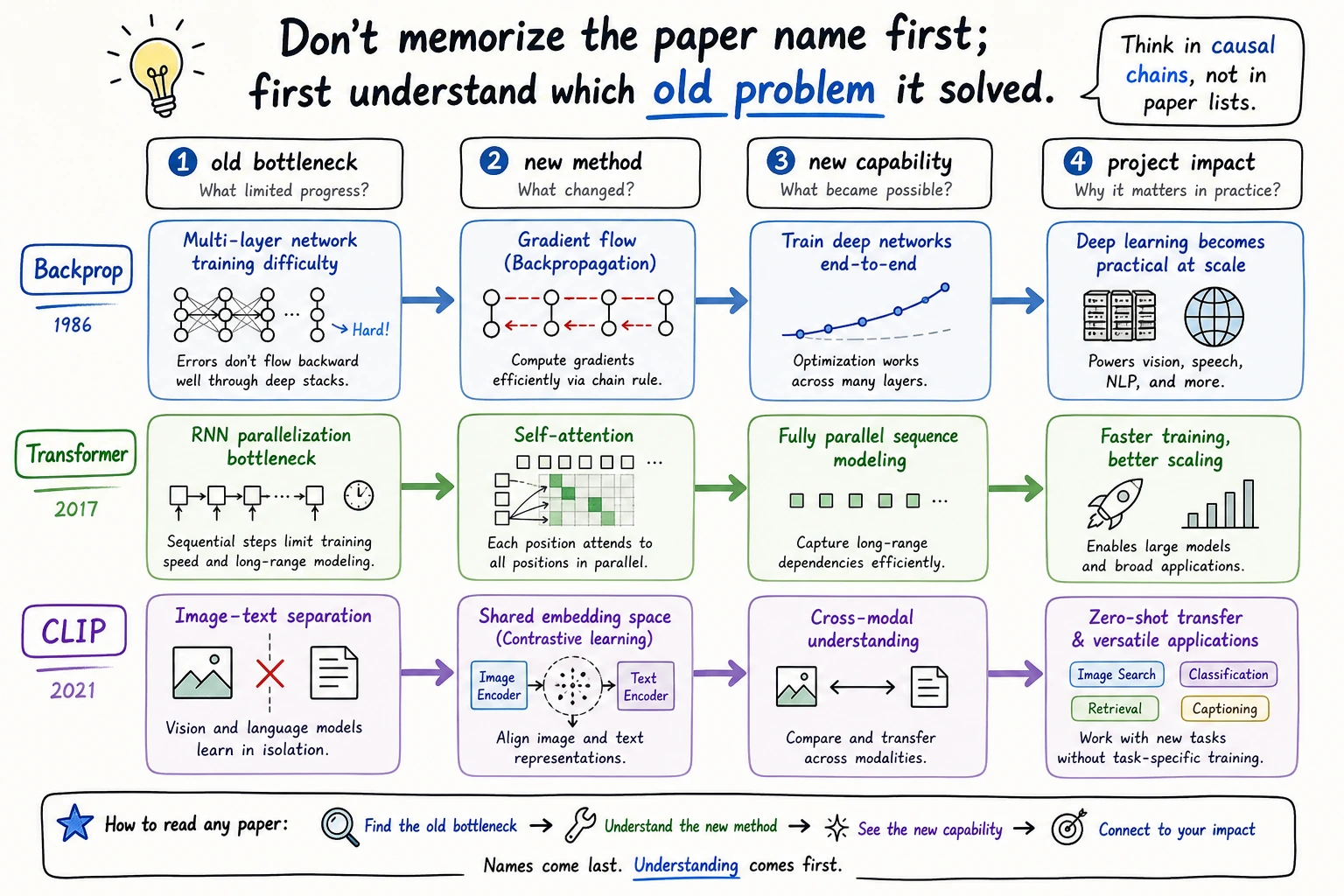
For any paper or algorithm, ask only four questions first. Keep the example short enough to fit in a note card:
| Question | Beginner answer pattern |
|---|---|
| Old bottleneck | Name the old limitation. For Transformer, RNNs were hard to parallelize and long paths were costly. |
| New method | Name the mechanism. For Transformer, self-attention became the key move. |
| New capability | Name what became easier. Large-scale sequence modeling became practical. |
| Projects changed | Name downstream systems. LLM, RAG, Agent, and multimodal projects all inherit this shift. |
This is enough for beginner-level historical understanding. Formula details can wait until the relevant chapter.
