E.A.6 Model Serving
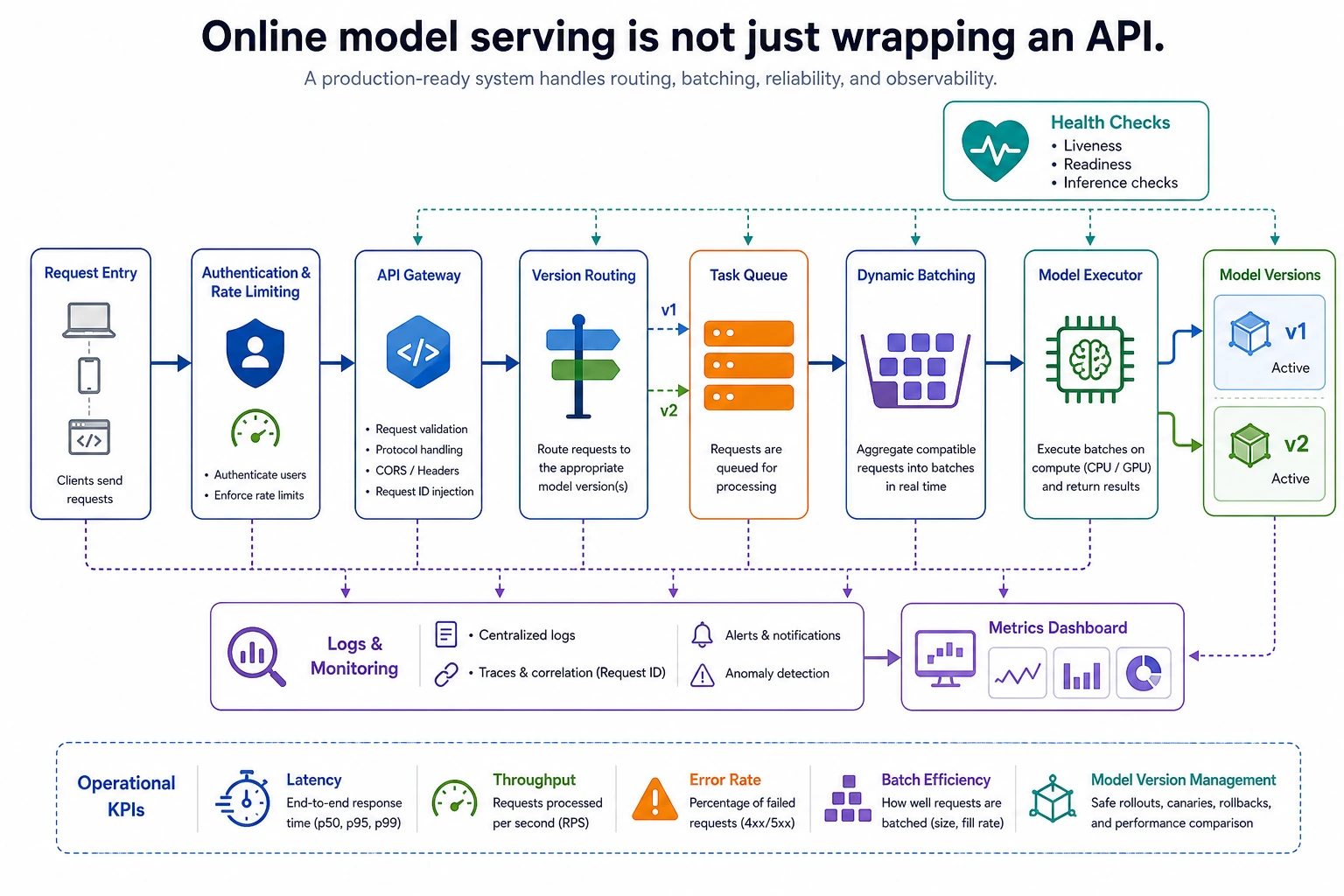
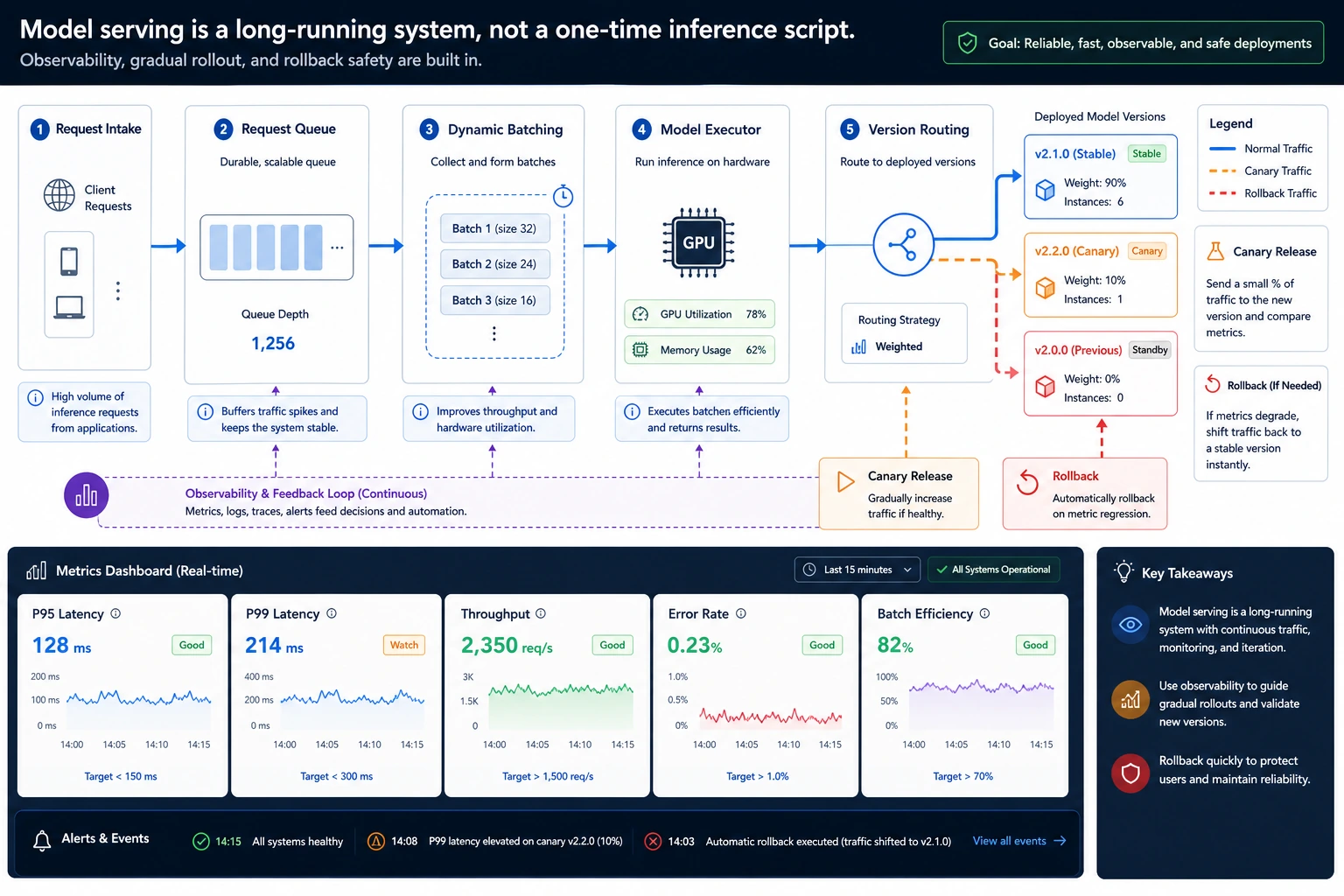
Serving a model is different from calling a model once. A service receives many requests, queues them, batches them, sends them to the right model version, records metrics, and stays recoverable when a version fails.
