9.4.6 Memory Engineering Implementation
Learning Objectives
Section titled “Learning Objectives”- Understand the core decisions in memory engineering: write, retrieve, expire, compress
- Learn how to design a minimal, working memory read/write pipeline
- Understand why “more memory” does not mean “better results”
- Use a runnable example to master basic memory scoring and cleanup
What Does Memory Engineering Actually Solve?
Section titled “What Does Memory Engineering Actually Solve?”A memory system is not a “bucket”, but a process with policies
Section titled “A memory system is not a “bucket”, but a process with policies”If we dump all conversations and tool results into long-term memory, it may look complete in the short term, but in the long run it usually leads to:
- More and more noise
- Lower retrieval hit rate
- Higher token cost
- Important facts getting buried instead
So the core of memory engineering is not “store everything”, but “store with policies.”
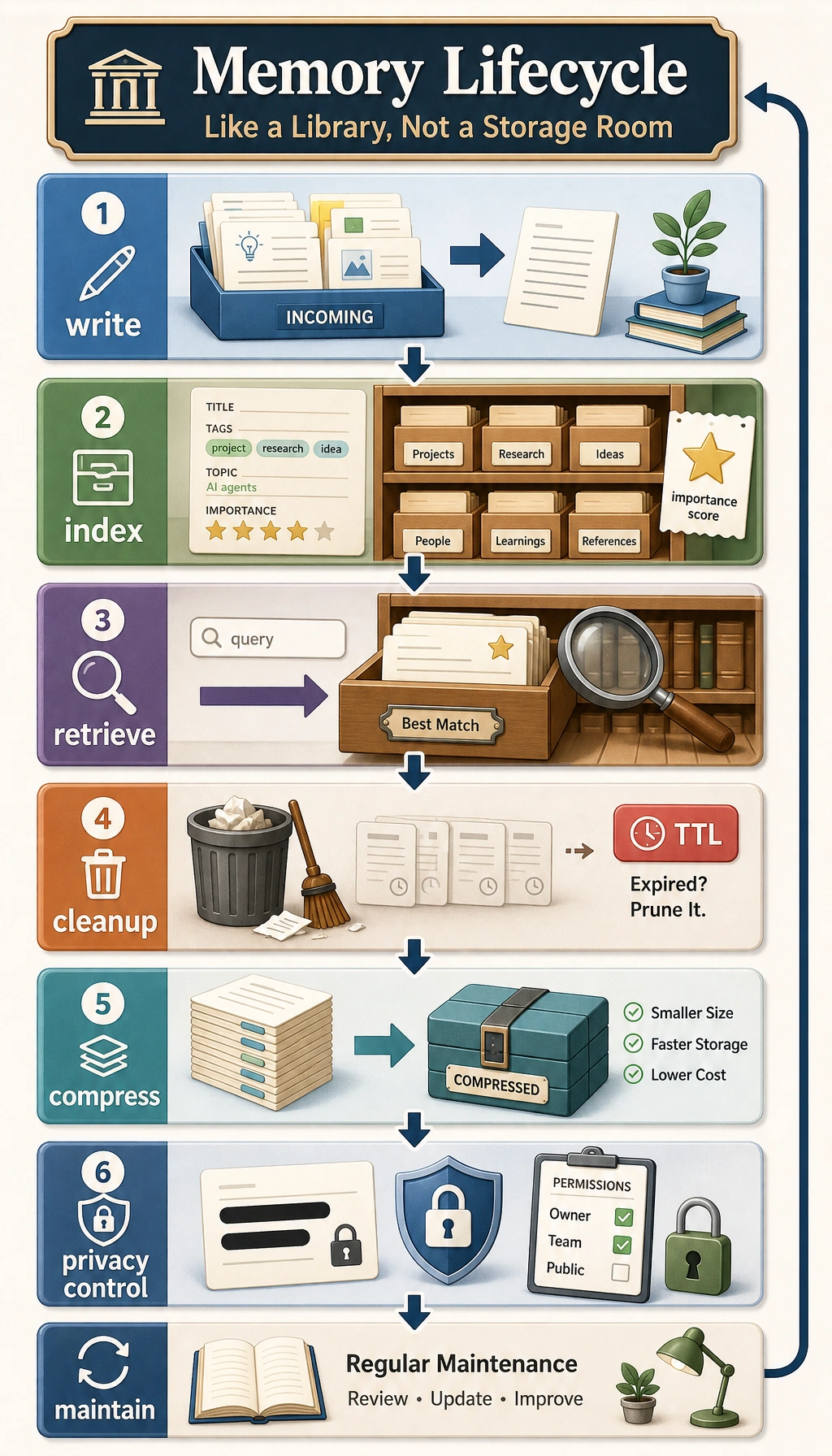
We can first split the memory pipeline into four parts
Section titled “We can first split the memory pipeline into four parts”write: whether to storeindex: how to organize after writingretrieve: how to rank during querieslifecycle: expiration, cleanup, compression
As long as these four parts are clear, the system is much easier to keep stable.