Key nodes by course line
Section titled “Key nodes by course line”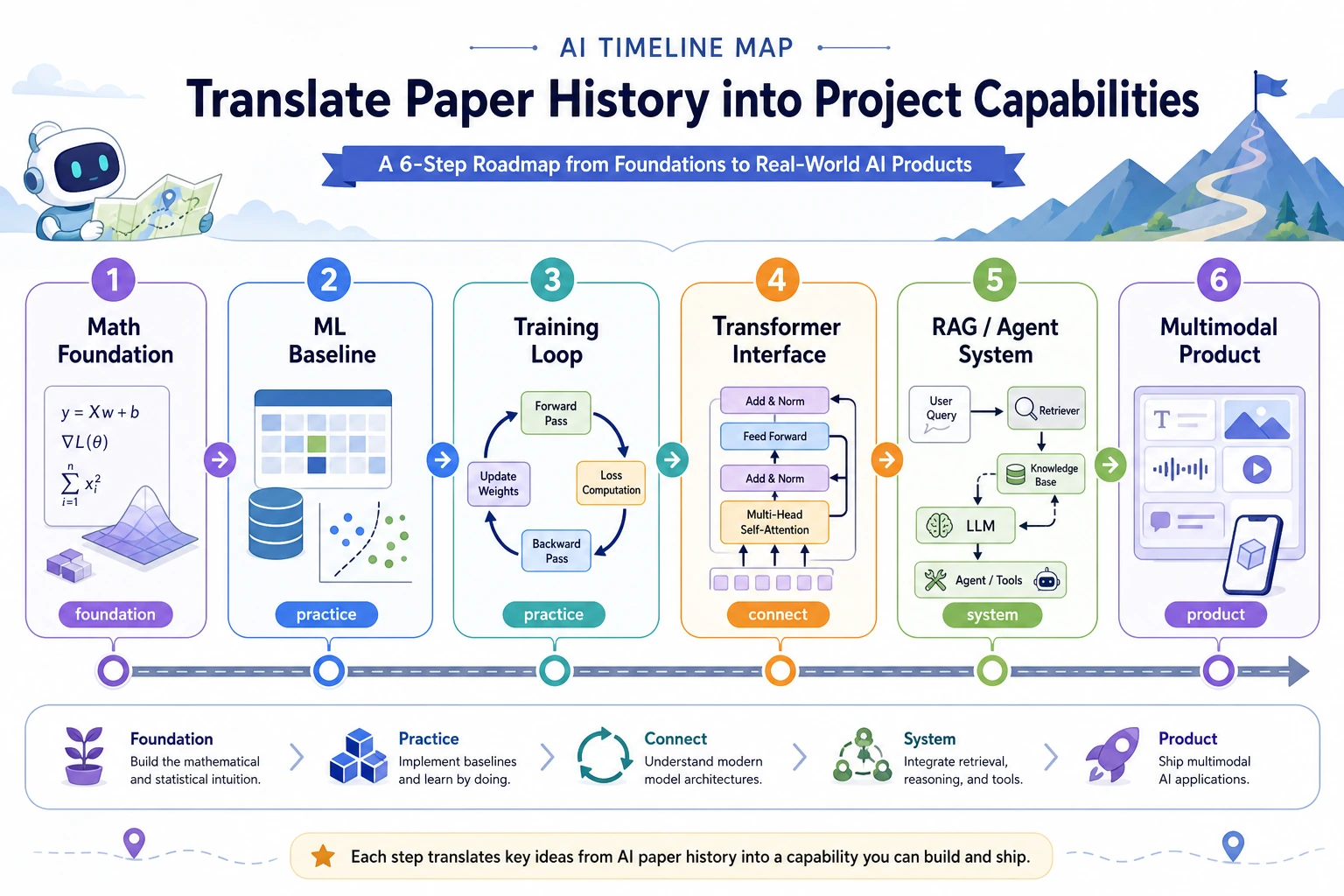
| Course line | Key nodes to recognize first | Why they matter |
|---|---|---|
| Math foundations | Bayes, Shannon, maximum likelihood, EM | Probability, information, and loss functions |
| Classic ML | CART, SVM, Random Forest, AdaBoost, XGBoost | Strong baselines and tabular-data engineering |
| Neural networks | Perceptron, XOR, Backpropagation, LSTM, AlexNet, ResNet | Why depth, gradients, data, and compute matter |
| NLP and LLM | Word2Vec, Seq2Seq, Transformer, BERT, GPT, InstructGPT | The path from word vectors to assistants |
| RAG and Agent | RAG, Chain-of-Thought, ReAct, Toolformer | External knowledge, reasoning traces, and tool use |
| Multimodal | CLIP, DDPM, Latent Diffusion, Whisper, SAM | Text, image, speech, video, and generation pipelines |
Some entries are landmark papers. Some are algorithm families or historical turning points. That is fine. The useful question is always: what problem did this node make easier?
