6.4.3 LSTM and GRU
Learning Objectives
Section titled “Learning Objectives”- Explain why plain RNNs struggle with long dependencies.
- Understand LSTM cell state
c_tand hidden stateh_t. - Interpret forget, input, output, update, and reset gates.
- Run PyTorch
nn.LSTMandnn.GRUshape checks. - Train a tiny gated recurrent model on a memory task.
See the Gate Idea First
Section titled “See the Gate Idea First”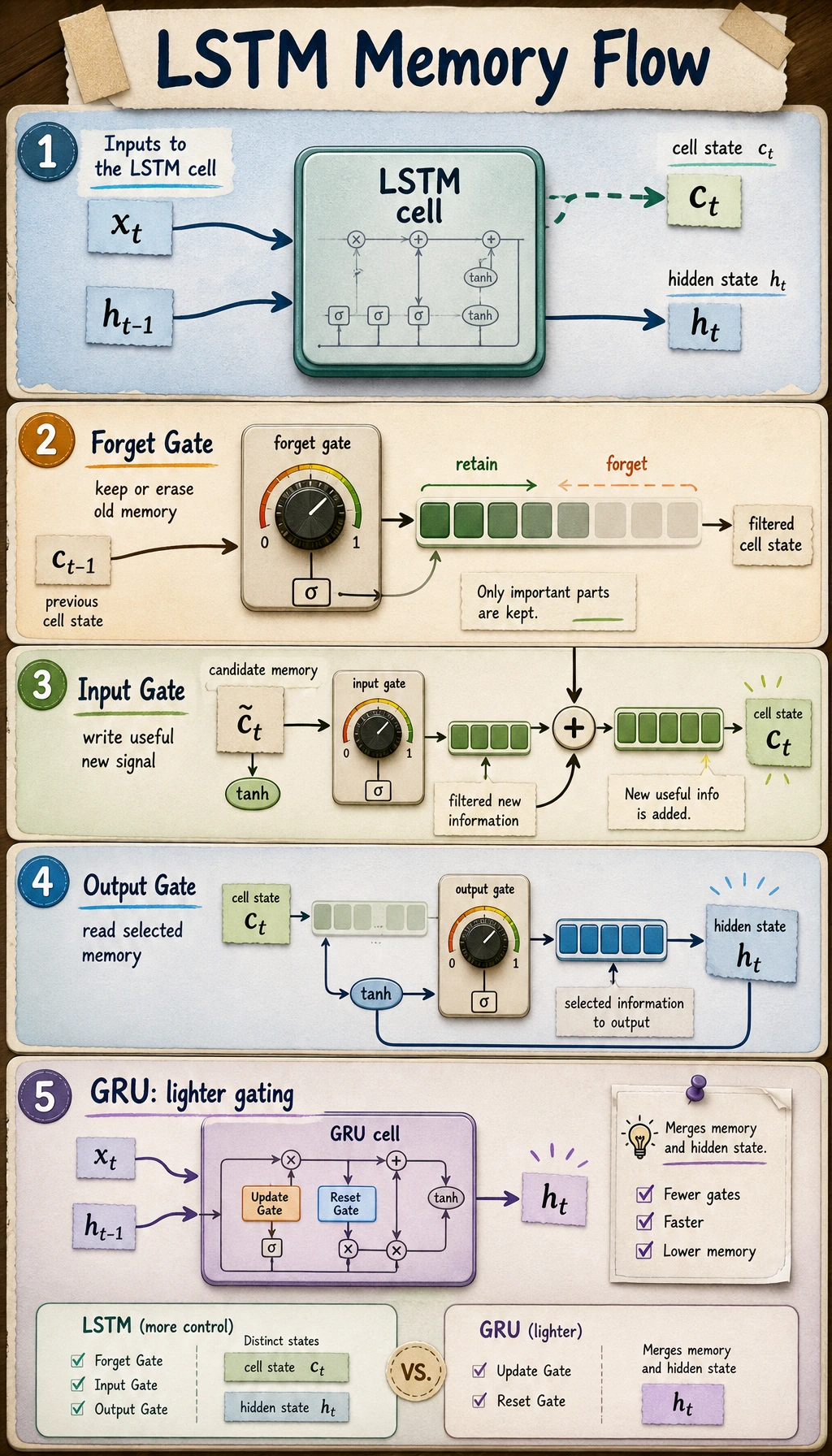
Read the picture like this:
A gate is a learned value between 0 and 1.
| Gate value | Meaning |
|---|---|
close to 0 | mostly block the information |
close to 1 | mostly let the information pass |
This is the practical difference from a plain RNN: memory is no longer just overwritten at every step.