What You Need
Section titled “What You Need”- Python 3.10+
- No external packages
- Basic understanding of dictionaries and lists
Key Terms
Section titled “Key Terms”- Queue: temporary waiting area for requests.
- Batch: multiple requests processed together.
- Version routing: sending traffic to
v1,v2, or a canary model. - P95 latency: 95% of requests finish within this time.
- Rollback: switching traffic back to a safer version.
Run A Tiny Serving Loop
Section titled “Run A Tiny Serving Loop”Create serving_loop.py:
requests = [ {"id": 1, "version": "v1", "text": "refund"}, {"id": 2, "version": "v1", "text": "invoice"}, {"id": 3, "version": "v2", "text": "change address"}, {"id": 4, "version": "v2", "text": "shipping"}, {"id": 5, "version": "v1", "text": "certificate"},]
batches = {}for request in requests: batches.setdefault(request["version"], []).append(request)
for version, items in batches.items(): print(version, "batch_size=", len(items), "ids=", [item["id"] for item in items])
for item in items: item["answer"] = f"{version}:{item['text']}:ok"
print("answers:")for request in requests: print(request["id"], request["answer"])Run it:
python serving_loop.pyExpected output:
v1 batch_size= 3 ids= [1, 2, 5]v2 batch_size= 2 ids= [3, 4]answers:1 v1:refund:ok2 v1:invoice:ok3 v2:change address:ok4 v2:shipping:ok5 v1:certificate:okThis small script shows the core loop: requests arrive, are grouped by version, processed in batches, and returned with traceable answers.
Serving Review
Section titled “Serving Review”Do not review serving by asking only whether the model answer is correct. Review the whole request path: queue, routing, batching, model version, answer, and metrics. A correct answer that cannot be traced to a request ID is hard to debug when users report a failure.
For a small portfolio project, keep one table with request_id, version, batch_size, latency_ms, and status. This table proves that you understand serving as an operating system around the model, not as a single function call.
Add A Safety Rule
Section titled “Add A Safety Rule”Add this before the batching loop:
requests = [ {"id": 1, "version": "v1", "text": "refund"}, {"id": 2, "version": "v1", "text": "invoice"}, {"id": 3, "version": "v2", "text": "change address"},]healthy_versions = {"v1": True, "v2": False}routed_requests = [ request if healthy_versions[request["version"]] else {**request, "version": "v1"} for request in requests]
print([request["version"] for request in routed_requests])Expected output:
['v1', 'v1', 'v1']Run again. Requests that asked for unhealthy v2 now route back to v1. That is the basic idea behind health checks and rollback.
Metrics To Watch First
Section titled “Metrics To Watch First”Track these before launch:
- Queue wait time
- Average and P95 latency
- Error rate
- Average batch size
- Traffic split by model version
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Deployment Target
- local inference, edge device, model server, or optimization experiment
- Artifact
- C++ snippet, benchmark, model artifact, serving config, or deployment note
- Metric
- latency, memory, throughput, model size, accuracy drop, or reliability
- Failure Check
- ABI/build issue, hardware mismatch, quantization loss, or serving bottleneck
- Expected Output
- reproducible deployment or optimization evidence, not only theory notes
Common Mistakes
Section titled “Common Mistakes”- Reporting only model inference time and ignoring queue, preprocessing, and network time.
- Making batches too large and hurting user-facing latency.
- Replacing the production model without version routing.
- Keeping no request IDs, which makes debugging almost impossible.
Practice
Section titled “Practice”Add a latency_ms field to each request, then compute average latency per version. If v2 is slower than v1 by more than 20 ms, route all future requests back to v1.
Reference implementation and walkthrough
A solid solution groups requests by version, averages latency_ms, and compares the two version averages. If avg_v2 - avg_v1 > 20, mark v2 unhealthy or set its traffic weight to zero for the next batch.
The key explanation is that rollback should be driven by measured serving behavior, not by guesswork. Also mention that a real service would compare P95 latency and error rate too, because averages can hide slow tail cases.