An analogy
Section titled “An analogy”A memory system is more like a library than a storage room.
- A storage room only cares about “put it in”
- A library must care about “cataloging, retrieval, removal, and archiving”
If an Agent needs to work for a long time, it must be closer to the latter.
Write Policy: What Information Is Worth Keeping in Long-Term Memory?
Section titled “Write Policy: What Information Is Worth Keeping in Long-Term Memory?”Not every message is worth writing
Section titled “Not every message is worth writing”For example, these two kinds of information are very different in value:
- “Hello, are you there?”
- “The user prefers concise answers, no more than three points”
The second one is more suitable for long-term retention, while the first one usually is not.
A practical write decision
Section titled “A practical write decision”You can start by filtering with three questions:
- Will this information be reused in the future?
- Is this information related to the user, the task, or the strategy?
- Is this information stable enough, rather than one-time noise?
Common types that can be written
Section titled “Common types that can be written”- User preferences
- Stable background information
- Key task conclusions
- Summaries of steps that have been proven reusable
Common types that are not recommended for direct long-term storage:
- Temporary intermediate logs
- Repeated small talk
- Speculative content that cannot be verified
Retrieval Policy: How Do We Find “Useful Memory” Again?
Section titled “Retrieval Policy: How Do We Find “Useful Memory” Again?”Retrieval is not just semantic similarity
Section titled “Retrieval is not just semantic similarity”Pure similarity sometimes misses important engineering signals, such as:
- Whether this memory is too old
- Whether the memory itself is highly important
- Whether it is related to the current user
A common ranking combination
Section titled “A common ranking combination”Retrieval scores can come from weighted multiple factors:
- Semantic or keyword relevance
- Importance score
- Freshness decay
- Source credibility
This is more stable than looking only at “does it look similar.”
Why decay matters
Section titled “Why decay matters”Some information becomes outdated. Without time decay, the system may keep using very old preferences or context in current decisions.
Lifecycle: Expiration, Cleanup, and Compression
Section titled “Lifecycle: Expiration, Cleanup, and Compression”TTL is not optional
Section titled “TTL is not optional”Some memories are naturally short-lived, such as:
- Temporary parameters for the current session
- One-time state flags
These kinds of information are best stored with a TTL.
Cleanup is not as simple as “deleting a batch on a schedule”
Section titled “Cleanup is not as simple as “deleting a batch on a schedule””A better approach is usually to combine:
- Expiration checks
- Low-value eviction
- Duplicate content merging
Compression makes the system sustainable over time
Section titled “Compression makes the system sustainable over time”When the number of records keeps growing, you can compress similar history into summaries, for example:
- Merge the latest 20 “user preference confirmations” into one stable preference record
This can significantly reduce retrieval noise and context pressure.
First Run a Runnable Minimal Memory Engine
Section titled “First Run a Runnable Minimal Memory Engine”The example below will demonstrate the full flow:
- Short-term message window
- Long-term memory writing (with importance and TTL)
- Query retrieval (relevance + importance + freshness)
- Expiration cleanup
from dataclasses import dataclassfrom collections import dequeimport math
@dataclassclass MemoryItem: memory_id: int text: str tags: list source: str importance: float created_step: int ttl_steps: int | None
class MemoryEngine: def __init__(self, short_window=4): self.short_messages = deque(maxlen=short_window) self.long_memories = [] self.step = 0 self._next_id = 1
def tick(self): self.step += 1
def add_short_message(self, role, content): self.short_messages.append({"role": role, "content": content, "step": self.step})
def write_long_memory(self, text, tags=None, source="dialogue", importance=0.5, ttl_steps=None): tags = tags or [] normalized = text.strip().lower()
# Minimal deduplication: do not write the exact same text twice for item in self.long_memories: if item.text.strip().lower() == normalized and self._is_alive(item): return item.memory_id
memory = MemoryItem( memory_id=self._next_id, text=text, tags=tags, source=source, importance=float(importance), created_step=self.step, ttl_steps=ttl_steps, ) self._next_id += 1 self.long_memories.append(memory) return memory.memory_id
def _is_alive(self, item): if item.ttl_steps is None: return True return (self.step - item.created_step) <= item.ttl_steps
def cleanup(self): self.long_memories = [item for item in self.long_memories if self._is_alive(item)]
def retrieve(self, query, top_k=3): query_tokens = set(query.lower().split()) scored = []
for item in self.long_memories: if not self._is_alive(item): continue
item_tokens = set(item.text.lower().split()) | set(tag.lower() for tag in item.tags) overlap = len(query_tokens & item_tokens)
age = self.step - item.created_step recency = math.exp(-age / 20) # newer items get higher scores
score = (0.55 * overlap) + (0.30 * item.importance) + (0.15 * recency) scored.append((item, round(score, 4)))
scored.sort(key=lambda x: x[1], reverse=True) return scored[:top_k]
engine = MemoryEngine(short_window=3)
engine.add_short_message("user", "I want to understand refund conditions")engine.write_long_memory( "User preference: answer as briefly as possible, no more than three points", tags=["preference", "style"], importance=0.95,)
