9.8.1 Evaluation and Safety Roadmap: Score, Guard, Trace
An Agent should not only run. You must know whether it succeeded, whether the process was safe, and where the failure happened.
See the Guardrail Stack First
Section titled “See the Guardrail Stack First”
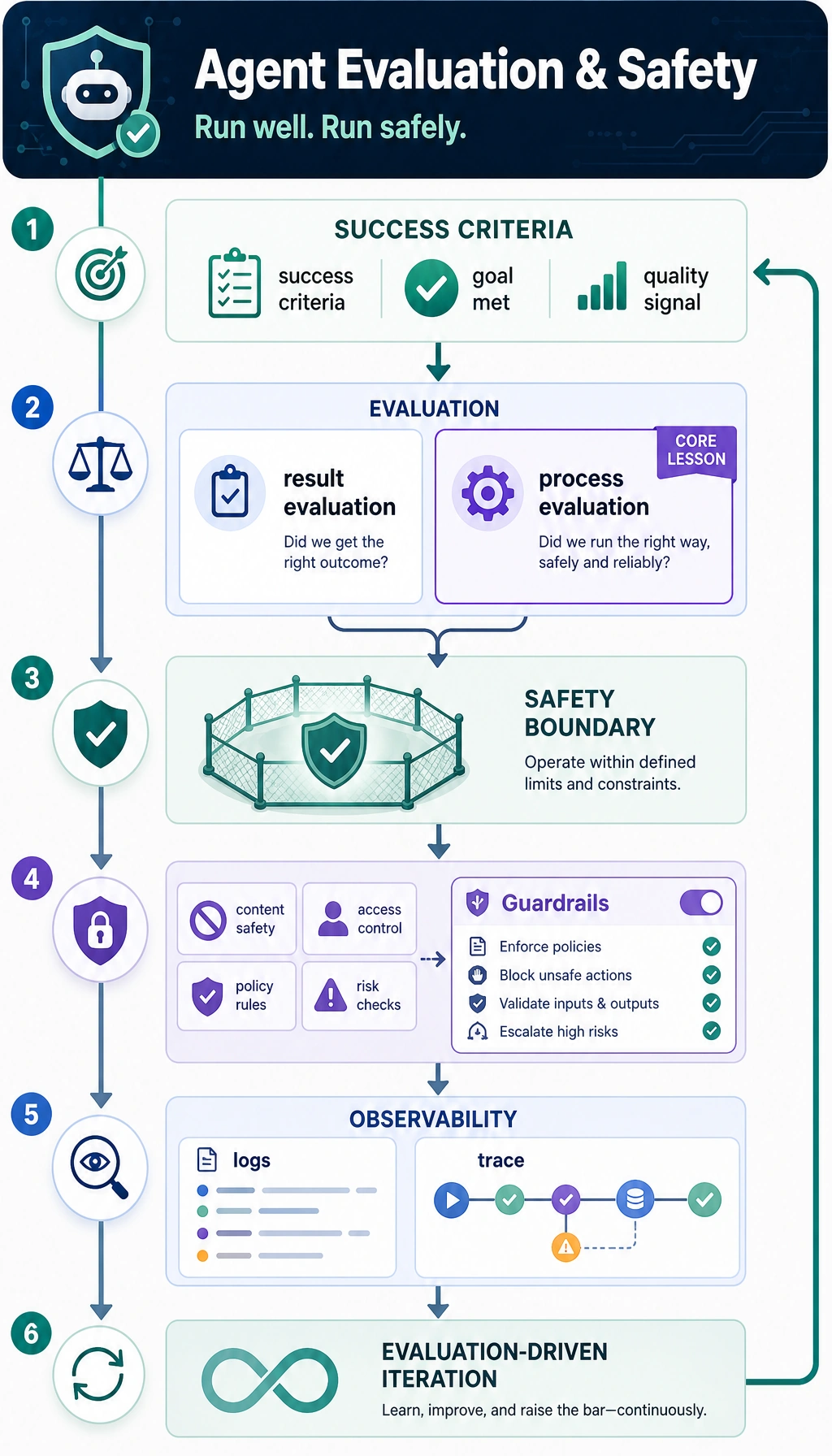
Evaluation tells you whether the system works. Safety tells you what it may do. Observability tells you where it broke.
Run a Launch Scorecard Check
Section titled “Run a Launch Scorecard Check”Evaluate both final output and execution process.
