7.8.4 Hands-on: Full Chapter 7 Workshop
This workshop is the practical thread for the whole chapter. If you feel the chapter has many concepts, run this page once from top to bottom. You will not train a large model here. Instead, you will build the smallest repeatable workflow that connects tokens, request payloads, prompt versions, structured output validation, evaluation, the Prompt/RAG/fine-tuning decision, and a small evidence pack you can review afterward.
What you will build
Section titled “What you will build”By the end, you will have one runnable Python file that can:
- Turn learner requests into simple tokens, token ids, and a tiny vector trace.
- Compare three prompt versions on fixed test cases.
- Validate whether model-like output is real JSON with required fields.
- Decide whether a task should start with Prompt, structured output, RAG, or a fine-tuning plan.
- Save token traces, prompt evaluation results, route decisions, failure cases, and a README into one local evidence folder.
- Explain the output like an engineer: what failed, why it failed, and what you would change next.
The code intentionally uses only the Python standard library. That keeps the first run friendly for beginners and also makes the engineering idea clear before you connect a real model API.
Visual checkpoint: the whole route
Section titled “Visual checkpoint: the whole route”Before touching code, place these chapter diagrams in order. They are not decoration; they are the map for the workshop.
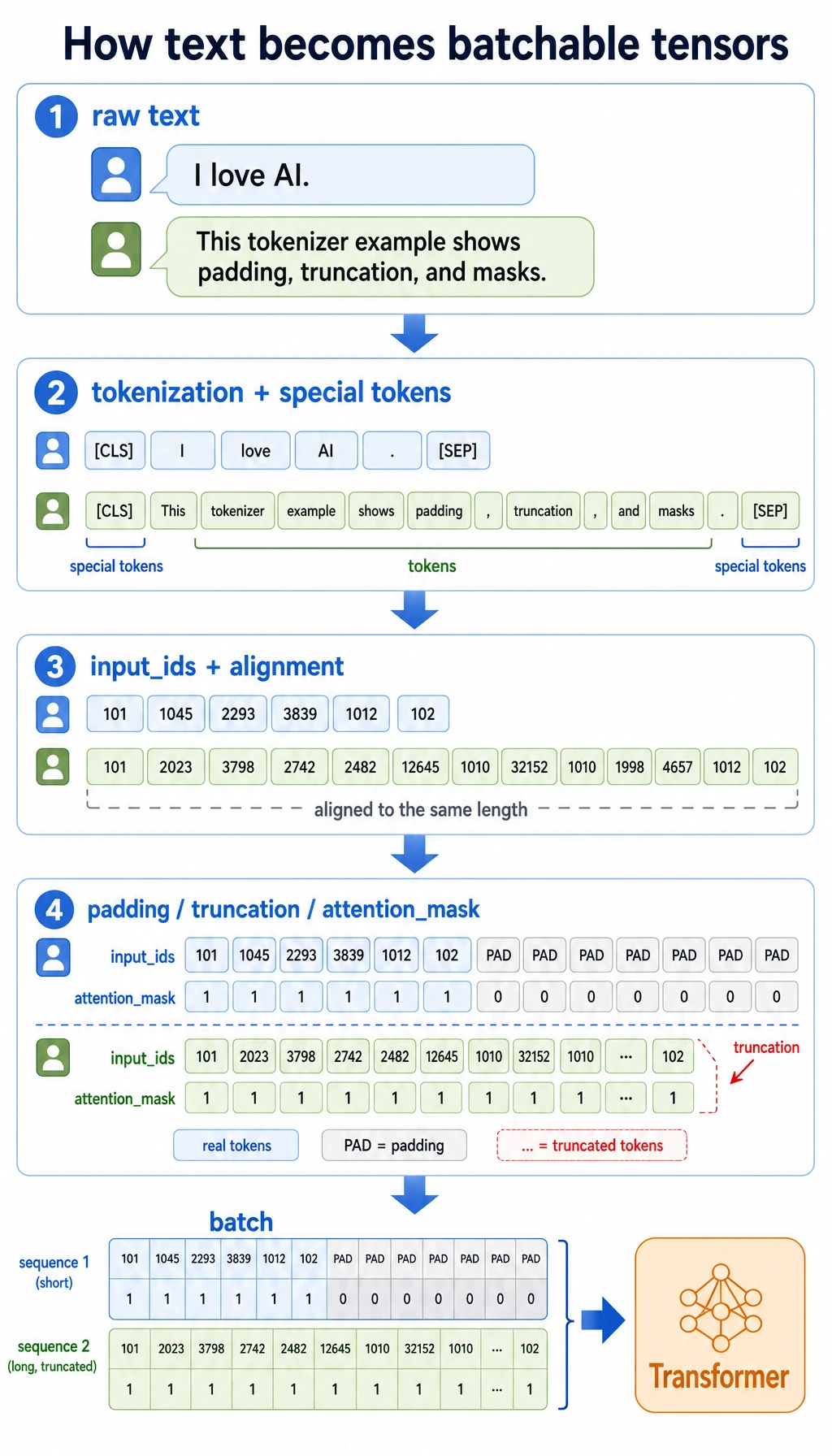
First, text must become tokens and ids before a model can process it.

Then, a model call is a request payload, not just a sentence typed into a chat box.
