8.1.6 RAG Optimization
Learning Objectives
Section titled “Learning Objectives”By the end of this section, you will be able to:
- Identify the most common optimization points in a RAG system
- Understand how chunk, top-k, rerank, and prompt affect results
- Learn how to build a simple context packing strategy
- Develop an optimization mindset of “find the bottleneck first, then tune the parameters”
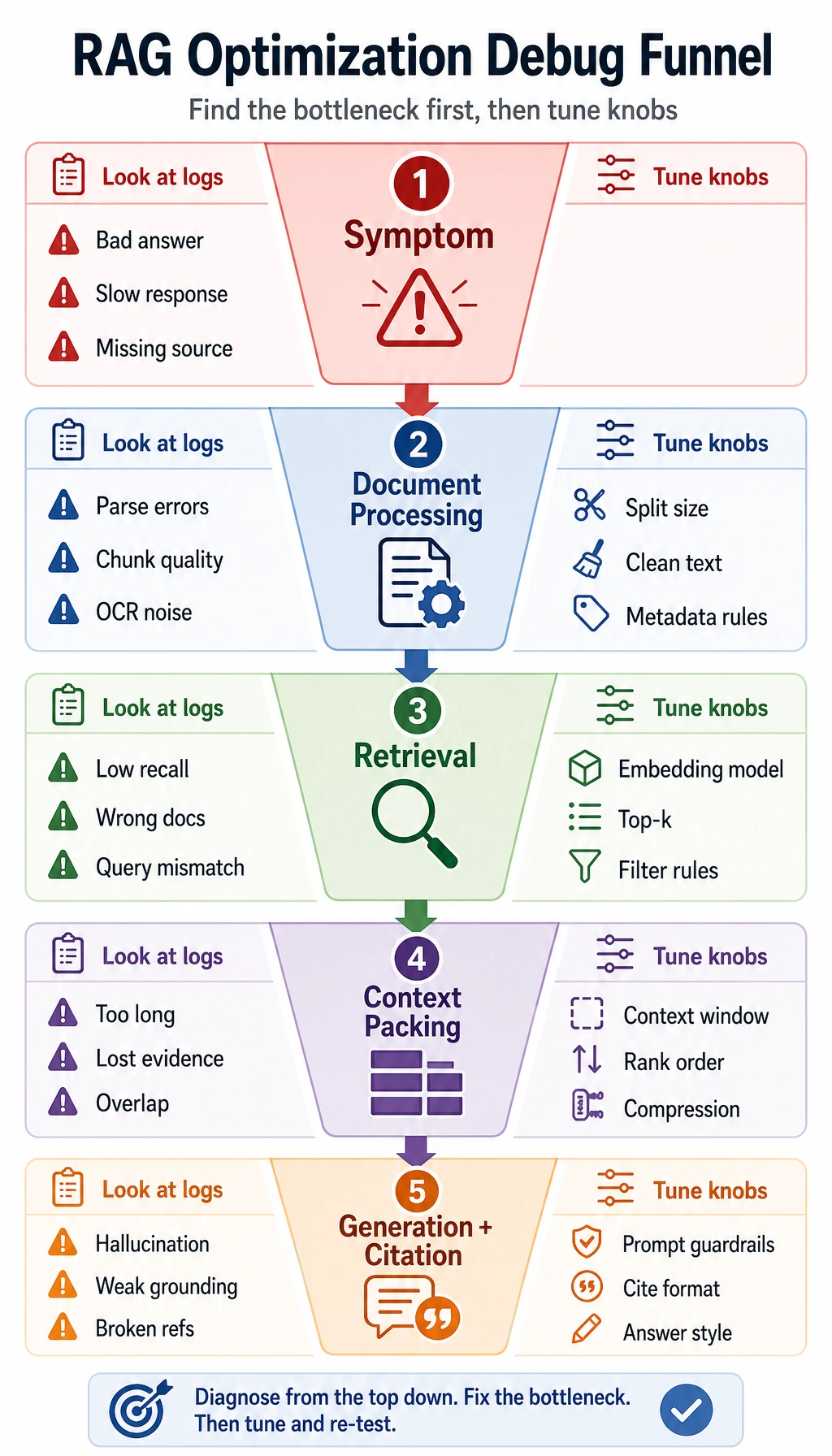
First locate which stage has the problem before optimizing
Section titled “First locate which stage has the problem before optimizing”A RAG system usually has four stages
Section titled “A RAG system usually has four stages”It can be roughly broken down into:
- Document processing
- Retrieval
- Context packing
- Answer generation
If the answer quality is poor, you should first ask:
- Did it fail to find the right information?