Why Plain RNN Is Not Enough
Section titled “Why Plain RNN Is Not Enough”Plain RNNs summarize the past into one hidden state. That works for short sequences, but long sequences create two problems:
| Problem | Intuition |
|---|---|
| early information gets washed out | the hidden state is rewritten many times |
| gradients vanish | training signal becomes weak when backpropagated far back in time |
LSTM and GRU are not “deeper RNNs.” They are memory-control designs.
LSTM: Cell State Plus Three Gates
Section titled “LSTM: Cell State Plus Three Gates”
An LSTM keeps two states:
| State | Role |
|---|---|
c_t | cell state, the longer-term memory path |
h_t | hidden state, the output exposed at the current step |
The three main gates:
| Gate | Question it answers |
|---|---|
| forget gate | how much old memory should stay? |
| input gate | how much new information should be written? |
| output gate | how much memory should be exposed now? |
Lab 1: Scalar LSTM Gate Demo
Section titled “Lab 1: Scalar LSTM Gate Demo”This small scalar version keeps the idea visible without matrix notation.
import numpy as np
def sigmoid(x): return 1 / (1 + np.exp(-x))
c_prev = 0.8forget_gate = sigmoid(1.0)input_gate = sigmoid(0.2)output_gate = sigmoid(0.7)c_tilde = np.tanh(0.9)
c_t = forget_gate * c_prev + input_gate * c_tildeh_t = output_gate * np.tanh(c_t)
print("scalar_lstm_lab")for name, value in [ ("forget_gate", forget_gate), ("input_gate", input_gate), ("output_gate", output_gate), ("c_t", c_t), ("h_t", h_t),]: print(f"{name:<12} {float(value):.4f}")Expected output:
scalar_lstm_labforget_gate 0.7311input_gate 0.5498output_gate 0.6682c_t 0.9787h_t 0.5028Read the update as:
new cell memory = keep part of old memory + write part of new candidateThat is the core of LSTM.
GRU: A Lighter Gated Model
Section titled “GRU: A Lighter Gated Model”GRU has fewer moving parts than LSTM. It does not keep a separate cell state. The hidden state carries the memory.
| Gate | Role |
|---|---|
| update gate | controls how much old state and new candidate are mixed |
| reset gate | controls how much old state is used when making the candidate |
Lab 2: Scalar GRU Gate Demo
Section titled “Lab 2: Scalar GRU Gate Demo”import numpy as np
def sigmoid(x): return 1 / (1 + np.exp(-x))
h_prev = 0.7x_t = 1.1update_gate = sigmoid(0.8)reset_gate = sigmoid(-0.3)
h_candidate = np.tanh(x_t + reset_gate * h_prev)h_t = (1 - update_gate) * h_prev + update_gate * h_candidate
print("scalar_gru_lab")for name, value in [ ("update_gate", update_gate), ("reset_gate", reset_gate), ("h_candidate", h_candidate), ("h_t", h_t),]: print(f"{name:<12} {float(value):.4f}")Expected output:
scalar_gru_labupdate_gate 0.6900reset_gate 0.4256h_candidate 0.8849h_t 0.8276Quick memory aid:
LSTM = more explicit memory managementGRU = lighter gated memory managementLab 3: PyTorch LSTM and GRU Shapes
Section titled “Lab 3: PyTorch LSTM and GRU Shapes”import torchfrom torch import nn
torch.manual_seed(42)
x = torch.randn(4, 6, 8)lstm = nn.LSTM(input_size=8, hidden_size=16, batch_first=True)gru = nn.GRU(input_size=8, hidden_size=16, batch_first=True)
lstm_out, (lstm_h, lstm_c) = lstm(x)gru_out, gru_h = gru(x)
print("shape_lab")print("lstm_out:", tuple(lstm_out.shape))print("lstm_h :", tuple(lstm_h.shape))print("lstm_c :", tuple(lstm_c.shape))print("gru_out :", tuple(gru_out.shape))print("gru_h :", tuple(gru_h.shape))Expected output:
shape_lablstm_out: (4, 6, 16)lstm_h : (1, 4, 16)lstm_c : (1, 4, 16)gru_out : (4, 6, 16)gru_h : (1, 4, 16)The visible API difference:
- LSTM returns
(h, c); - GRU returns only
h.