Optional visual branches
Section titled “Optional visual branches”Use these only when you are studying the related chapter. Read each branch as a small answer to two questions: what bottleneck changed, and which course chapter should I revisit?
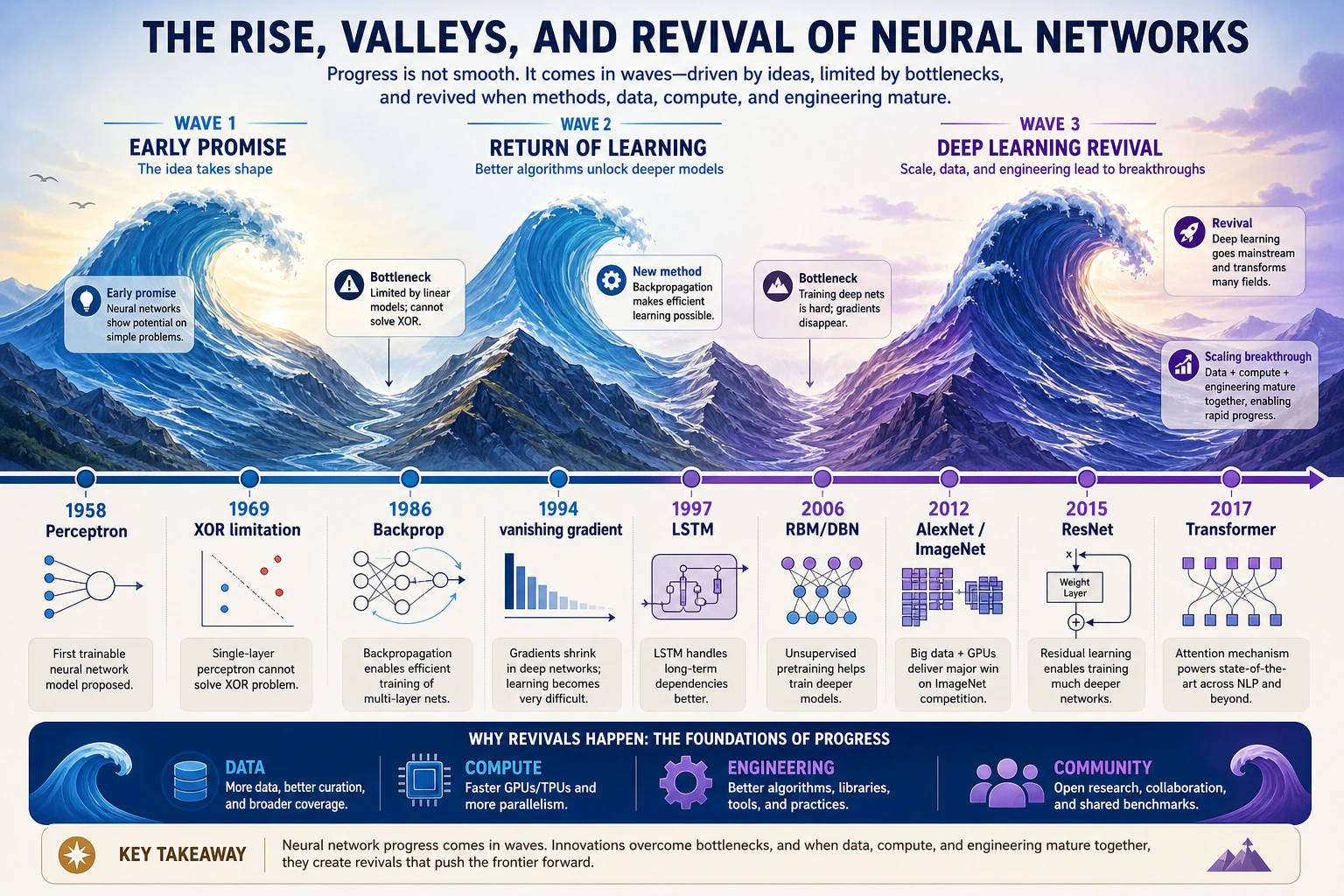
Start with the neural-network waves when Chapters 6 and 7 mention perceptron, backpropagation, CNN, or Transformer. Notice where enthusiasm rises, falls, and returns with data and compute.