- Or did it find it but not include it?
- Or did it include it, but the model did not use it well?
Different problems call for different optimization directions
Section titled “Different problems call for different optimization directions”| Symptom | Common problem area |
|---|---|
| There is clearly an answer, but it was not retrieved | Chunking / embedding / retrieval strategy |
| The right content was retrieved, but the answer is still off | Prompt / context packing / model summarization |
| The answer is slow and expensive | top_k too large / context too long / too much reranking |
Start optimizing from document processing
Section titled “Start optimizing from document processing”Chunk size is not better just because it is larger
Section titled “Chunk size is not better just because it is larger”If chunks are too large:
- Retrieval becomes less precise
- Context usage grows too much
If chunks are too small:
- Information gets split apart too easily
- Evidence becomes incomplete
So the usual goal is not “the bigger the safer,” but finding a balance.
Preserving structural information is often important
Section titled “Preserving structural information is often important”The value of many documents is not only in the sentences themselves, but also in:
- Headings
- Paragraph hierarchy
- Table association
- Page location
If you remove all of this structure during cleaning, retrieval quality often gets worse later.
A few of the most commonly tuned levers in retrieval
Section titled “A few of the most commonly tuned levers in retrieval”top_k: bigger is not always better
Section titled “top_k: bigger is not always better”Many people initially think:
If we retrieve more materials, it should be safer, right?
Not necessarily.
When top_k is too large, irrelevant content may be brought in as well, which can actually distract the model.
Rerank: cast a wide net first, then filter more carefully
Section titled “Rerank: cast a wide net first, then filter more carefully”When coarse retrieval brings in a lot of borderline content, rerank is very helpful. It is not just “doing one more step”; it increases the density of useful context.
Context packing matters more than many people think
Section titled “Context packing matters more than many people think”The model does not automatically “use” information just because it sees it
Section titled “The model does not automatically “use” information just because it sees it”Even if the correct content is retrieved, you may still see:
- Key evidence buried in the middle
- Multiple chunks in a messy order
- Too much repeated information
So “which chunks to include, and in what order” is itself an optimization point.
A runnable example of context packing
Section titled “A runnable example of context packing”chunks = [ {"score": 0.95, "text": "Refund policy: Within 7 days of purchase and if learning progress is below 20%, you can get a refund."}, {"score": 0.80, "text": "Certificate description: A certificate is awarded after completing all projects and passing the tests."}, {"score": 0.76, "text": "Learning order: It is recommended to learn Python first, then machine learning."}, {"score": 0.72, "text": "Additional terms: A refund request must include order information."}]
def pack_context(chunks, max_chars=60): packed = [] total = 0 for item in sorted(chunks, key=lambda x: x["score"], reverse=True): text = item["text"] if total + len(text) > max_chars: continue packed.append(text) total += len(text) return packed
selected = pack_context(chunks, max_chars=130)print("Chunks finally packed into the context:")for c in selected: print("-", c)Expected output:
Chunks finally packed into the context:- Refund policy: Within 7 days of purchase and if learning progress is below 20%, you can get a refund.This is the simplest form of “context budget management.”
How do we optimize the generation stage?
Section titled “How do we optimize the generation stage?”The prompt should clearly tell the model how to use the materials
Section titled “The prompt should clearly tell the model how to use the materials”Many times the problem is not that the materials were not found, but that the model was not clearly instructed to:
- Answer only based on the provided materials
- Admit when the evidence is insufficient
- Cite the source
A common prompt idea is:
“Please answer only according to the following materials; if the materials are insufficient, clearly say so.”