Lab 4: Train a Memory Task
Section titled “Lab 4: Train a Memory Task”The label depends on the first value in the sequence. The middle values are noisy, so the model must keep early information.
import torchfrom torch import nn
torch.manual_seed(42)
def build_dataset(n=160, seq_len=10): X, y = [], [] for _ in range(n): first = 1.0 if torch.rand(1).item() > 0.5 else -1.0 seq = torch.randn(seq_len, 1) * 0.25 seq[0, 0] = first X.append(seq) y.append(1 if first > 0 else 0) return torch.stack(X), torch.tensor(y)
X, y = build_dataset()
class GRUClassifier(nn.Module): def __init__(self): super().__init__() self.gru = nn.GRU(input_size=1, hidden_size=8, batch_first=True) self.fc = nn.Linear(8, 2)
def forward(self, x): out, h = self.gru(x) return self.fc(h[-1])
model = GRUClassifier()loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
for epoch in range(1, 81): logits = model(X) loss = loss_fn(logits, y)
optimizer.zero_grad() loss.backward() optimizer.step()
if epoch == 1 or epoch % 20 == 0: acc = (logits.argmax(1) == y).float().mean().item() print(f"memory epoch={epoch:02d} loss={loss.item():.4f} acc={acc:.3f}")
with torch.no_grad(): final_acc = (model(X).argmax(1) == y).float().mean().item()
print("final_acc", round(final_acc, 3))Expected output:
memory epoch=01 loss=0.7465 acc=0.431memory epoch=20 loss=0.6691 acc=0.569memory epoch=40 loss=0.0023 acc=1.000memory epoch=60 loss=0.0001 acc=1.000memory epoch=80 loss=0.0001 acc=1.000final_acc 1.0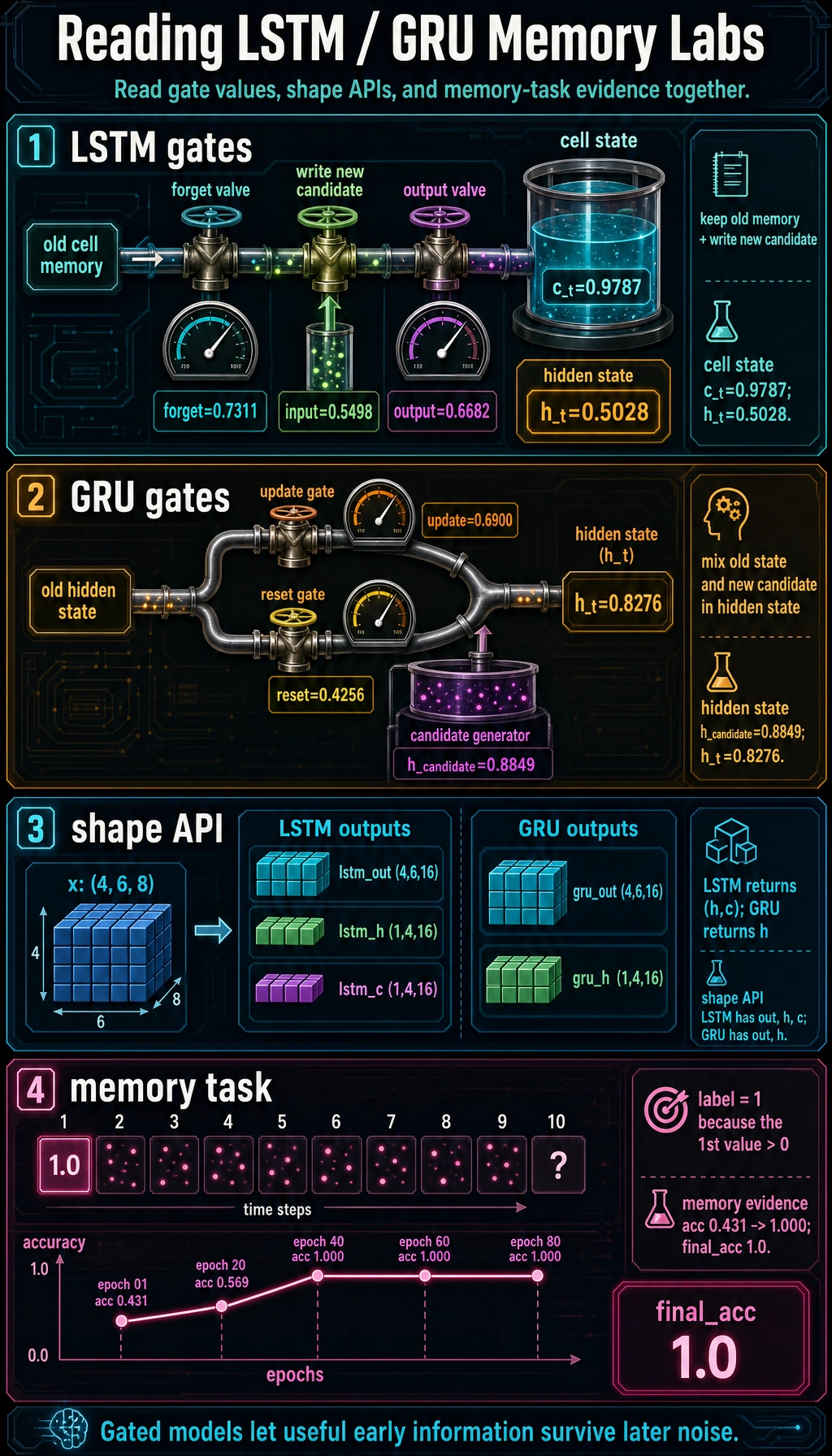
This toy task is small, but it captures the reason gated recurrent models exist: the model needs to preserve useful early information through noisy later steps.
Evidence to Keep
Section titled “Evidence to Keep”Keep one gated-memory note:
- Lstm State
- returns hidden state h and cell state c
- Gru State
- returns hidden state h only
- Gate Meaning
- values near 0 block, values near 1 pass
- Memory Task
- label depends on the first time step
- Result
- final_acc reaches 1.0 on the toy memory task
- Limit
- validate on held-out sequences before trusting the architecture
LSTM or GRU?
Section titled “LSTM or GRU?”| Situation | Good starting point |
|---|---|
| quick baseline | GRU |
| small model budget | GRU |
| long dependency is central | LSTM and GRU both worth trying |