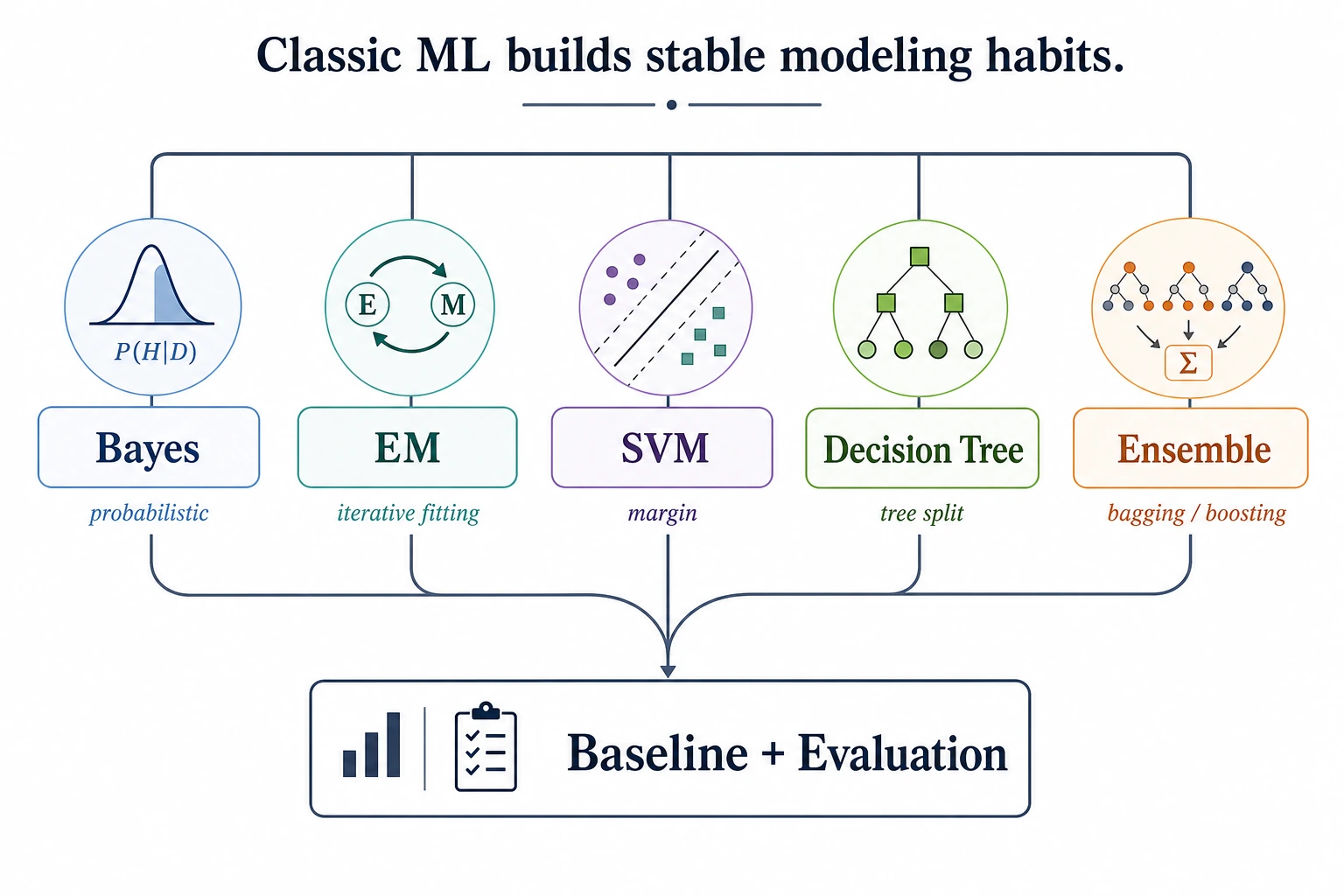
Use the classic ML branch when Chapter 5 names SVM, trees, forests, boosting, or XGBoost. Compare which branch is about decision boundaries, which is about ensembles, and which is about strong tabular baselines.