run = { "task_success": True, "tool_error": False, "permission_confirmed": True, "trace_saved": True, "cost_usd": 0.08,}
launch_ok = ( run["task_success"] and not run["tool_error"] and run["permission_confirmed"] and run["trace_saved"] and run["cost_usd"] < 0.10)
print("launch_ok:", launch_ok)print("scorecard:", "task, tools, safety, trace, cost")Expected output:
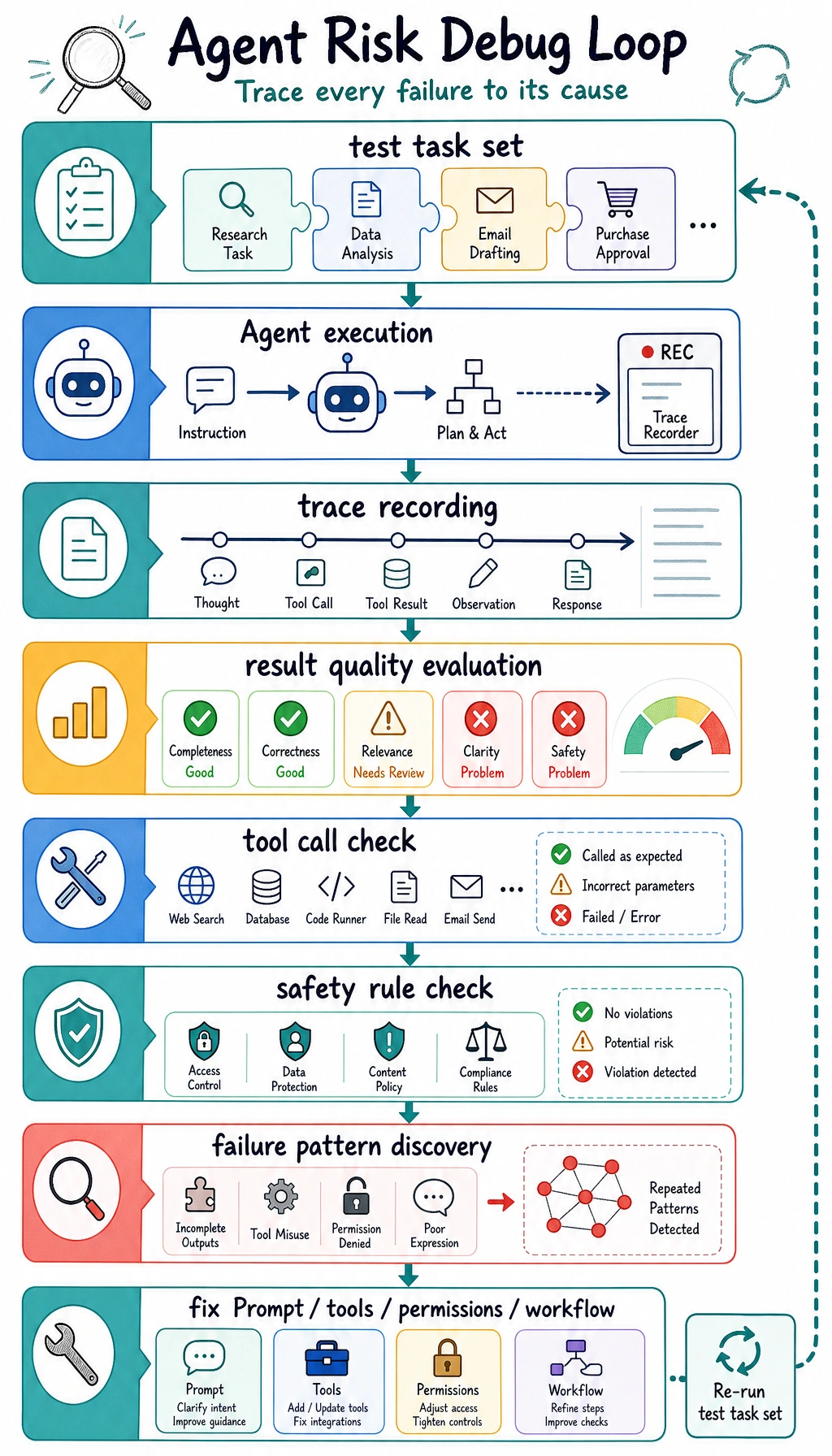
launch_ok: Truescorecard: task, tools, safety, trace, costOne smooth final answer is not enough evidence. Keep replayable tasks and process traces.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Evaluation methods | Separate result evaluation from process evaluation |
| 2 | Benchmarks | Use public benchmarks as reference, not a product replacement |
| 3 | Safety and alignment | Identify prompt injection, over-permission, leakage, hallucination |
| 4 | Guardrails | Add input filter, output validation, permissions, human confirmation |
| 5 | Observability | Save logs, traces, errors, latency, cost, and failure reason |
| 6 | Permission sandbox | Separate read, write, network, message, and destructive actions with allow/confirm/deny rules |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Eval Cases
- fixed tasks and expected safe behavior
- Scorecard
- task success, tool correctness, trace quality, safety
- Guardrail
- policy, permission, validation, or human confirmation
- Sandbox Trace
- action, source, decision, reason, and blocked poisoning case
- Failure Check
- unsafe tool use, prompt injection, hidden state, or unobserved action
- Next Action
- add case, guardrail, log, rollback, or refusal path
Pass Check
Section titled “Pass Check”You pass this chapter when every Agent run can be reviewed through goal, plan, tool calls, observations, final answer, safety rule, cost, and failure reason.
The exit mini project is a 10 to 20 task evaluation set plus at least 3 safety rules.
Check reasoning and explanation
- A passing answer describes the agent loop: goal, plan, tool call, observation, memory or state update, and stop condition.
- The evidence should include a trace that another developer can inspect, not only the final answer.
- A good self-check names one safety or reliability control such as tool schemas, permission boundaries, retries, evaluation cases, or a human-review point.