| you need explicit cell state intuition | LSTM |
| modern long text tasks | often Transformer instead |
In practice, compare validation results. Architecture names are less important than whether the model fits the data and deployment constraints.
Common Mistakes
Section titled “Common Mistakes”| Mistake | Fix |
|---|---|
| thinking LSTM/GRU are just deeper RNNs | think “memory control,” not depth |
confusing out, h, and c | out per step, h final hidden, c LSTM cell state |
| assuming gates never forget important info | gates are learned and can still fail |
| using high learning rate on unstable sequences | lower LR, clip gradients if needed |
| using only training accuracy | validate on held-out sequences |
Exercises
Section titled “Exercises”- Change
forget_gatein Lab 1 by replacingsigmoid(1.0)withsigmoid(-1.0). How doesc_tchange? - Change the memory task so the label depends on the last value. Is it easier?
- Replace
GRUClassifierwith anLSTMClassifierand compare the output API. - Increase
seq_lenfrom10to30. Does training become harder? - Explain why GRU has fewer states than LSTM but can still work well.
Reference implementation and walkthrough
sigmoid(-1.0)is smaller thansigmoid(1.0), so less previous cell memory is kept.c_tshould rely more on the new candidate.- If the label depends on the last value, the task is usually easier because the model does not need to preserve early information for many steps.
- GRU returns an output sequence and final hidden state; LSTM returns an output sequence plus
(h_n, c_n). The classifier must unpack the LSTM tuple correctly. - Longer sequences can make training harder because memory must be preserved longer and gradients travel through more steps.
- GRU combines memory control into a lighter state design. It can work well when the task does not need the extra separation between cell state and hidden state.
Key Takeaways
Section titled “Key Takeaways”- LSTM and GRU add gates to control memory flow.
- LSTM has both
c_tandh_t; GRU uses a lighter hidden-state design. - Gates are learned soft switches between
0and1. - Use validation results to choose between LSTM and GRU.
- Gated recurrent models are an important bridge from plain RNNs to attention-based sequence modeling.