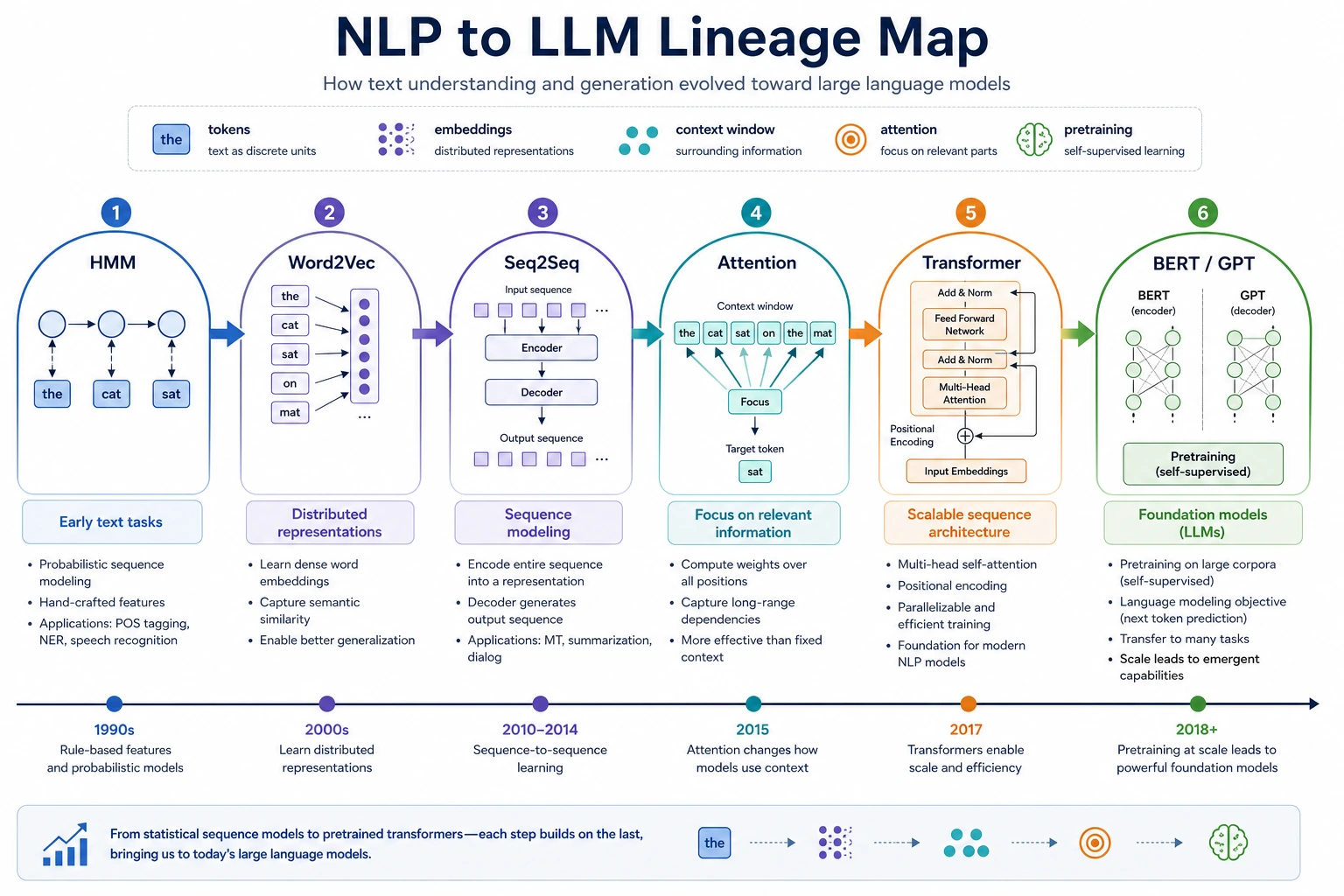
Use the NLP branch when Chapter 11 introduces tokenization, embeddings, Seq2Seq, BERT, or GPT. Read it as the path from word meaning to instruction-following assistants.
