6.7.1 Training Tips Roadmap: Diagnose Before Changing Everything
Training tips are useful only when they answer a diagnosis. Do not change optimizer, learning rate, model size, and data at the same time.
Look at the Diagnosis Flow First
Section titled “Look at the Diagnosis Flow First”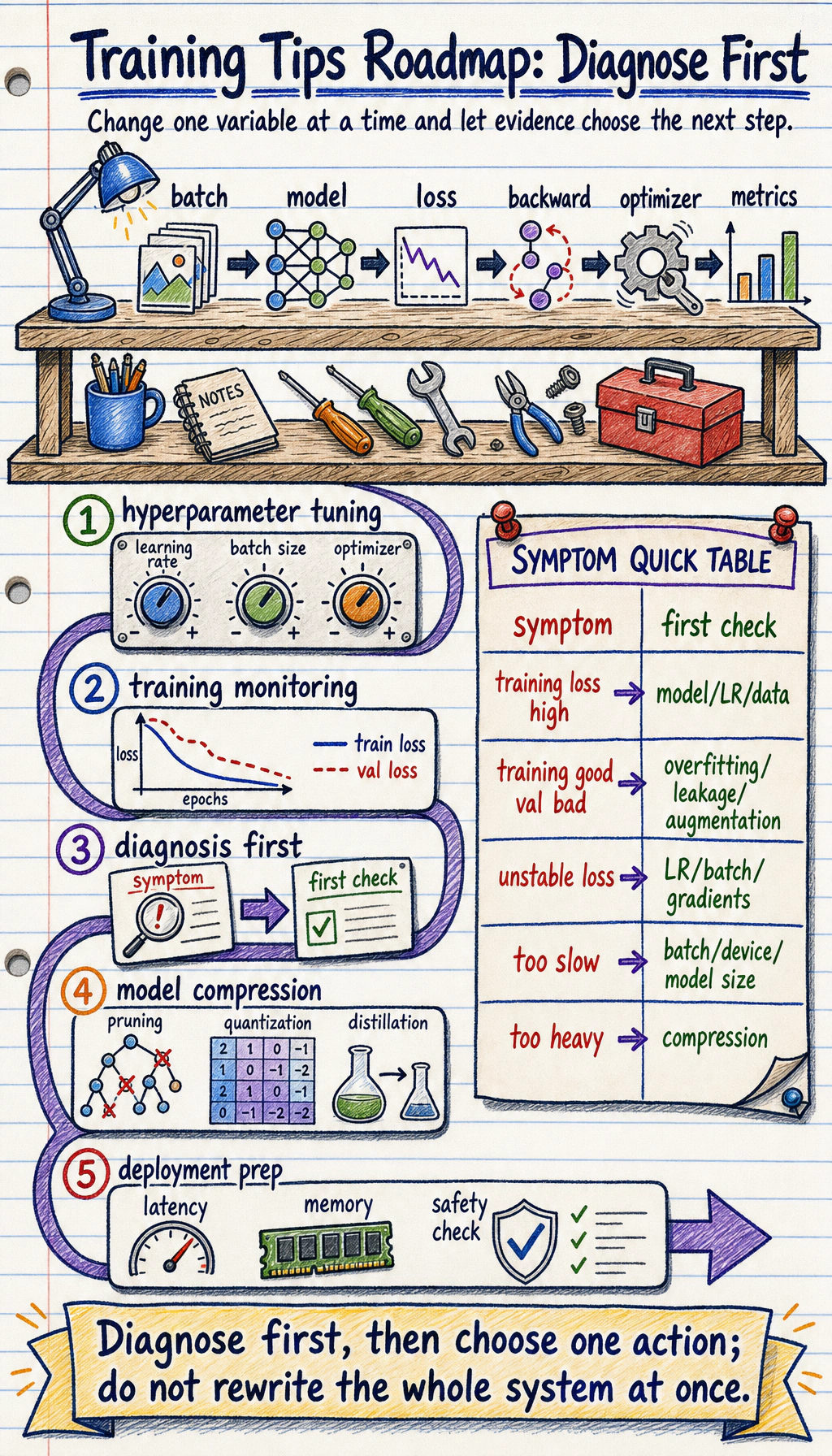
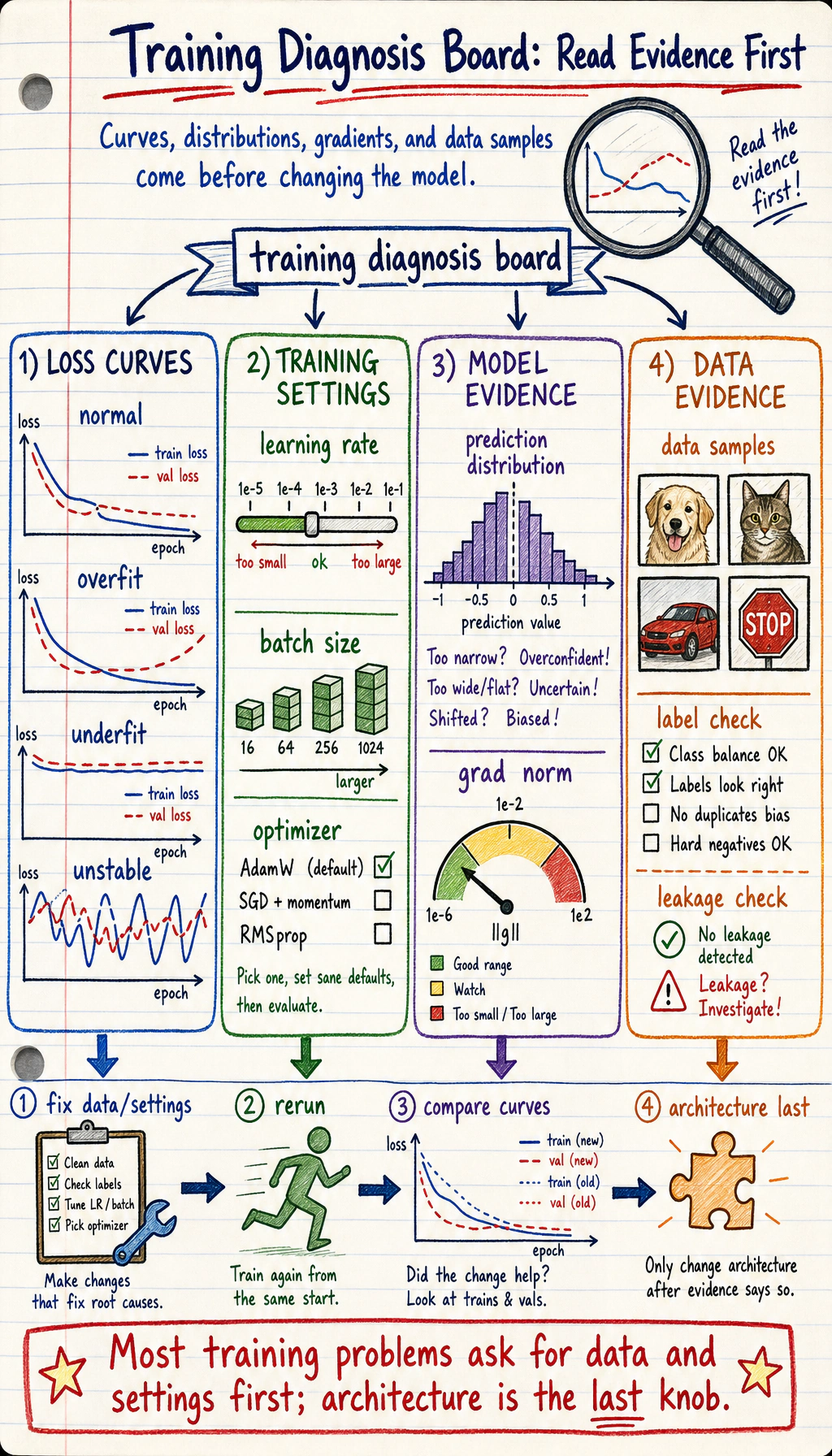
| Symptom | First check |
|---|---|
| training loss high | model too small, learning rate too low, bad data |
| training good, validation bad | overfitting, leakage, weak augmentation |
| unstable loss | learning rate too high, bad batch, exploding gradients |
| too slow | batch size, device, model size |
| too heavy to deploy | compression, quantization, pruning |
Read a Tiny Loss Log
Section titled “Read a Tiny Loss Log”Create training_tips_first_loop.py.