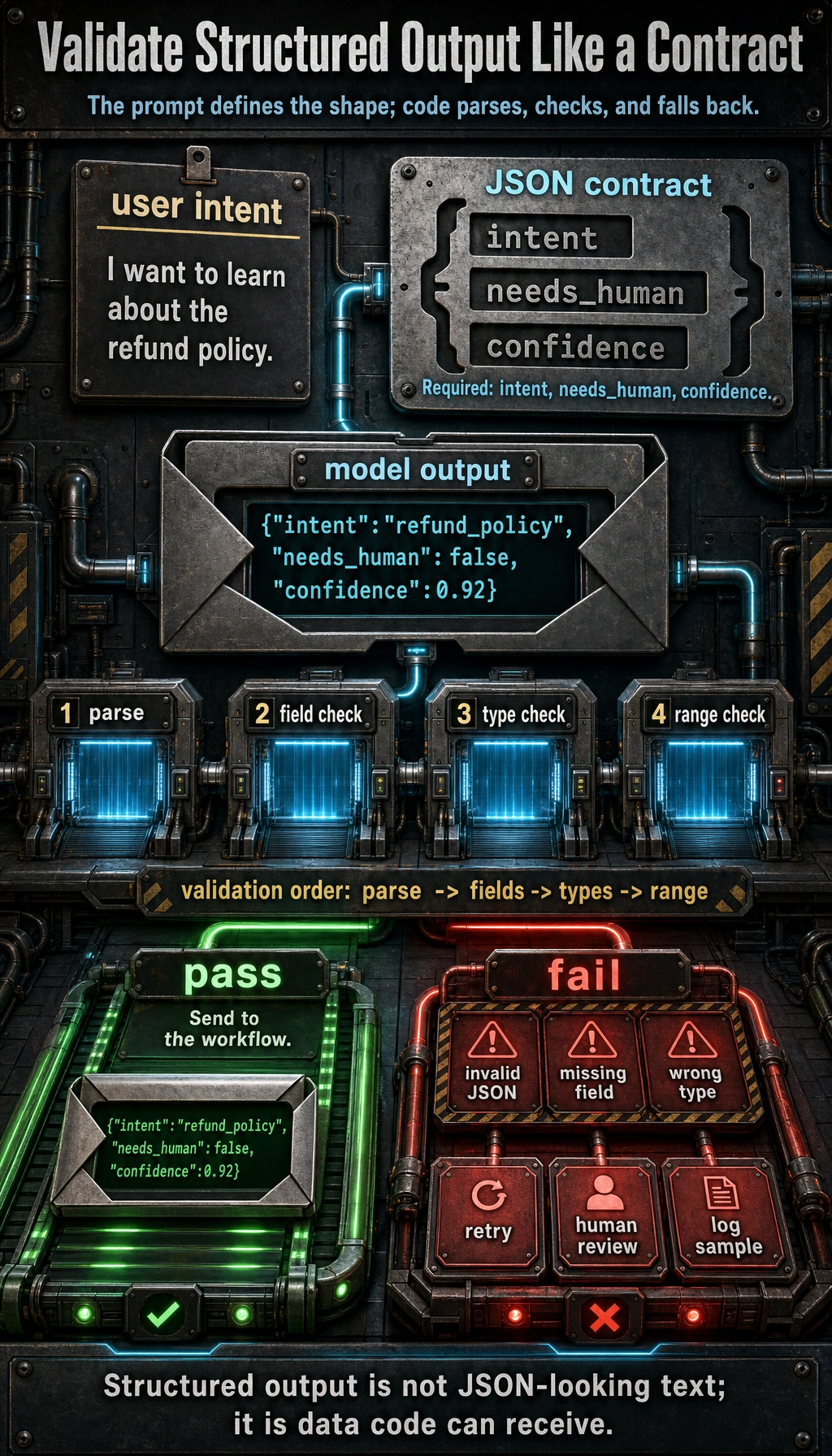
Next, production code must parse and validate the model output.
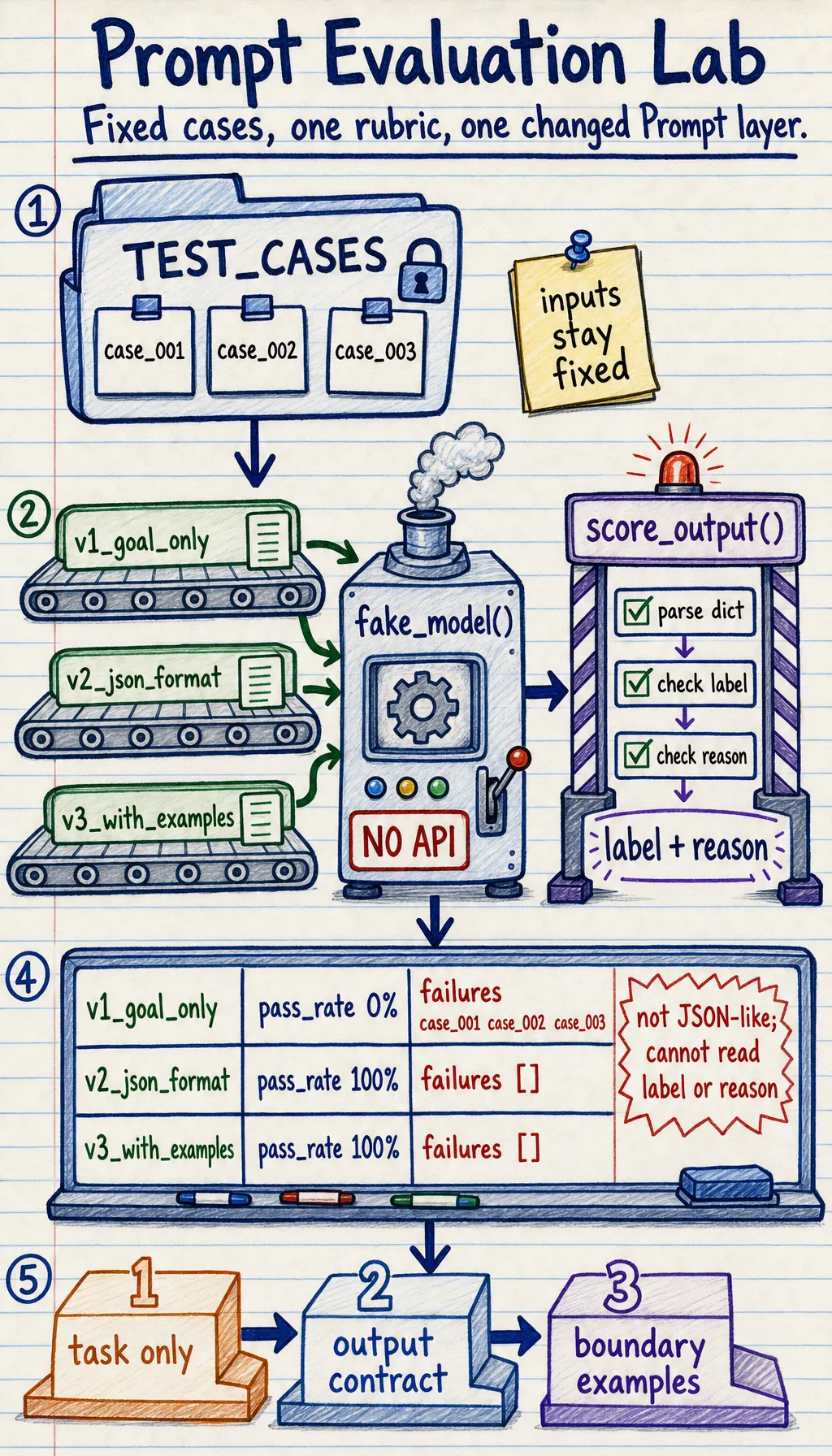
After that, prompt changes should be tested with fixed cases instead of judged by feeling.

