12.2.5 Image Generation Fine-tuning

Learning objectives
Section titled “Learning objectives”- Understand why image generation models also need fine-tuning
- Distinguish the differences among DreamBooth, LoRA, and Textual Inversion
- Understand what each method is more like “changing”
- Build a very practical intuition for choosing among them
First, build a map
Section titled “First, build a map”Image generation fine-tuning is easier to understand if you think in terms of “Do you want to change a concept, a style, or a dedicated subject?”
flowchart LR A["Want to add a concept word"] --> B["Textual Inversion"] C["Want a low-cost plug-in adapter"] --> D["LoRA"] E["Want to strongly bind a dedicated subject"] --> F["DreamBooth"]So what this section really wants to solve is:
- Not which path is the most popular
- But what you are actually trying to fine-tune
Why is the base model still not enough?
Section titled “Why is the base model still not enough?”The base model can of course already generate many things. But real-world needs are usually more specific:
- Generate a specific dedicated character
- Generate a fixed brand style
- Keep a product consistent across different scenes
At this point, prompt engineering alone is often not stable enough.
So the essence of fine-tuning can be remembered as:
Letting the model converge toward a more specific visual target while keeping its original capabilities.
A beginner-friendly overall analogy
Section titled “A beginner-friendly overall analogy”You can think of image generation fine-tuning as:
- Doing “targeted style training” for an artist who already knows how to draw many things
The base model is like a generalist who can draw many subjects, but what you really want may be:
- A fixed IP character
- A certain brand look
- A dedicated style
At that point, you are not asking it to learn drawing from scratch, but to draw more consistently in a certain direction.
The three core routes in image generation fine-tuning
Section titled “The three core routes in image generation fine-tuning”Textual Inversion
Section titled “Textual Inversion”The lightest approach. It is more like:
Teaching the model a new trigger word / concept word.
More like:
Attaching a small, plug-in adapter to the base model.
DreamBooth
Section titled “DreamBooth”More like:
Strengthening the model’s memory of a specific dedicated subject.
If you first separate these three intuitions, many later terms will stop feeling mixed up.
Textual Inversion: why is it called the lightest?
Section titled “Textual Inversion: why is it called the lightest?”What is it actually learning?
Section titled “What is it actually learning?”It is not making large changes to the whole model, but more like:
- Learning a new token representation
You can think of it as:
Teaching the model to recognize a new “word.”
A minimal example
Section titled “A minimal example”textual_inversion = { "new_token": "<my_style>", "meaning": "a specific visual style", "learned_object": "token embedding"}
print(textual_inversion)Expected output:
{'new_token': '<my_style>', 'meaning': 'a specific visual style', 'learned_object': 'token embedding'}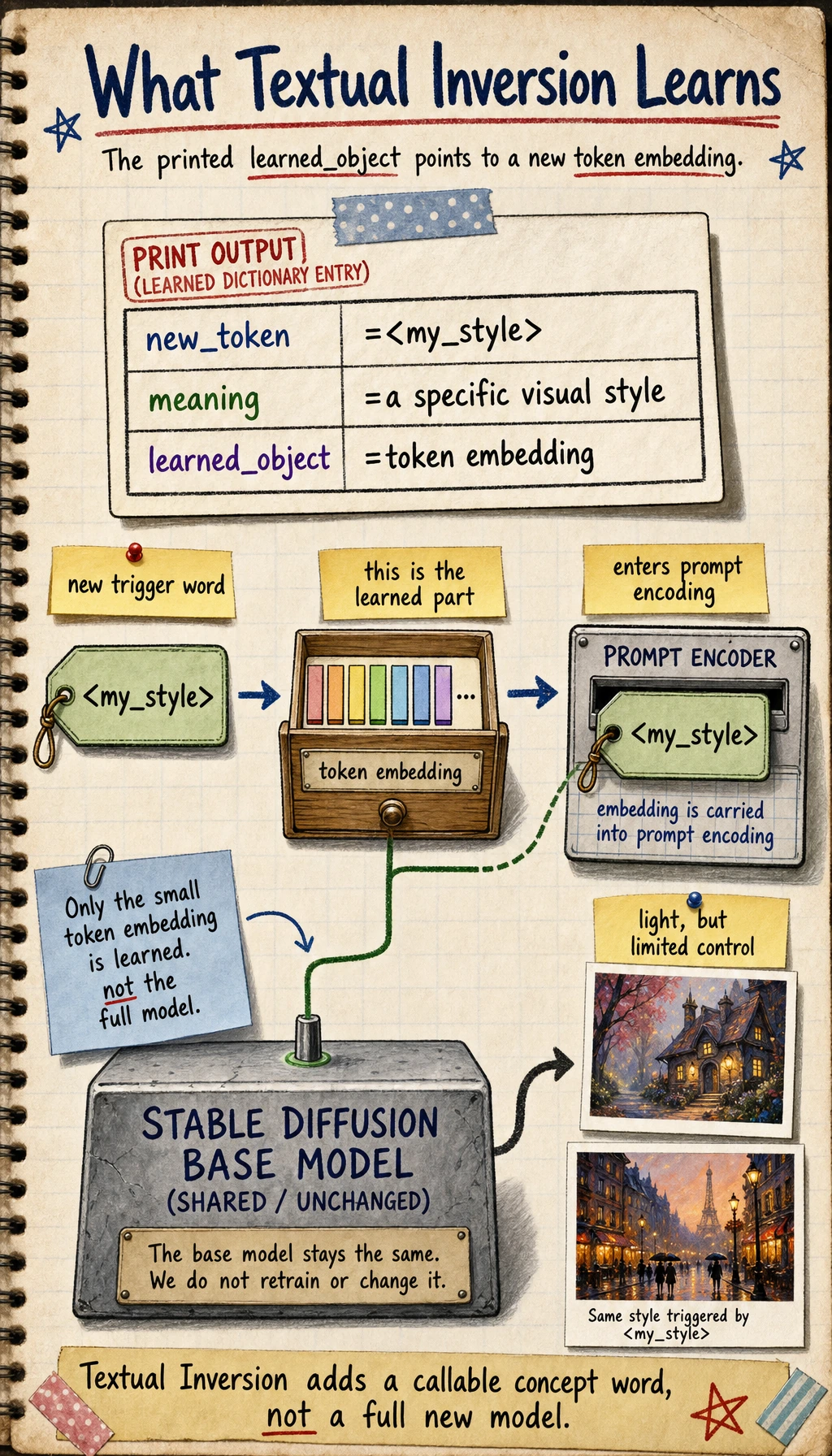
The key is learned_object: Textual Inversion mainly learns a new embedding for a token, so it is light but limited.
What is it good for?
Section titled “What is it good for?”- Style trigger words
- Some lightweight concept injection
Its advantages are:
- Light
- Fast
- Small scope of changes
But it is usually less powerful than heavier methods.
LoRA: why has it become the most common engineering choice?
Section titled “LoRA: why has it become the most common engineering choice?”Its core idea
Section titled “Its core idea”LoRA does not change the entire original model. Instead, it is:
Learning a low-cost incremental adapter.
This makes it very suitable for:
- Mounting multiple styles on one large base model
- Switching between different adapters
- Reducing training and storage costs
A simple example
Section titled “A simple example”base_model = "stable_diffusion_base"lora_adapter = { "target": "attention blocks / U-Net blocks", "size": "small", "effect": "adds style or subject control capability"}
print(base_model)print(lora_adapter)Expected output:
stable_diffusion_base{'target': 'attention blocks / U-Net blocks', 'size': 'small', 'effect': 'adds style or subject control capability'}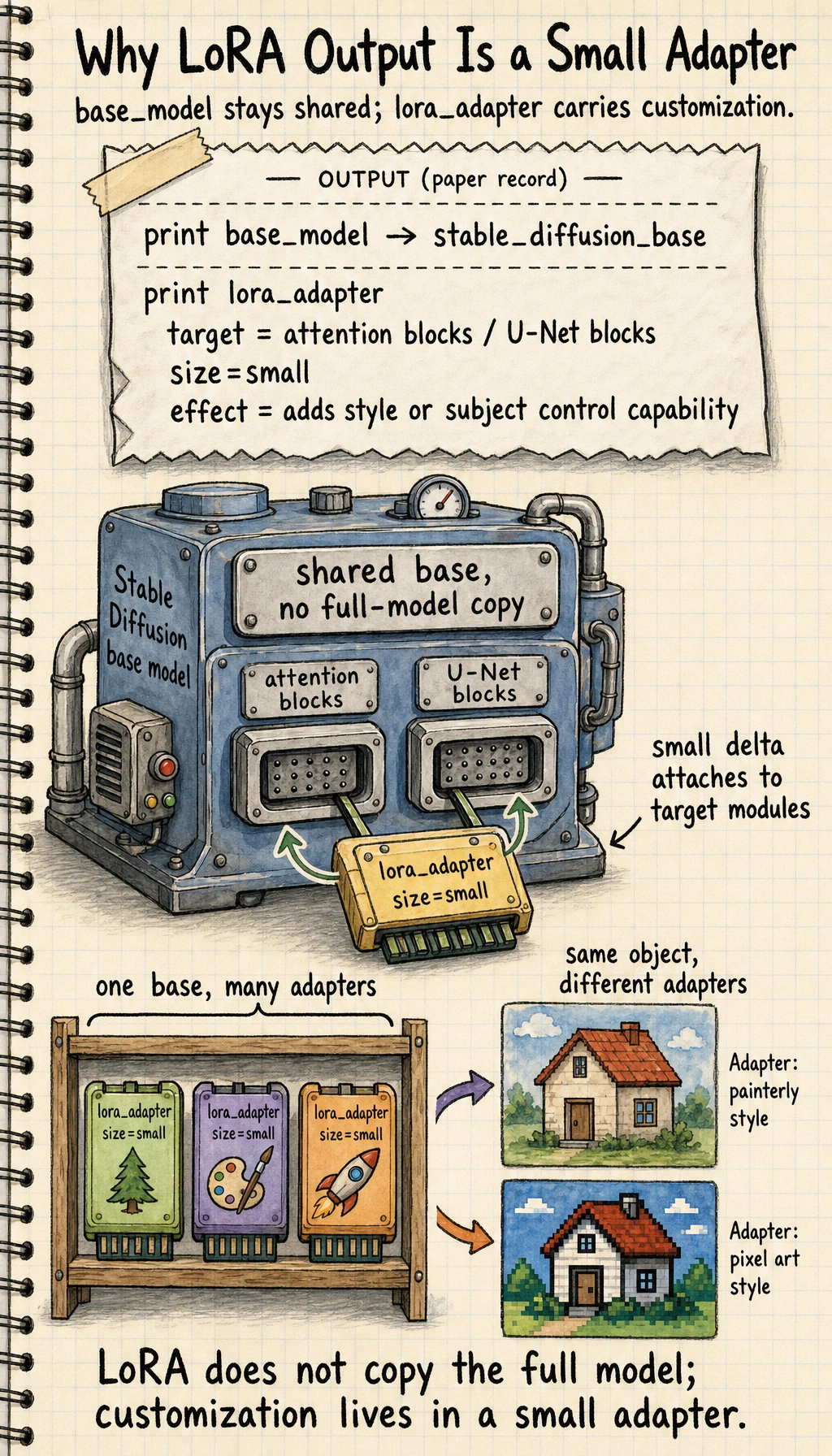
This is the engineering reason LoRA is popular: the base model stays shared, and the small adapter carries the customization.
Why is it especially practical in engineering?
Section titled “Why is it especially practical in engineering?”Because it is especially well-suited for:
- One base model
- Many different style or character adapters
In other words:
You do not need to store a full copy of the entire model for every customized version.
That is one of the main reasons LoRA became so popular.
DreamBooth: why is it more often used for “dedicated subjects”?
Section titled “DreamBooth: why is it more often used for “dedicated subjects”?”What problem is it solving?
Section titled “What problem is it solving?”DreamBooth is commonly used to:
- Teach the model a specific person
- Teach the model a specific object
- Teach the model a specific IP character
Why is it “stronger” than Textual Inversion?
Section titled “Why is it “stronger” than Textual Inversion?”Because it usually does more than learn just one word; it more deeply adapts the model to how this subject appears in image space.
What is the cost?
Section titled “What is the cost?”- Heavier
- More prone to overfitting
- More dependent on data quality
So you can roughly remember it like this:
- Textual Inversion: light
- LoRA: balanced
- DreamBooth: stronger but heavier
How do you choose? A very practical rule of thumb
Section titled “How do you choose? A very practical rule of thumb”If you want a lightweight style trigger word
Section titled “If you want a lightweight style trigger word”Prefer:
- Textual Inversion
If you want low-cost, plug-and-play, and maintainable
Section titled “If you want low-cost, plug-and-play, and maintainable”Prefer:
- LoRA
If you want to strongly bind a specific subject
Section titled “If you want to strongly bind a specific subject”Prefer:
- DreamBooth
So the really useful question is not:
“Which method is the strongest?”
But:
“What am I actually fine-tuning: a word, a style, or a subject?”