val_loss = [0.62, 0.51, 0.48, 0.49, 0.53]best_epoch = min(range(len(val_loss)), key=val_loss.__getitem__) + 1
print("best_epoch:", best_epoch)print("best_val_loss:", val_loss[best_epoch - 1])print("action: stop or reduce learning rate if validation keeps worsening")Expected output:
best_epoch: 3best_val_loss: 0.48action: stop or reduce learning rate if validation keeps worsening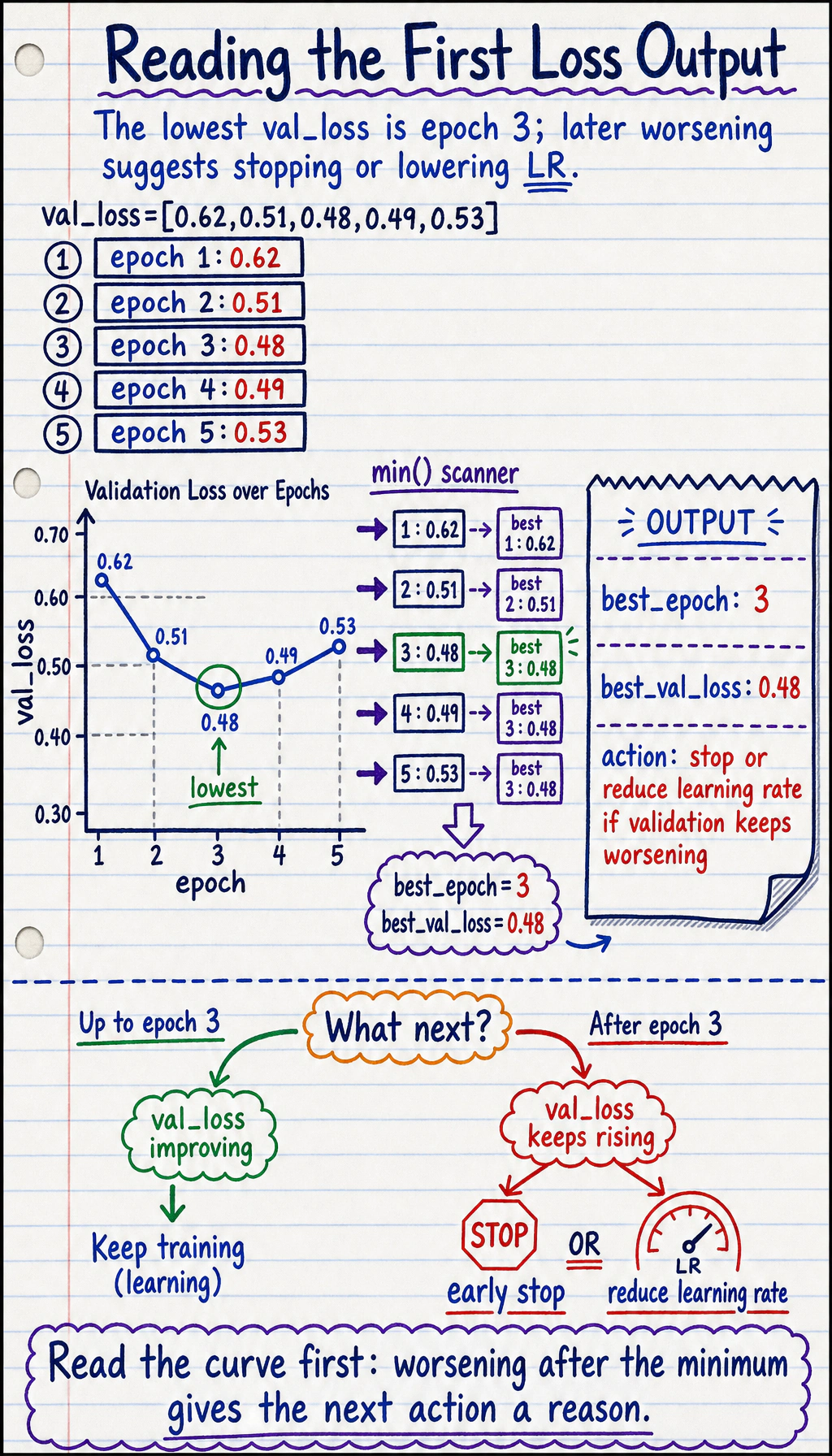
Before adding tricks, read the curve. A simple log often tells you what to try next.
Evidence to Keep
Section titled “Evidence to Keep”After this mini-chapter, keep one diagnosis decision record:
- Visible Symptom
- what did the curve or output show?
- First Check
- data, shape, gradient, or validation split
- One Change
- which single setting changed?
- Before After
- metric or artifact comparison
- Decision
- keep, tune, rollback, or investigate
The point is to make training changes reversible. If you change five things and the run improves, you still do not know which change helped.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to practice |
|---|---|---|
| 1 | 6.7.2 Hyperparameter Tuning | learning rate, batch size, optimizer |
| 2 | 6.7.3 Training Diagnosis | loss curves, overfitting, instability |
| 3 | 6.7.4 Model Compression | smaller, faster, deployable models |
Pass Check
Section titled “Pass Check”You pass this roadmap when you can look at a training/validation curve and choose one next action with a reason.
Check reasoning and explanation
- A passing answer connects tensors, model layers, loss,
backward(), and optimizer updates into one training loop. - The evidence should include a runnable mini experiment, tensor-shape checks, and a loss or validation curve you can explain.
- A good self-check names one failure mode such as shape mismatch, no loss decrease, overfitting, data leakage, or using Attention/Transformer words without explaining the data flow.