Finally, do not jump to fine-tuning. First decide what kind of problem you actually have.
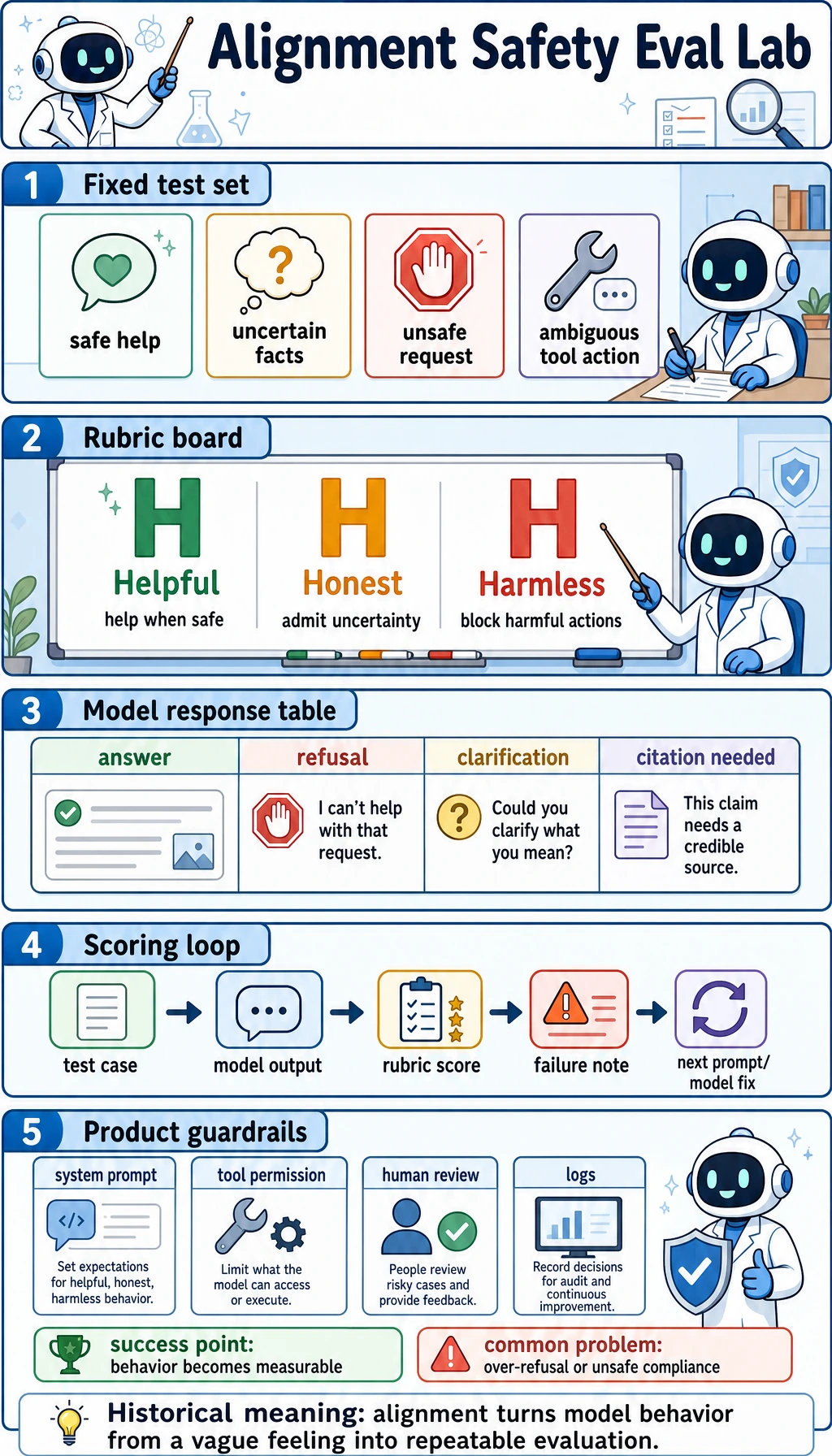
For risky tasks, add behavior evaluation and human review boundaries.
Now use these workshop-specific diagrams as your running checklist.