Citing sources can significantly improve controllability
Section titled “Citing sources can significantly improve controllability”Having the answer include sources usually has several benefits:
- Users trust it more
- It is easier for humans to verify
- It becomes easier to debug which document actually took effect
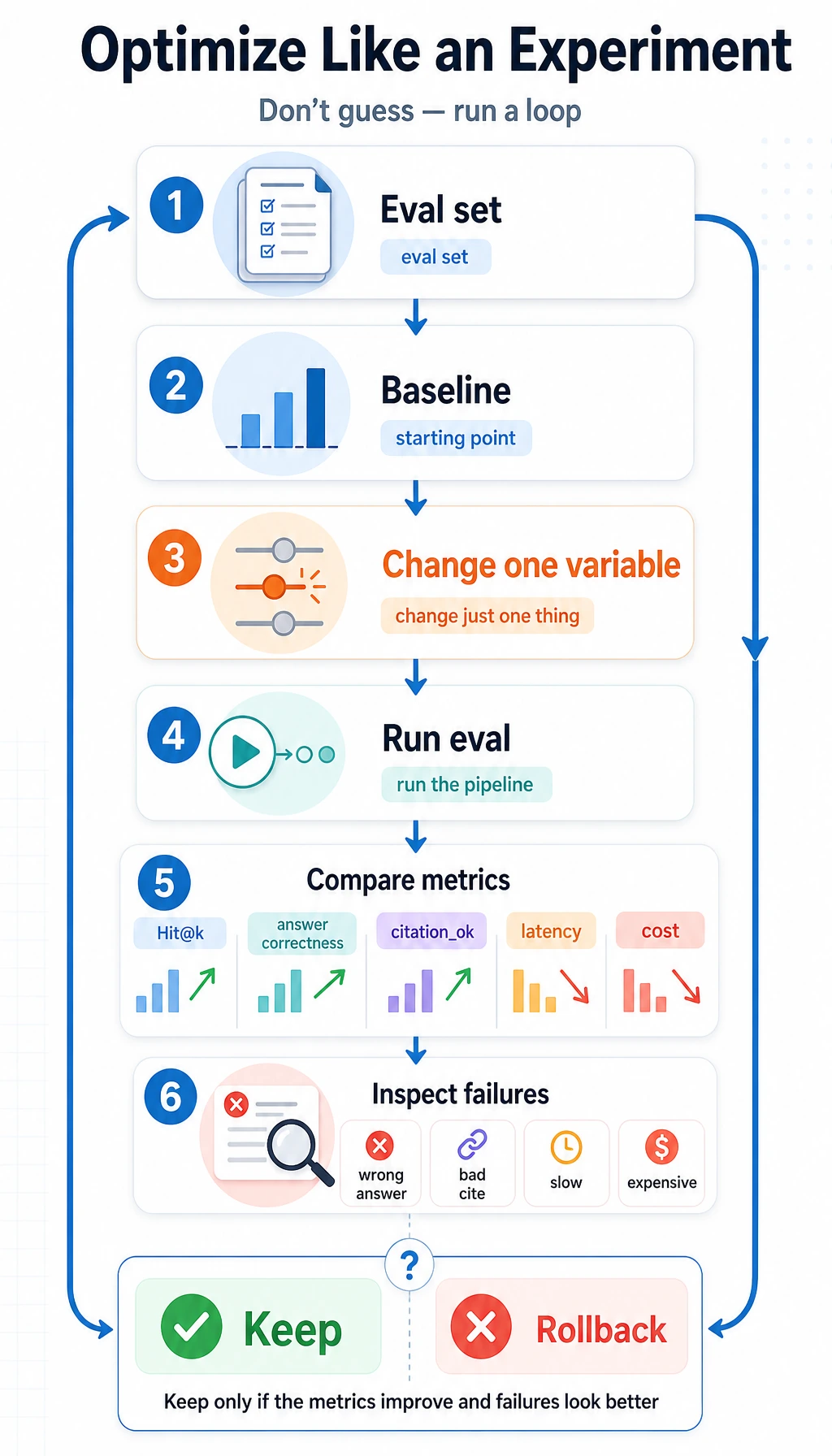
A simple way to think about optimization experiments
Section titled “A simple way to think about optimization experiments”Do not change five parameters at once
Section titled “Do not change five parameters at once”It is better to follow this order:
- Fix the evaluation set
- Set a baseline
- Change only one variable at a time
For example:
- First change only chunk size
- Then change only top-k
- Then add rerank
A small configuration comparison script
Section titled “A small configuration comparison script”configs = [ {"chunk_size": 200, "top_k": 3}, {"chunk_size": 400, "top_k": 3}, {"chunk_size": 200, "top_k": 5}]
fake_scores = { (200, 3): 0.78, (400, 3): 0.71, (200, 5): 0.74}
for cfg in configs: key = (cfg["chunk_size"], cfg["top_k"]) print(cfg, "-> evaluation score", fake_scores[key])Expected output:
{'chunk_size': 200, 'top_k': 3} -> evaluation score 0.78{'chunk_size': 400, 'top_k': 3} -> evaluation score 0.71{'chunk_size': 200, 'top_k': 5} -> evaluation score 0.74Although this is toy data, it expresses an important engineering habit: Optimization should rely on comparison experiments, not intuition.