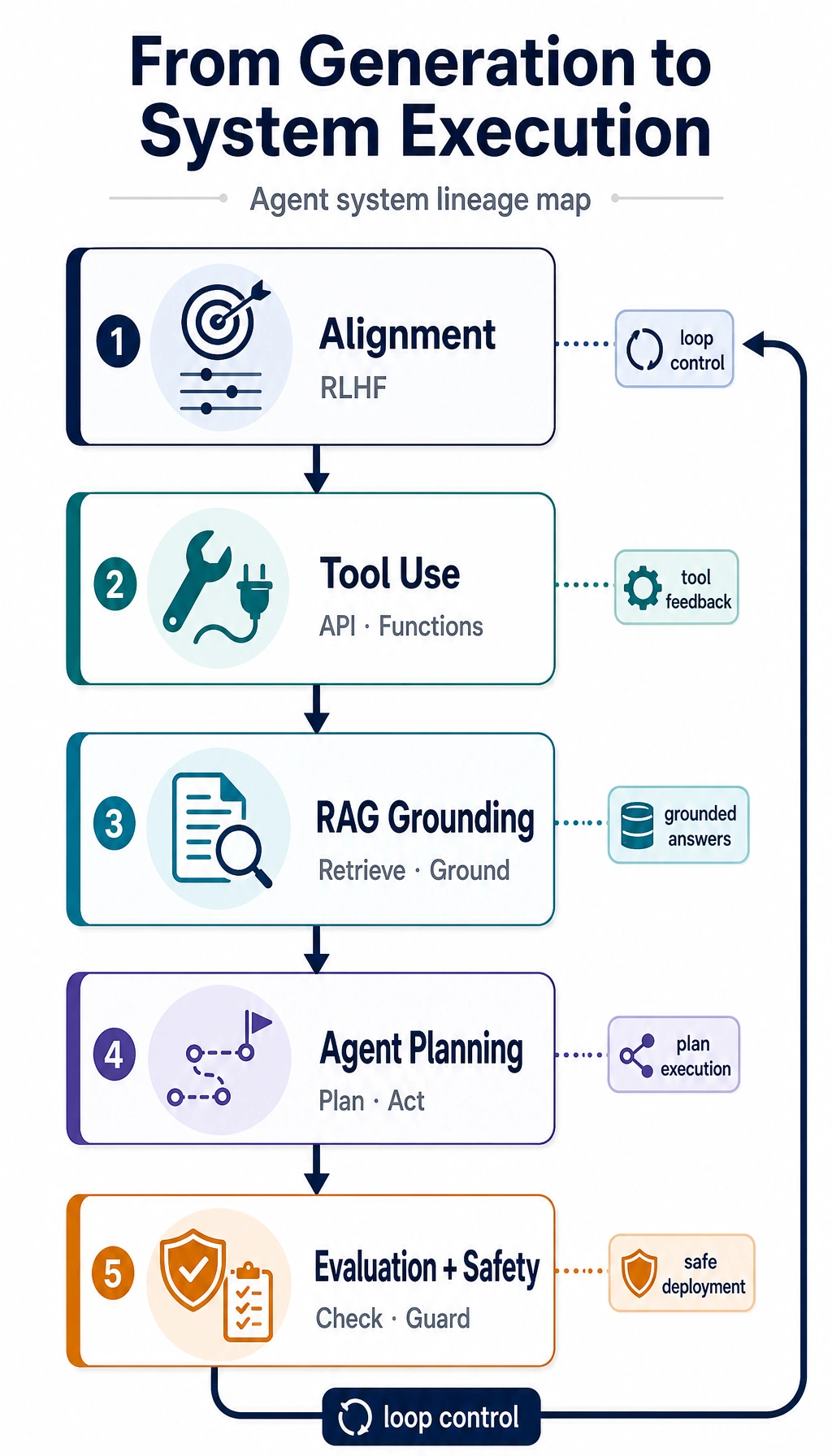
Use this systems branch when Chapters 7-9 discuss instruction tuning, RLHF, tool use, traces, or deployment. The important pattern is that model quality and system control improve together.
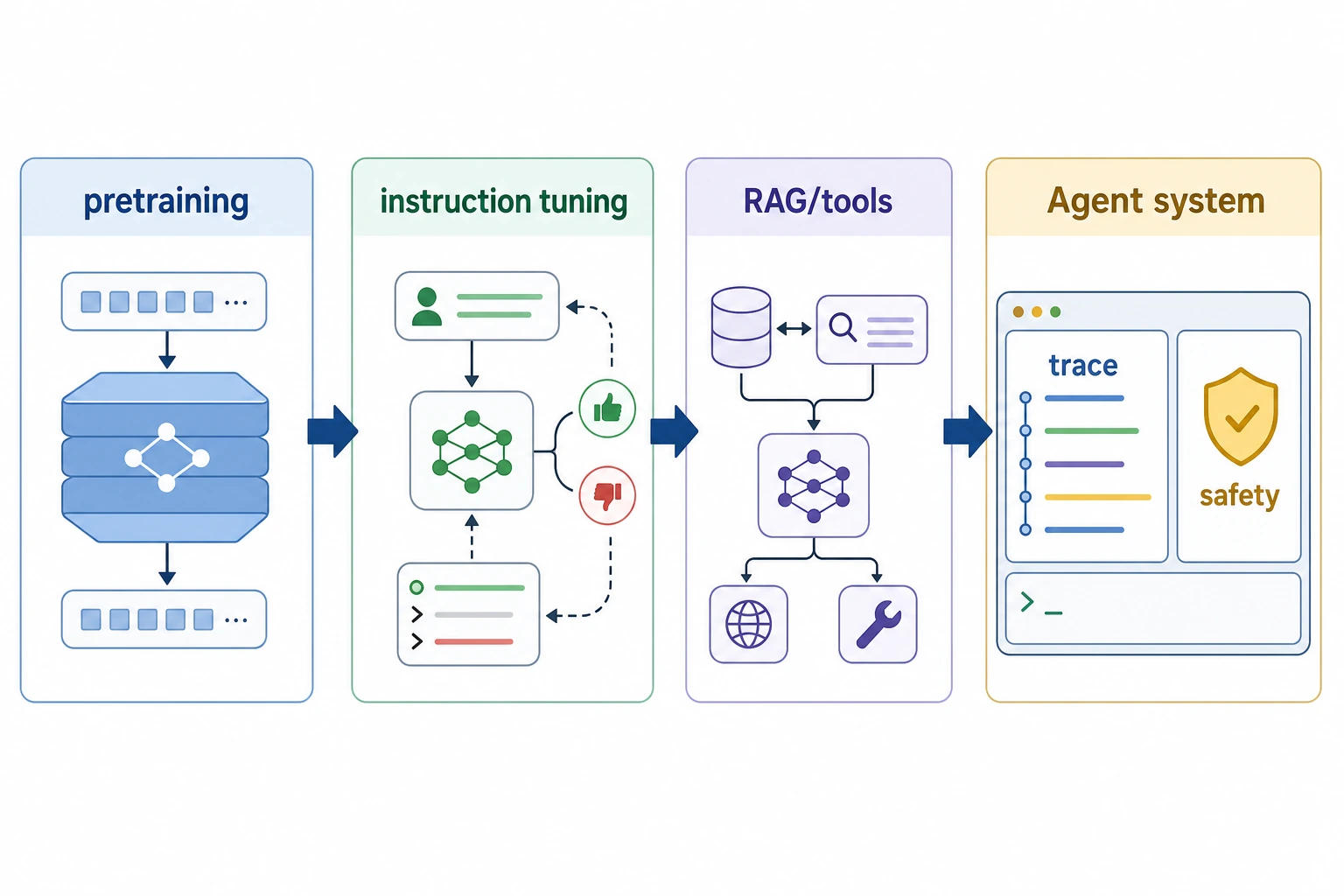
Use the engineering timeline when you are deciding whether a project needs only prompting, retrieval, tools, or a full Agent loop. Do not skip the trace and evaluation checkpoints.
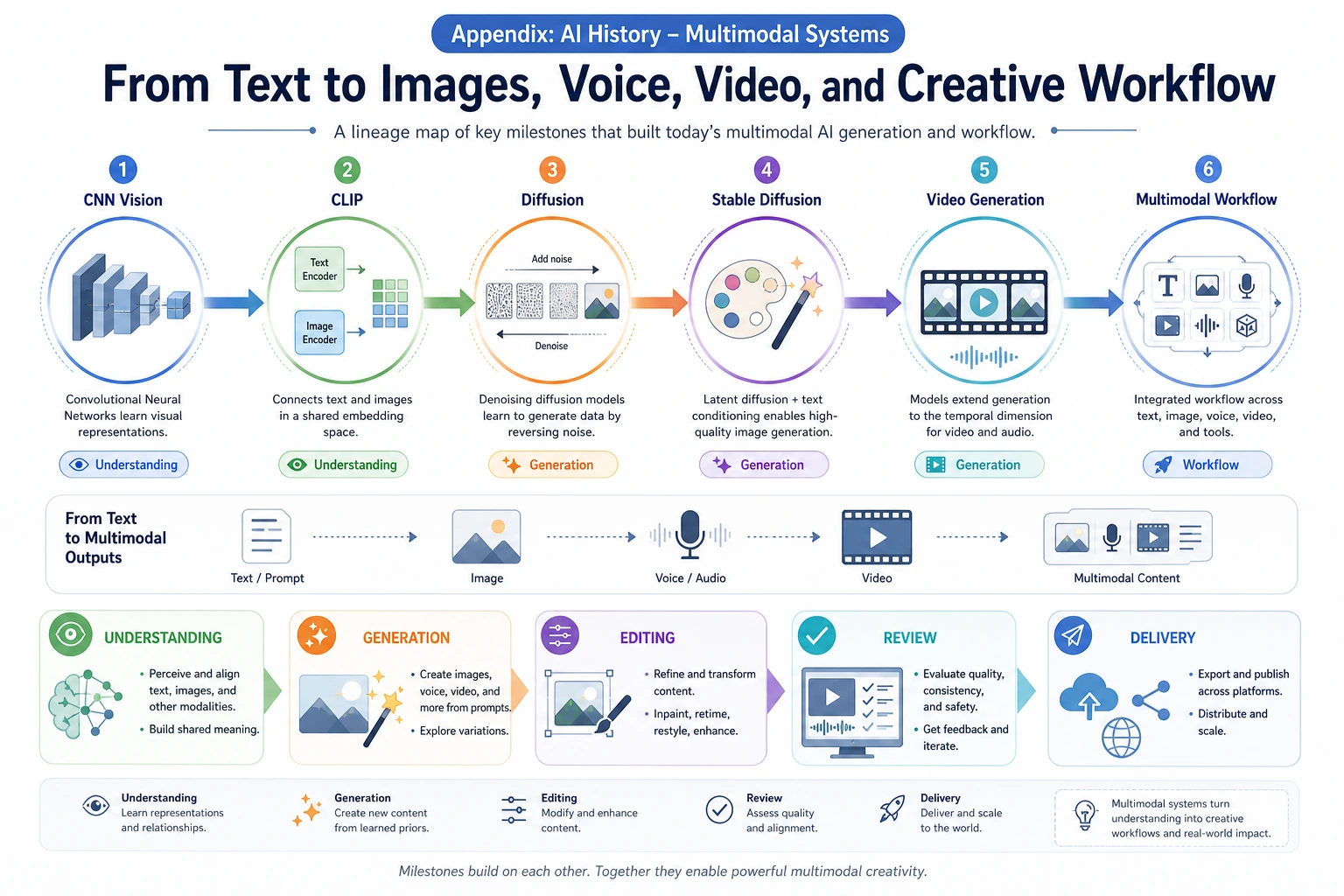
Use the multimodal branch with Chapter 12. Follow how text, image, speech, and segmentation models become reusable parts of a generation pipeline.
Fast chapter lookup
Section titled “Fast chapter lookup”| If you see this name | Go back to |
|---|---|
| Bayes, MLE, entropy, EM | Chapter 4 math foundations |
| SVM, Random Forest, XGBoost | Chapter 5 machine learning |
| Perceptron, backpropagation, CNN, LSTM, Transformer | Chapter 6 deep learning |
| GPT, RLHF, LoRA, instruction tuning | Chapter 7 LLM principles |
| RAG, vector retrieval, citations | Chapter 8 RAG |
| Chain-of-Thought, ReAct, Toolformer, tool use | Chapter 9 Agent |
