7.2.1 LLM Overview Roadmap: Capability, Cost, Product Fit
LLM overview is not a model-name list. It helps you decide what a large model can do, what it costs, and when prompting, RAG, Agent, or fine-tuning is a better route.
Look at the Capability Stack First
Section titled “Look at the Capability Stack First”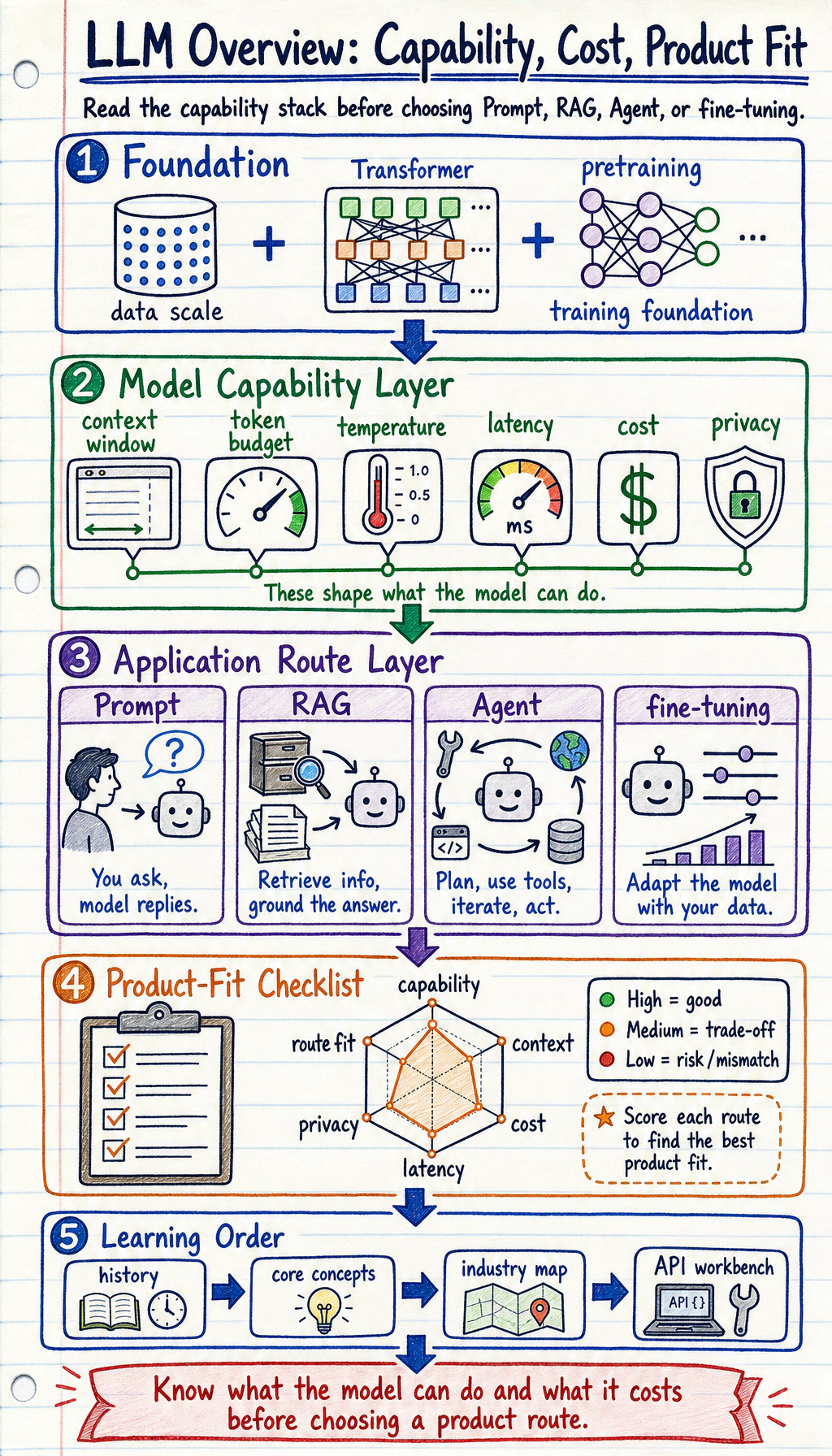

| Route | Use when |
|---|---|
| prompt | the model already knows enough and task is simple |
| RAG | private or changing knowledge must be cited |
| Agent | the model must use tools or take steps |
| fine-tuning | behavior/style/format needs repeated adaptation |
Run One Route Decision
Section titled “Run One Route Decision”request = { "needs_private_docs": True, "needs_tool_action": False, "needs_repeated_style": False,}
if request["needs_tool_action"]: route = "Agent"elif request["needs_private_docs"]: route = "RAG"elif request["needs_repeated_style"]: route = "fine-tuning"else: route = "prompt"
print("recommended_route:", route)Expected output:
recommended_route: RAG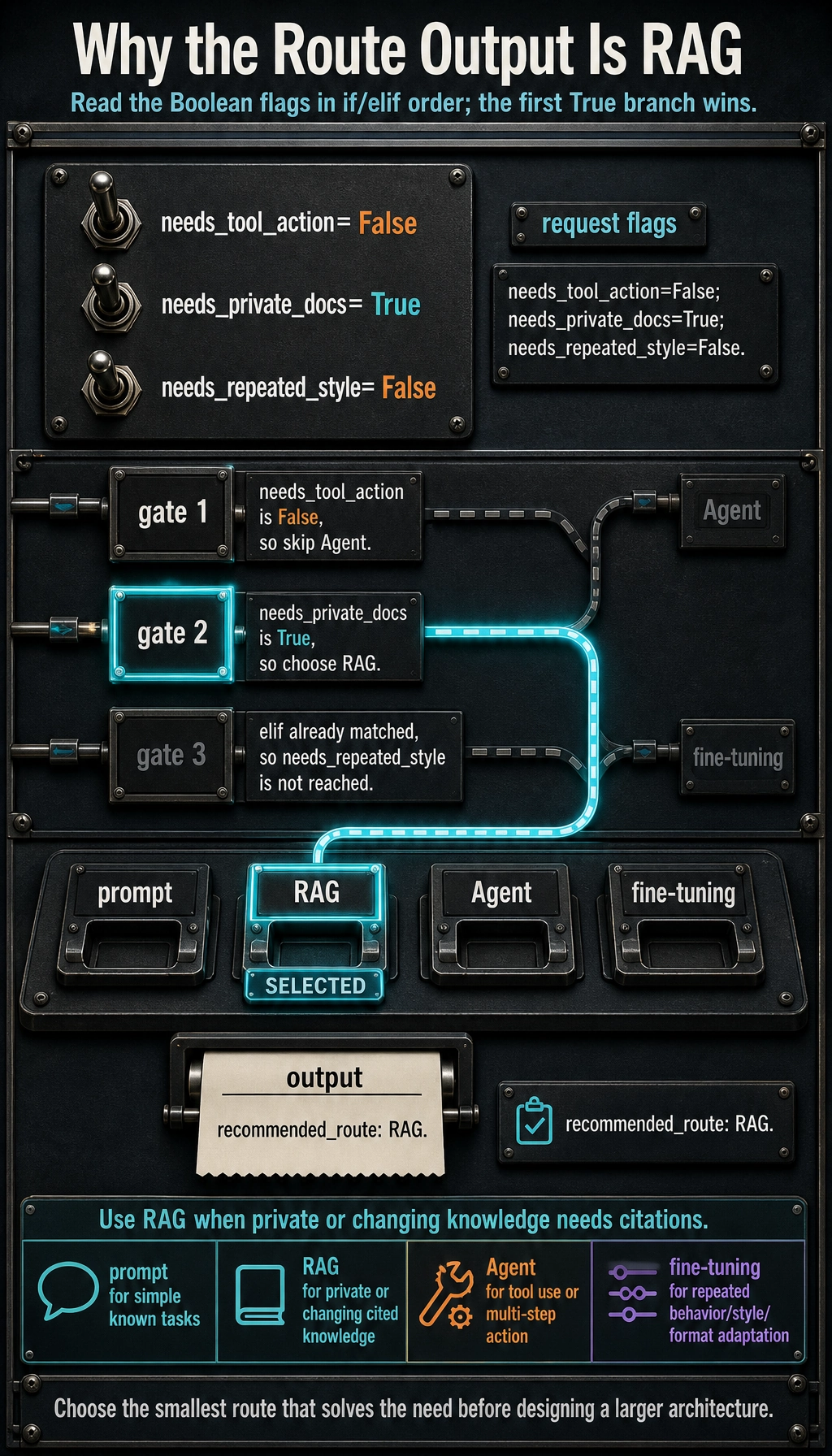
This is not a full architecture decision. It is the habit: choose the smallest route that solves the actual product need.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to keep |
|---|---|---|
| 1 | 7.2.2 Development History | why scaling and instruction tuning mattered |
| 2 | 7.2.3 Core Concepts | context, tokens, temperature, latency, cost |
| 3 | 7.2.4 Industry Landscape | model/provider selection notes |
| 4 | 7.2.5 LLM Call Workbench | one request/response record |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Capability Stack
- tokens, context, pretraining, instruction, alignment
- Cost Check
- context length and output length affect cost/latency
- Product Fit
- choose model behavior by task need, not hype
- Evaluation Loop
- fixed cases, score, failure note
- Next Action
- connect overview to prompt testing in 7.5
Pass Check
Section titled “Pass Check”You pass this roadmap when you can explain one model choice in terms of capability, context, cost, latency, data privacy, and route fit.
Check reasoning and explanation
- A passing answer explains how tokens, context, attention, prompts, and generation behavior connect in one request-response path.
- The evidence should include at least one reproducible prompt or structured-output test, plus notes on why the output passed or failed.
- A good self-check separates prompt design, RAG, fine-tuning, and alignment: use the lightest method that fixes the observed problem.