Common trade-offs in RAG optimization
Section titled “Common trade-offs in RAG optimization”Quality vs cost
Section titled “Quality vs cost”- Larger
top_k: may be more complete, but more expensive - Stronger reranker: may be more accurate, but slower
Recall vs precision
Section titled “Recall vs precision”- Too little retrieval: may miss the answer
- Too much retrieval: may introduce noise
Real-time performance vs stability
Section titled “Real-time performance vs stability”- Retrieving fresh information in real time is more flexible
- More thorough preprocessing is usually more stable
There is no universal best solution, only the best solution for a given scenario.
If your goal is an “SOP document assistant driven by a knowledge base,” what optimization order is best?
Section titled “If your goal is an “SOP document assistant driven by a knowledge base,” what optimization order is best?”A very common mistake in this kind of project is:
- Switching to a larger model right away
- Or increasing
top_ktoo much right away
But a more stable default order is usually:
- First check whether document parsing is correct
- Then check whether knowledge chunks are properly separated into policies / handled cases / checklists
- Then check whether retrieval actually brings back the right content
- Then check whether structured output and templates place policies, cases, and checklists in the right positions
- Only at the end, tune the model and prompt
You can compress this into one sentence:
For this kind of project, prioritize optimizing “finding the right content” and “placing it correctly,” and only then optimize “writing it more beautifully.”
A minimal optimization checklist more like an SOP document project
Section titled “A minimal optimization checklist more like an SOP document project”| Symptom | What should you check first |
|---|---|
| The topic is right, but there are no handled cases | Document parsing / content type labeling |
| The case was found, but it was placed in the policy section | Schema / template mapping |
| There is a lot of material, but the output is still empty | Retrieval filtering / top-k / context packing |
| The internal docs clearly have the standard answer, but external content misleads the model | Source priority strategy |
This table is especially useful for beginners because it pushes “optimization” back down into several layers that can actually be inspected.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Query
- one user question or test case
- Retrieved Chunks
- chunk ids, scores, and source titles
- Answer
- final response with citation or source note
- Failure Check
- missing evidence, wrong chunk, stale doc, or unsupported claim
- Next Action
- chunking, embedding, reranking, prompt, or eval change
Common beginner mistakes
Section titled “Common beginner mistakes”Switching to a larger model right away
Section titled “Switching to a larger model right away”Many RAG problems are not because the model is too weak, but because the retrieval pipeline is not tuned well.
Only looking at a single demo, without stable evaluation
Section titled “Only looking at a single demo, without stable evaluation”Getting one answer right does not mean the system is stable.
Increasing top_k over and over
Section titled “Increasing top_k over and over”More context is not always better, especially when the context contains too many irrelevant chunks.
RAG Optimization Troubleshooting Matrix
Section titled “RAG Optimization Troubleshooting Matrix”When doing optimization for real, the most useful skill is not memorizing many tricks, but being able to map the symptom to a specific pipeline stage.
- Correct material does not appear: first inspect the query, raw top-k hits, and chunk text. Try chunking adjustment, keyword search, or query rewrite. Do not begin by switching to a larger generation model.
- Correct material is ranked too low: first inspect each chunk’s score and ranking. Try reranking or hybrid retrieval weights. Do not blindly increase top-k.