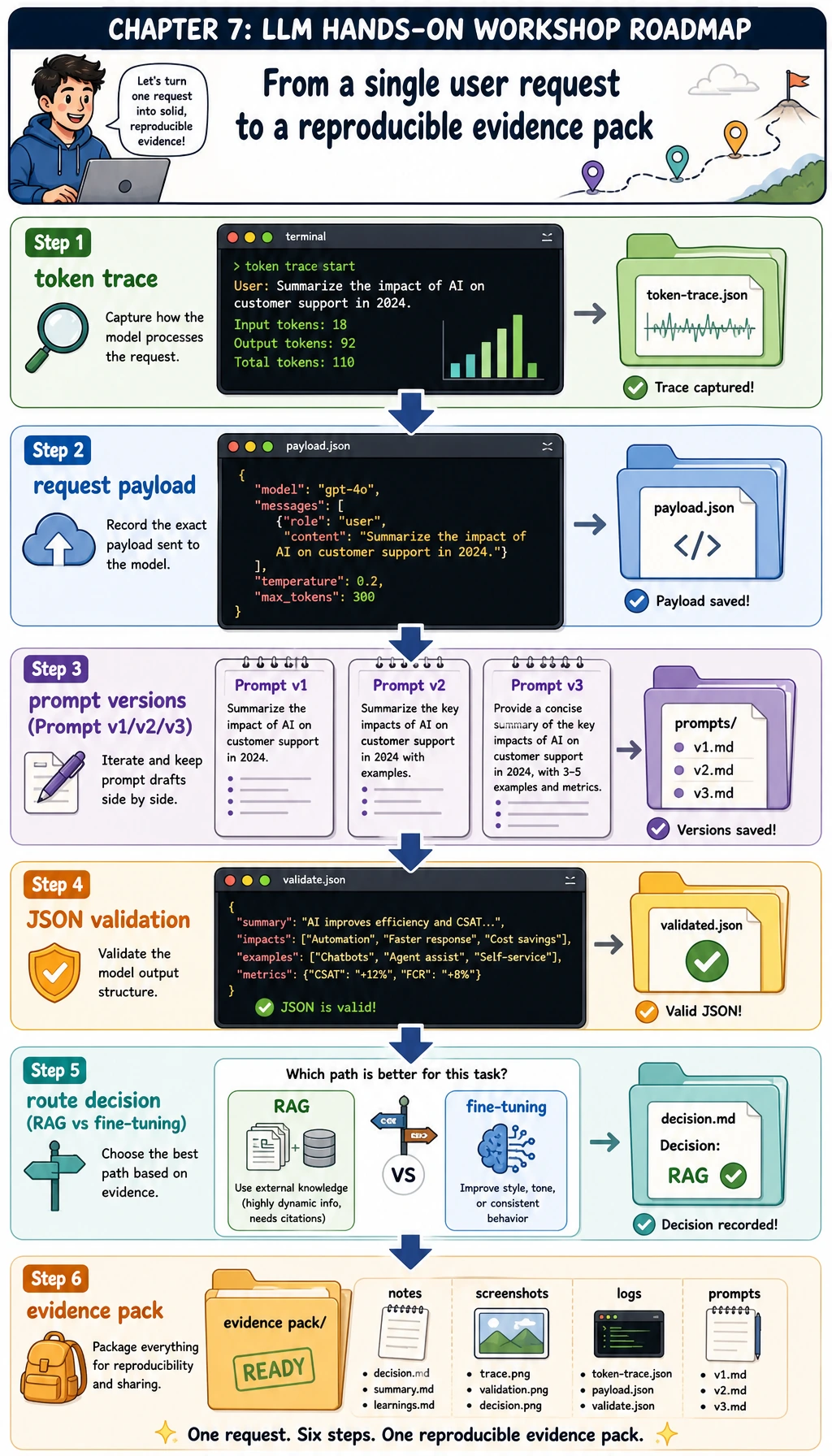
This is the route you will follow in the file: tokens, payloads, prompt versions, validation, route choice, and evidence.
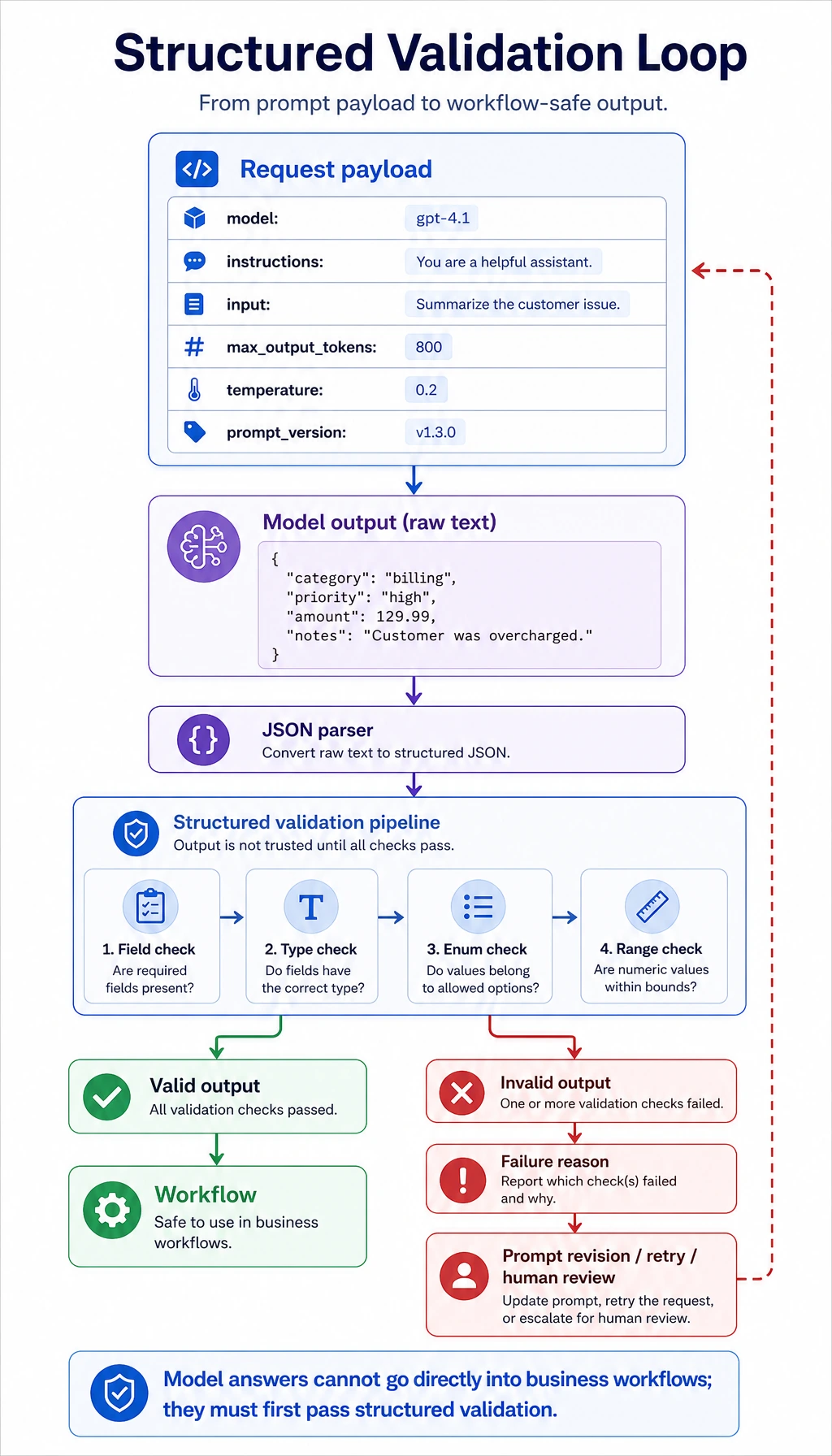
Every model-like answer must pass through a parser and field/type checks before the program trusts it.