A selection table that is very beginner-friendly
Section titled “A selection table that is very beginner-friendly”| Your goal | Safer first choice |
|---|---|
| Add a trigger word or a lightweight concept | Textual Inversion |
| Maintain many style versions at low cost | LoRA |
| Strongly bind a specific person / object / IP | DreamBooth |
This table is helpful for beginners because it brings method selection back to “What is the actual goal?”
Why is evaluating image generation fine-tuning especially difficult?
Section titled “Why is evaluating image generation fine-tuning especially difficult?”Because this is not like a classification task, where you can look at one accuracy number.
You usually also need to check:
- Whether the generated result matches the target style
- Whether the subject stays consistent
- Whether the model overfits the training images
- Whether it remains stable under different prompts
In other words:
Evaluation is more like judging visual and creative quality than judging a single metric.
A beginner-friendly evaluation table
Section titled “A beginner-friendly evaluation table”| Evaluation dimension | What should you ask first? |
|---|---|
| Style consistency | Does it look like the target style? |
| Subject consistency | Is it the same person / object? |
| Generalization stability | Is it still stable after changing the prompt? |
| Overfitting | Does it just repeat the training images? |
This table is helpful for beginners because it breaks “evaluation is subjective” into several more observable questions.
A very practical summary table
Section titled “A very practical summary table”| Method | More like | Advantage | Cost |
|---|---|---|---|
| Textual Inversion | Learning a new word | Lightweight, fast | Limited control ability |
| LoRA | Installing a small adapter | Low cost, easy to switch | Still requires understanding target modules |
| DreamBooth | Learning a dedicated subject | Stronger subject control | Heavier, easier to overfit |
This table is not for memorizing mechanically, but for building a judgment habit.
The most common misconceptions
Section titled “The most common misconceptions”Starting with full fine-tuning right away
Section titled “Starting with full fine-tuning right away”In many cases, that is completely unnecessary.
Not being clear about what exactly you want to fine-tune
Section titled “Not being clear about what exactly you want to fine-tune”Is it style? Subject? Trigger word? If this is unclear, it is very easy to choose the wrong method.
Only looking at a few successful images
Section titled “Only looking at a few successful images”What really matters is:
- Is it stable under multiple prompts?
- Does it still look right across multiple samplings?
If you turn this into a project or solution, what is most worth showing?
Section titled “If you turn this into a project or solution, what is most worth showing?”What is most worth showing is usually not:
- “I fine-tuned SD”
Instead, show:
- What your goal is: concept, style, or subject
- Why you chose this fine-tuning route
- Which dimensions you used for evaluation
- Under which prompts the generation is stable, and under which prompts it is not
That way, others can more easily see:
- You understand method selection and evaluation
- You did not just run a training script once
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Prompt Record
- prompt, negative requirements, reference, seed/model, and version number
- Candidate Outputs
- generated or simulated results with selection reason
- Technical Note
- diffusion step, latent, cross-attention, LoRA, or application mode
- Failure Check
- prompt drift, style mismatch, artifact, copyright, portrait, or review failure
- Expected Output
- selected image/version record plus rejected-candidate notes
Summary
Section titled “Summary”The most important thing in this section is not memorizing the names DreamBooth, LoRA, and Textual Inversion, but understanding:
The core of image generation fine-tuning is using different costs to gain more stable control over style, subjects, or concepts.
Once you build that judgment, it will be much easier to understand specific training workflows later.
Exercises
Section titled “Exercises”- Explain in your own words what Textual Inversion, LoRA, and DreamBooth are more like “changing.”
- Think about this: if you only want to add a style trigger word to the model, why might you not need DreamBooth?
- If you need to maintain many style versions over the long term, why is LoRA especially valuable from an engineering perspective?
- Why is evaluation in image generation fine-tuning more dependent on human perceptual judgment than text classification?
Solution approach and explanation
- Textual Inversion is more like adding a new token embedding, LoRA is more like adding a small detachable skill patch to model layers, and DreamBooth is more like teaching the model a specific subject or identity with more direct examples.
- If you only need a style trigger word, Textual Inversion or LoRA may be enough because you are not trying to deeply rewrite the model’s subject knowledge.
- LoRA is valuable operationally because style versions can be stored, combined, swapped, reviewed, and rolled back as small files instead of maintaining many full model copies.
- Image generation quality includes style fidelity, composition, identity preservation, artifacts, and user preference. Those judgments are visual and subjective, so automatic metrics alone are weaker than in text classification.