- Correct material is in context, but conditions are missing: first inspect final context, prompt, and answer citations. Try context packing and line-by-line citation requirements. Do not only change the embedding model.
- Wrong source is cited: first inspect the answer,
source_refs, and evidence snippets. Try citation checks and stricter citation format. Do not only check whether the answer sounds fluent. - Latency and cost jump: first inspect
top_k, rerank count, and context length. Try candidate limits, caching, or hierarchical retrieval. Do not increase top-k and model size at the same time.
How to use this table: pick one symptom at a time, find the matching logs, and then decide which lever to adjust. Do not change chunk, embedding, top-k, rerank, and prompt all at once when you do not yet know which layer the problem is in.
A fixed optimization experiment workflow
Section titled “A fixed optimization experiment workflow”RAG optimization should feel like experimentation, not like tuning mysterious parameters. A beginner-friendly workflow is: first fix 20 to 50 evaluation questions, then run a baseline, record retrieval hits, answer correctness, and whether citations support the conclusion, and then change only one variable at a time.
| Step | Deliverable | Success criterion |
|---|---|---|
| Build a baseline | Current config, evaluation set, failure samples | Can reproduce the same batch of results |
| Change one variable | For example, change only chunk size or add rerank | All other settings stay the same |
| Compare metrics | Hit@k, answer accuracy, citation faithfulness, average latency | At least one key metric improves, and side effects are acceptable |
| Review failure cases | List both new failures and fixed failures | Understand why it got better or worse |
| Decide whether to keep it | Write one conclusion sentence | Not “it feels better,” but “it works better for which type of problem” |
An optimization record can look like this:
baseline: keyword search,top-k=3. It is stable on exact terminology but weak on paraphrased questions. Keep it as the control group.exp-1: add query rewrite. It improves paraphrased questions, but may create a few incorrect rewrites. Keep it only if rewrites are logged.exp-2: add rerank. Correct materials move higher, but latency increases. Make it the standard version only if latency is acceptable.
Checking the trade-off between cost, latency, and quality
Section titled “Checking the trade-off between cost, latency, and quality”A RAG system is not only about getting the highest score. In real projects, you also need to consider whether users can afford to wait, whether the cost is manageable, and whether the results are stable.
| Optimization action | Possible benefit | Possible cost | When it is suitable |
|---|---|---|---|
Increase top_k | Reduce missed retrievals | Longer context, more noise, higher cost | When the correct material often does not enter the candidate set |
| Add rerank | Better ranking accuracy | More latency, higher implementation complexity | When the answer is in the candidate set but ranked too low |
| Query rewrite | Better matches for conversational questions | May distort the question | When user wording differs greatly from document wording |
| Stronger embedding | Better semantic retrieval | Rebuild index, increased cost | When the baseline proves semantic retrieval is the bottleneck |
| Stricter prompt | Fewer hallucinations | May make answers more conservative | When the model tends to make things up even when materials are insufficient |
When optimizing, remember one principle: if the system does not yet have retrieval logs and an evaluation set, do not rush to add complex components. Without observation, it is hard to tell whether a complex component is solving the problem or creating new uncertainty.
Summary
Section titled “Summary”The most important takeaway in this section is:
RAG optimization is not just changing one parameter; it is about finding balance among retrieval quality, context quality, generation constraints, cost, and speed.
Truly effective optimization usually starts by locating the bottleneck, not by blindly stacking more components.
Exercises
Section titled “Exercises”- Change
max_charsinpack_context()and observe how the selected chunks change. - Create your own set of different
chunk_size / top_kconfigurations and practice running small comparison experiments. - Think about this: if the system always “retrieves the right material, but the answer is still off,” what should you optimize next?
Reference implementation and walkthrough
- Lower
max_charsforces the system to drop more chunks or shorten context; highermax_charsincludes more evidence but can add noise and cost. The useful setting is the smallest context that still preserves the needed evidence. - A good comparison changes one variable at a time and records retrieval hit, answer correctness, citation quality, latency, and token cost. Without fixed test questions, optimization becomes guesswork.
- If retrieval is correct but the answer is off, optimize prompt grounding, citation requirements, answer schema, reranking, context ordering, or post-generation verification before changing the vector database.