| AlexNet, ResNet, YOLO, SAM | Chapter 10 computer vision |
| Word2Vec, Seq2Seq, BERT, GPT | Chapter 11 NLP |
| CLIP, diffusion, Whisper, multimodal generation | Chapter 12 multimodal |
Mini exercise
Section titled “Mini exercise”Pick any 3 nodes and rewrite them in project language:
Example project card:
- Node:
Attention Is All You Need - Old bottleneck: RNNs were not ideal for long sequences or parallel training.
- New method: self-attention became the main line of sequence modeling.
- Projects affected: LLMs, RAG, Agent systems, multimodal models.
- Course chapter to revisit: Chapters 6, 7, 8, and 9.
The goal is not to recite history. The goal is to connect a historical node to a real capability you may build later.
Project reference and review notes
One acceptable answer could use these three nodes:
Backpropagation
- Old bottleneck: multilayer neural networks were hard to train effectively.
- New method: gradients could be propagated layer by layer.
- Projects affected: image classifiers, language models, and nearly all deep learning systems.
- Course chapter to revisit: Chapter 6.
RAG
- Old bottleneck: language models could answer fluently without grounded external evidence.
- New method: retrieval adds relevant documents before generation.
- Projects affected: knowledge assistants, policy Q&A, citation-aware research tools.
- Course chapter to revisit: Chapter 8.
CLIP
- Old bottleneck: image and text models were often trained in separate spaces.
- New method: contrastive training aligned images and text.
- Projects affected: image search, multimodal retrieval, image generation guidance.
- Course chapter to revisit: Chapter 12.
The answer is strong when each node names a real bottleneck, a method shift, an affected project type, and a chapter to revisit. It is weak if it only lists famous names without explaining what became easier.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Timeline Anchor
- stage, key idea, representative paper/system, and why it mattered
- Chapter Link
- which course chapter this milestone helps explain
- Memory Hook
- diagram, comic panel, or one-sentence historical turn
- Failure Check
- memorizing names without understanding the problem each milestone solved
- Expected Output
- a short timeline note connected to at least one project decision