When the script runs, it first builds traces, then evaluates prompts, then chooses solution routes, then saves files.
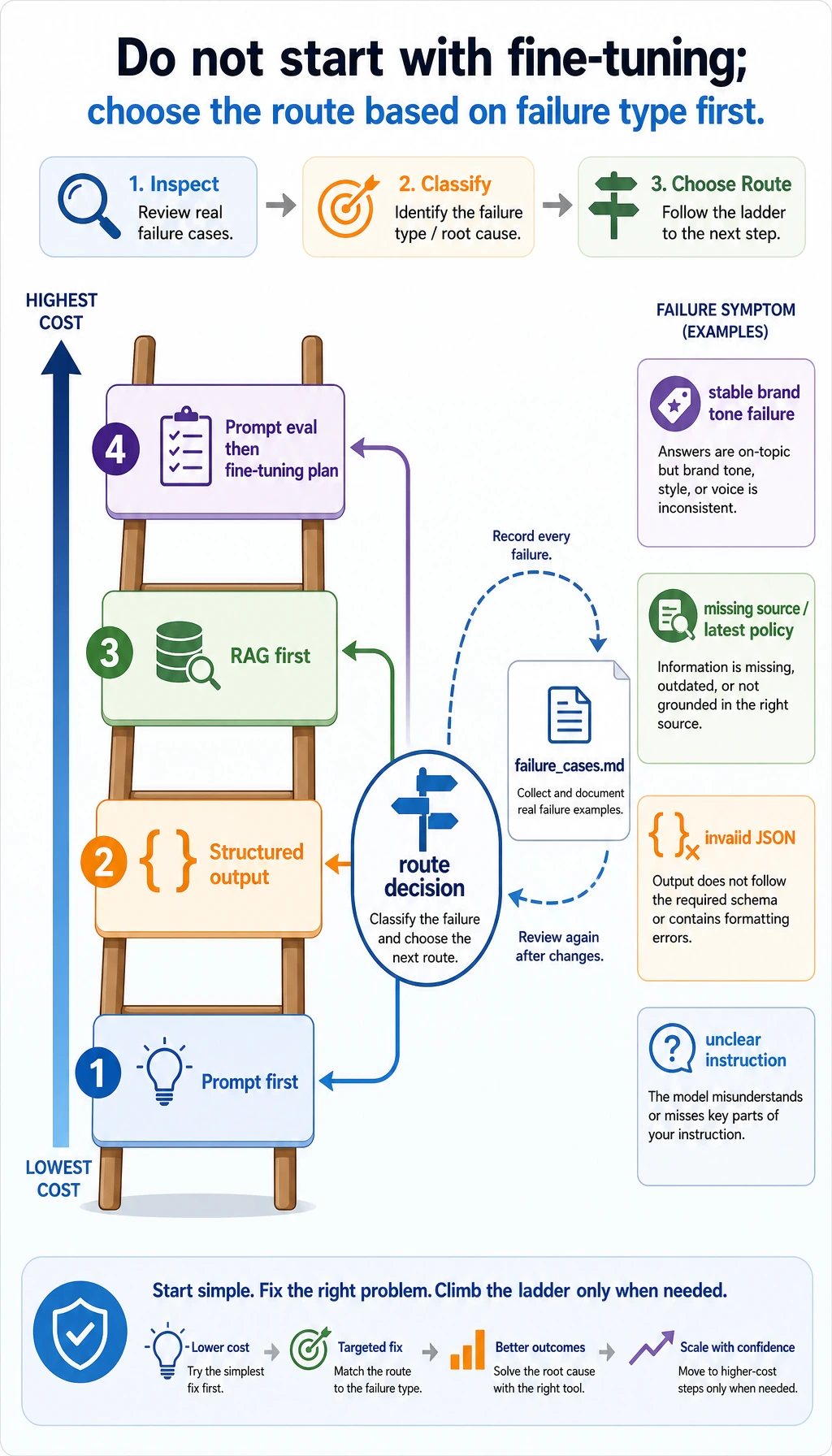
Do not jump to fine-tuning. Look at the failure type first and choose the cheapest reliable route.