engine.tick()engine.add_short_message("assistant", "Okay, I'll keep it brief")engine.write_long_memory( "Temporary debug flag: this round uses experimental prompt v2", tags=["debug"], importance=0.2, ttl_steps=1,)
engine.tick()engine.write_long_memory( "Key refund policy points: within 7 days and learning progress below 20%", tags=["refund", "policy"], importance=0.9,)
print("before cleanup:", [m.text for m in engine.long_memories])engine.tick()engine.cleanup()print("after cleanup :", [m.text for m in engine.long_memories])
results = engine.retrieve("Please answer the refund policy in a concise style", top_k=2)print("\nretrieval:")for item, score in results: print(item.memory_id, round(score, 4), item.text)Expected output:
before cleanup: ['User preference: answer as briefly as possible, no more than three points', 'Temporary debug flag: this round uses experimental prompt v2', 'Key refund policy points: within 7 days and learning progress below 20%']after cleanup : ['User preference: answer as briefly as possible, no more than three points', 'Key refund policy points: within 7 days and learning progress below 20%']
retrieval:1 1.5141 User preference: answer as briefly as possible, no more than three points3 1.5127 Key refund policy points: within 7 days and learning progress below 20%
The three most important things to learn from this code
Section titled “The three most important things to learn from this code”- Writing is not unconditional
importance,tags, and deduplication are used to control write quality - Retrieval is not pure similarity Relevance, importance, and freshness together determine ranking
- A lifecycle is necessary
ttl_stepsandcleanupprevent long-term growth from getting out of control
Why is it reasonable to clear the “debug flag”?
Section titled “Why is it reasonable to clear the “debug flag”?”Because it is temporary information and has ttl_steps=1.
If it is kept in later steps, it usually only pollutes retrieval results.
Why are “user preference” and “refund policy” retrieved first?
Section titled “Why are “user preference” and “refund policy” retrieved first?”Because the query terms trigger both:
concisematching the preference memoryrefund policymatching the policy memory
And both have higher importance and have not expired.
What Else Should Be Added in Engineering Practice?
Section titled “What Else Should Be Added in Engineering Practice?”Privacy and sensitive information handling
Section titled “Privacy and sensitive information handling”Before writing to long-term memory, you usually need to do:
- PII anonymization
- Compliance field filtering
Storage backends and indexing
Section titled “Storage backends and indexing”The example uses in-memory structures. Real systems often connect to:
- KV / document stores
- Vector databases
- Relational databases
Monitoring metrics
Section titled “Monitoring metrics”It is recommended to observe at least:
- Memory hit rate
- Expired cleanup rate
- Average number of retrieved items
- False retrieval rate
Without metrics, a memory system can easily become more and more of a black box with every change.
Most Common Misconceptions
Section titled “Most Common Misconceptions”Misconception 1: More memory means smarter
Section titled “Misconception 1: More memory means smarter”More memory can also mean more noise. The key is the proportion of effective memory, not the total amount.
Misconception 2: Only write, but never clean up
Section titled “Misconception 2: Only write, but never clean up”This leads to the accumulation of retrieval noise over time, and performance may actually get worse later.
Misconception 3: Only do semantic retrieval, but no policy layer
Section titled “Misconception 3: Only do semantic retrieval, but no policy layer”Memory engineering is always a combination of “retrieval + policy”, not something a single vector search can solve completely.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Memory Type
- short-term, long-term, episodic, or procedural
- Write Rule
- when memory is created or updated
- Retrieve Rule
- query, relevance, recency, and permission check
- Failure Check
- stale memory, privacy leak, contradiction, or over-retrieval
- Cleanup Action
- summarize, merge, expire, delete, or ask for confirmation
Summary
Section titled “Summary”The most important thing in this section is not to memorize a few more “memory type” terms, but to build an engineering judgment:
Whether a memory system is usable depends on whether the write, retrieval, and lifecycle policies form a closed loop, not on whether you have connected a storage component.
Once you get this loop running, the memory system can truly move from concept to stable capability.
Exercises
Section titled “Exercises”- Add a “source credibility” field to the example and include it in the retrieval score.
- Set
ttl_stepsshorter or longer and observe how the retrieval results change. - Design a memory item that “never expires but has low importance” and see whether it pollutes the results.
- How would you set different write policies for “user preferences” and “temporary debug information”?
Reference implementation and walkthrough
- Source credibility can become a score multiplier or tie-breaker, so explicit, recent, and trusted memories outrank weak inferred memories.
- A shorter
ttl_stepsremoves temporary memories sooner; a longer value keeps them available but increases the risk of stale retrieval. - A never-expiring low-importance memory should not dominate results. If it keeps appearing, the retrieval score is overweighting permanence.
- User preferences should require stronger evidence and longer TTL; temporary debug information should have low write priority, short TTL, and narrow retrieval scope.