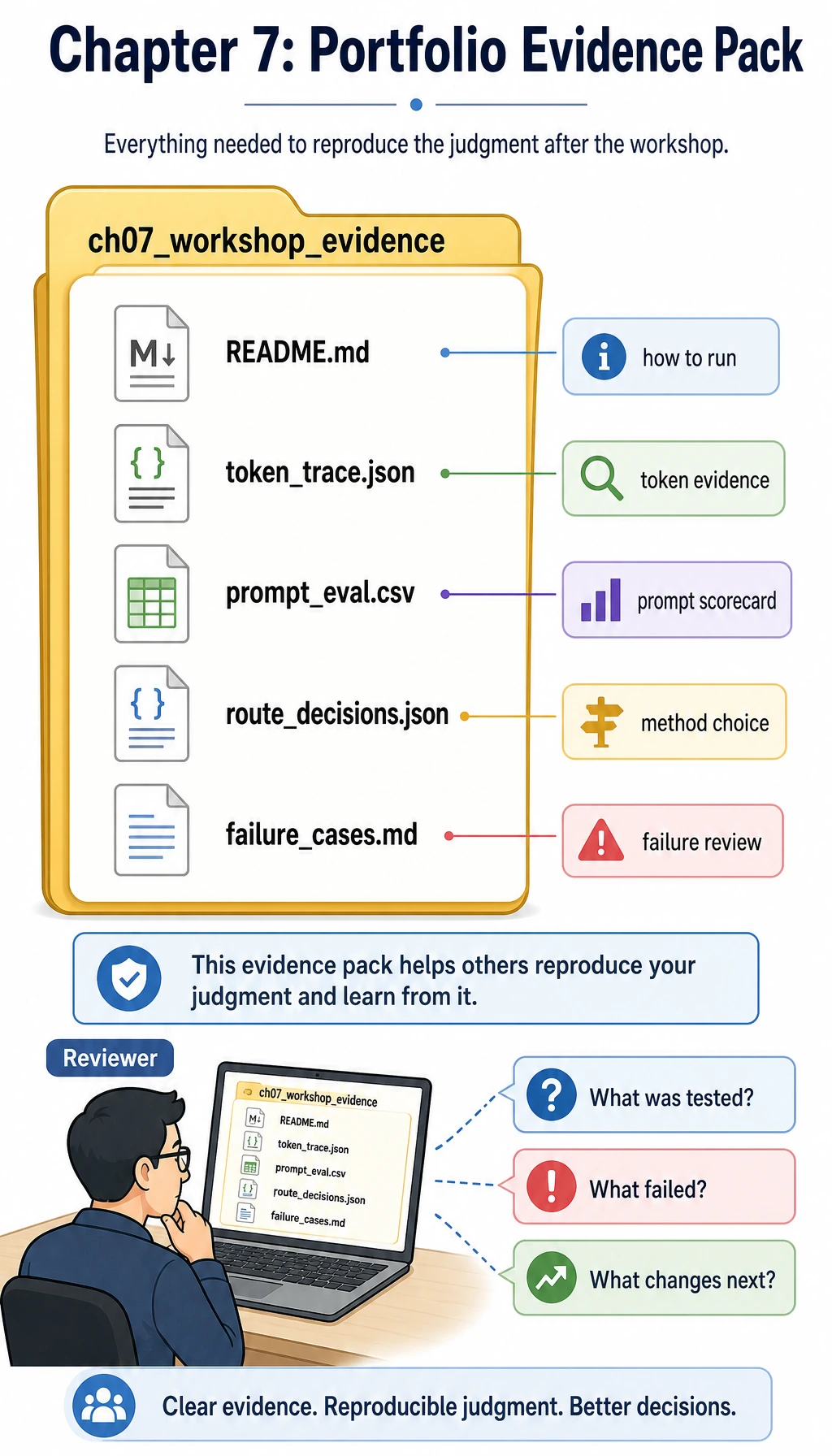
The final folder is part of the lesson: it makes the run reproducible and reviewable.
Create the project folder
Section titled “Create the project folder”Create a small local folder for this workshop:
mkdir ch07_hands_oncd ch07_hands_onThen create a file named llm_stage_workshop.py.
After you run it, the script will also create a folder named ch07_workshop_evidence. If the folder already exists, the files inside it will be overwritten with the newest run.
Paste and run the workshop code
Section titled “Paste and run the workshop code”Save the following code into llm_stage_workshop.py:
import csvimport jsonimport mathimport hashlibfrom pathlib import Path
SAMPLES = [ { "id": "case_1", "user_input": "I understand tokens but not attention. Give me a short study plan.", "expected_intent": "learning_plan", }, { "id": "case_2", "user_input": "Convert this note into JSON fields: topic=LoRA, risk=overfitting.", "expected_intent": "structured_output", }, { "id": "case_3", "user_input": "Our assistant keeps using the wrong brand tone. Should we fine-tune?", "expected_intent": "solution_choice", },]
INTENTS = {"learning_plan", "structured_output", "solution_choice"}EVIDENCE_DIR = Path("ch07_workshop_evidence")
def simple_tokenize(text): cleaned = "".join(ch.lower() if ch.isalnum() else " " for ch in text) return [token for token in cleaned.split() if token]
def stable_token_id(token): digest = hashlib.sha1(token.encode("utf-8")).hexdigest() return int(digest[:6], 16) % 10000
def tiny_embedding(tokens, width=6): vector = [0.0] * width for token in tokens: vector[stable_token_id(token) % width] += 1.0 norm = math.sqrt(sum(value * value for value in vector)) or 1.0 return [round(value / norm, 3) for value in vector]
def infer_intent(text): lowered = text.lower() if "json" in lowered or "field" in lowered or "schema" in lowered: return "structured_output" if "fine-tune" in lowered or "brand tone" in lowered or "rag" in lowered: return "solution_choice" return "learning_plan"
def build_payload(case, prompt_version): base = { "model": "gpt-5.5", "input": case["user_input"], "max_output_tokens": 180, "temperature": 0.2, "prompt_version": prompt_version, } if prompt_version == "v1_goal_only": base["instructions"] = "Help the learner." elif prompt_version == "v2_json_contract": base["instructions"] = ( "Classify the learner request. Return JSON with id, intent, action, " "confidence, and needs_human_review." ) else: base["instructions"] = ( "Classify the learner request. Return JSON only. Allowed intent values: " "learning_plan, structured_output, solution_choice. confidence must be a " "number from 0 to 1. needs_human_review must be true only when the request " "asks for unsafe, legal, medical, or production deployment decisions." ) return base
def fake_model(payload, case): intent = infer_intent(payload["input"]) if payload["prompt_version"] == "v1_goal_only": return "Here is a helpful answer, but it is not machine-readable." if payload["prompt_version"] == "v2_json_contract" and case["id"] == "case_3": return json.dumps({"id": case["id"], "intent": "fine_tune", "action": "try fine-tuning"}) action_by_intent = { "learning_plan": "Start with tokens, then attention, then run the LLM call workbench.", "structured_output": "Define the JSON schema first, then validate every model output.", "solution_choice": "Run prompt evaluation first; consider fine-tuning only after stable failures repeat.", } return json.dumps( { "id": case["id"], "intent": intent, "action": action_by_intent[intent], "confidence": 0.86, "needs_human_review": False, }, ensure_ascii=False, )
def validate_output(raw): try: data = json.loads(raw) except json.JSONDecodeError as exc: return False, f"invalid_json: {exc.msg}", None required = ["id", "intent", "action", "confidence", "needs_human_review"] missing = [field for field in required if field not in data] if missing: return False, f"missing_fields: {missing}", data if data["intent"] not in INTENTS: return False, f"bad_intent: {data['intent']}", data if not isinstance(data["confidence"], (int, float)): return False, "confidence_not_number", data if not 0 <= data["confidence"] <= 1: return False, "confidence_out_of_range", data if not isinstance(data["needs_human_review"], bool): return False, "needs_human_review_not_boolean", data return True, "ok", data
def solution_route(text): lowered = text.lower() if "latest" in lowered or "source" in lowered or "policy" in lowered: return "RAG first" if "brand tone" in lowered or "keeps using" in lowered: return "Prompt eval first, then fine-tuning plan" if "json" in lowered or "field" in lowered: return "Structured output" return "Prompt first"
def build_token_trace(): rows = [] for case in SAMPLES: tokens = simple_tokenize(case["user_input"]) rows.append( { "case_id": case["id"], "tokens": tokens, "token_ids": [stable_token_id(token) for token in tokens], "tiny_embedding": tiny_embedding(tokens), } ) return rows
def evaluate_prompt_versions(): rows = [] for version in ["v1_goal_only", "v2_json_contract", "v3_json_with_boundary"]: for case in SAMPLES: payload = build_payload(case, version) raw = fake_model(payload, case) ok, reason, data = validate_output(raw) correct_intent = ok and data["intent"] == case["expected_intent"] if ok and not correct_intent: reason = f"wrong_intent: {data['intent']} != {case['expected_intent']}" rows.append( { "prompt_version": version, "case_id": case["id"], "passed": correct_intent, "reason": "ok" if correct_intent else reason, "raw_output": raw, } ) return rows
def build_route_decisions(): return [ { "case_id": case["id"], "user_input": case["user_input"], "first_route": solution_route(case["user_input"]), } for case in SAMPLES ]
def save_evidence(token_rows, eval_rows, route_rows): EVIDENCE_DIR.mkdir(exist_ok=True) token_path = EVIDENCE_DIR / "token_trace.json" eval_path = EVIDENCE_DIR / "prompt_eval.csv" route_path = EVIDENCE_DIR / "route_decisions.json" failure_path = EVIDENCE_DIR / "failure_cases.md" readme_path = EVIDENCE_DIR / "README.md"
token_path.write_text(json.dumps(token_rows, indent=2, ensure_ascii=False), encoding="utf-8") route_path.write_text(json.dumps(route_rows, indent=2, ensure_ascii=False), encoding="utf-8")
with eval_path.open("w", newline="", encoding="utf-8") as file: writer = csv.DictWriter(file, fieldnames=["prompt_version", "case_id", "passed", "reason", "raw_output"]) writer.writeheader() writer.writerows(eval_rows)
failures = [row for row in eval_rows if not row["passed"]] failure_lines = ["# Failure Cases", ""] for row in failures: failure_lines.append(f"- {row['prompt_version']} / {row['case_id']}: {row['reason']}") failure_path.write_text("\n".join(failure_lines) + "\n", encoding="utf-8")
passed_v3 = sum(row["passed"] for row in eval_rows if row["prompt_version"] == "v3_json_with_boundary") readme_path.write_text( "# Chapter 7 LLM Workshop Evidence\n\n" "Run command: `python llm_stage_workshop.py`\n\n" f"Best prompt version: v3_json_with_boundary ({passed_v3}/{len(SAMPLES)} passed)\n\n" "Review `failure_cases.md` before deciding whether to change Prompt, add RAG, or plan fine-tuning.\n", encoding="utf-8", ) return [token_path, eval_path, route_path, failure_path, readme_path]
def main(): token_rows = build_token_trace() print("STEP 1: Token and vector trace") for row in token_rows: print( f"{row['case_id']} tokens={row['tokens'][:8]} " f"ids={row['token_ids'][:8]} vector={row['tiny_embedding']}" )
eval_rows = evaluate_prompt_versions() print("\nSTEP 2: Prompt version evaluation") for version in ["v1_goal_only", "v2_json_contract", "v3_json_with_boundary"]: version_rows = [row for row in eval_rows if row["prompt_version"] == version] passed = sum(row["passed"] for row in version_rows) failures = [f"{row['case_id']}:{row['reason']}" for row in version_rows if not row["passed"]] print(f"{version}: {passed}/{len(version_rows)} passed; failures={failures or ['none']}")
route_rows = build_route_decisions() print("\nSTEP 3: Solution route check") for row in route_rows: print(f"{row['case_id']} -> {row['first_route']}")
saved_files = save_evidence(token_rows, eval_rows, route_rows) print("\nSTEP 4: Evidence files") for path in saved_files: print(path.as_posix())
if __name__ == "__main__": main()Run it:
python llm_stage_workshop.pyExpected output
Section titled “Expected output”You should see output close to this:
STEP 1: Token and vector tracecase_1 tokens=['i', 'understand', 'tokens', 'but', 'not', 'attention', 'give', 'me'] ids=[3860, 5684, 9523, 2631, 3109, 1613, 4738, 9496] vector=[0.0, 0.324, 0.324, 0.162, 0.811, 0.324]case_2 tokens=['convert', 'this', 'note', 'into', 'json', 'fields', 'topic', 'lora'] ids=[9914, 5551, 4760, 3544, 3358, 1778, 2081, 3008] vector=[0.0, 0.189, 0.756, 0.189, 0.567, 0.189]case_3 tokens=['our', 'assistant', 'keeps', 'using', 'the', 'wrong', 'brand', 'tone'] ids=[8696, 9265, 8706, 6757, 7679, 4122, 2342, 7190] vector=[0.343, 0.686, 0.514, 0.0, 0.171, 0.343]
STEP 2: Prompt version evaluationv1_goal_only: 0/3 passed; failures=['case_1:invalid_json: Expecting value', 'case_2:invalid_json: Expecting value', 'case_3:invalid_json: Expecting value']v2_json_contract: 2/3 passed; failures=["case_3:missing_fields: ['confidence', 'needs_human_review']"]v3_json_with_boundary: 3/3 passed; failures=['none']
STEP 3: Solution route checkcase_1 -> Prompt firstcase_2 -> Structured outputcase_3 -> Prompt eval first, then fine-tuning plan
STEP 4: Evidence filesch07_workshop_evidence/token_trace.jsonch07_workshop_evidence/prompt_eval.csvch07_workshop_evidence/route_decisions.jsonch07_workshop_evidence/failure_cases.mdch07_workshop_evidence/README.md
What each step means
Section titled “What each step means”| Output area | What to observe | Chapter concept |
|---|---|---|
tokens and ids | Text is split into smaller units and mapped to numbers | Tokenizer and token ids |
vector | A tiny teaching vector shows that text can become numeric features | Embedding intuition |
v1_goal_only | The answer may be helpful, but the program cannot parse it | Vague prompt and unstable interface |
v2_json_contract | JSON helps, but missing fields and wrong enum values still break the workflow | Structured output validation |
v3_json_with_boundary | Adding allowed values, types, and review rules makes the result testable | Prompt iteration and schema design |
solution_route | Different problems need different first moves | Prompt, RAG, structured output, fine-tuning boundaries |
ch07_workshop_evidence | The run is saved as files that can be inspected, compared, and shared | Reproducible project evidence |
Beginner troubleshooting
Section titled “Beginner troubleshooting”| Symptom | Likely cause | Fix |
|---|---|---|
python: command not found | Your system uses python3 instead of python | Run python3 llm_stage_workshop.py |
| Output differs in spacing | Python may print lists with small formatting differences | Focus on pass counts and failure reasons |
invalid_json appears | The simulated model returned natural language, not JSON | This is intentional for v1_goal_only |
missing_fields appears | The output contract was not strict enough | Compare v2_json_contract with v3_json_with_boundary |
| Evidence files are not created | You ran the script in a read-only folder or stopped before STEP 4 | Run it in a normal project folder and check that STEP 4 printed file paths |
| You want a real model call | The workshop is offline by design | First finish this page, then use the LLM Call Workbench optional API section |
Optional: replace the fake model later
Section titled “Optional: replace the fake model later”After the offline workflow is clear, you can replace fake_model() with a real model call. For current OpenAI text-generation work, prefer the Responses API and structured outputs instead of copying old chat-completion examples.
A real structured-output call can look like this:
import osfrom pydantic import BaseModelfrom openai import OpenAI
class RouteResult(BaseModel): intent: str action: str confidence: float needs_human_review: bool
client = OpenAI()
response = client.responses.parse( model=os.getenv("OPENAI_MODEL", "gpt-5.5"), input=[ { "role": "system", "content": ( "Classify the learner request. Return a practical next action. " "Use needs_human_review only for unsafe, legal, medical, or production decisions." ), }, { "role": "user", "content": "Our assistant keeps using the wrong brand tone. Should we fine-tune?", }, ], text_format=RouteResult,)
print(response.output_parsed.model_dump())Run the real version only after installing dependencies and setting your key:
pip install --upgrade openai pydanticexport OPENAI_API_KEY="your_api_key_here"python real_route_call.pyRead the evidence pack
Section titled “Read the evidence pack”The script now saves the minimum portfolio version automatically. Open the folder after the run:
ls ch07_workshop_evidenceYou should see:
| File | What to put inside |
|---|---|
README.md | Run command, best prompt version, and the next review step |
token_trace.json | Tokens, token ids, and tiny vectors for every case |
prompt_eval.csv | One row per prompt version and test case, including pass/fail reason |
route_decisions.json | Which first route each case should use |
failure_cases.md | The failures you should inspect before changing Prompt, adding RAG, or planning fine-tuning |
Open failure_cases.md first. It tells you why v1 is not machine-readable and why v2 is still not strict enough. That is the habit this chapter is trying to build: never decide based on one impressive answer; decide from repeatable failures and saved evidence.
Exit checklist
Section titled “Exit checklist”- I can run the workshop locally.
- I can explain why natural-language output is not enough for product workflows.
- I can explain why validation catches both invalid JSON and missing fields.
- I can compare prompt versions with fixed test cases.
- I can explain why fine-tuning should usually come after prompt evaluation and clear failure evidence.
If all five are checked, you have turned Chapter 7 from a concept chapter into a runnable engineering loop.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Workshop Output
- terminal result saved
- Prompt Eval
- pass rate across fixed cases
- Structured Output
- schema validation result
- Failure Log
- failed case and likely cause
- Readme
- what passed, what failed, and what to try next
Workshop review notes and pass criteria
- The workshop passes when the saved evidence folder can explain the run without the terminal history.
- Check
prompt_eval.csvbefore editing prompts. The best next edit should come from a failed fixed case, not from taste. - Treat
failure_cases.mdas the bridge to later RAG or fine-tuning decisions. If the failure is missing knowledge, try retrieval before training; if it is format drift, tighten structured output first. - The page is complete when you can rerun the script, inspect the evidence files, and defend why the next action is prompt, RAG, fine-tuning, or no change.