6.1.1 Neural Network Roadmap: Linear Layer, Activation, Loss, Update
Neural networks are not magic. A layer first does a weighted sum, then an activation changes the shape of the signal, then training adjusts weights to reduce loss.
Look at the Flow First
Section titled “Look at the Flow First”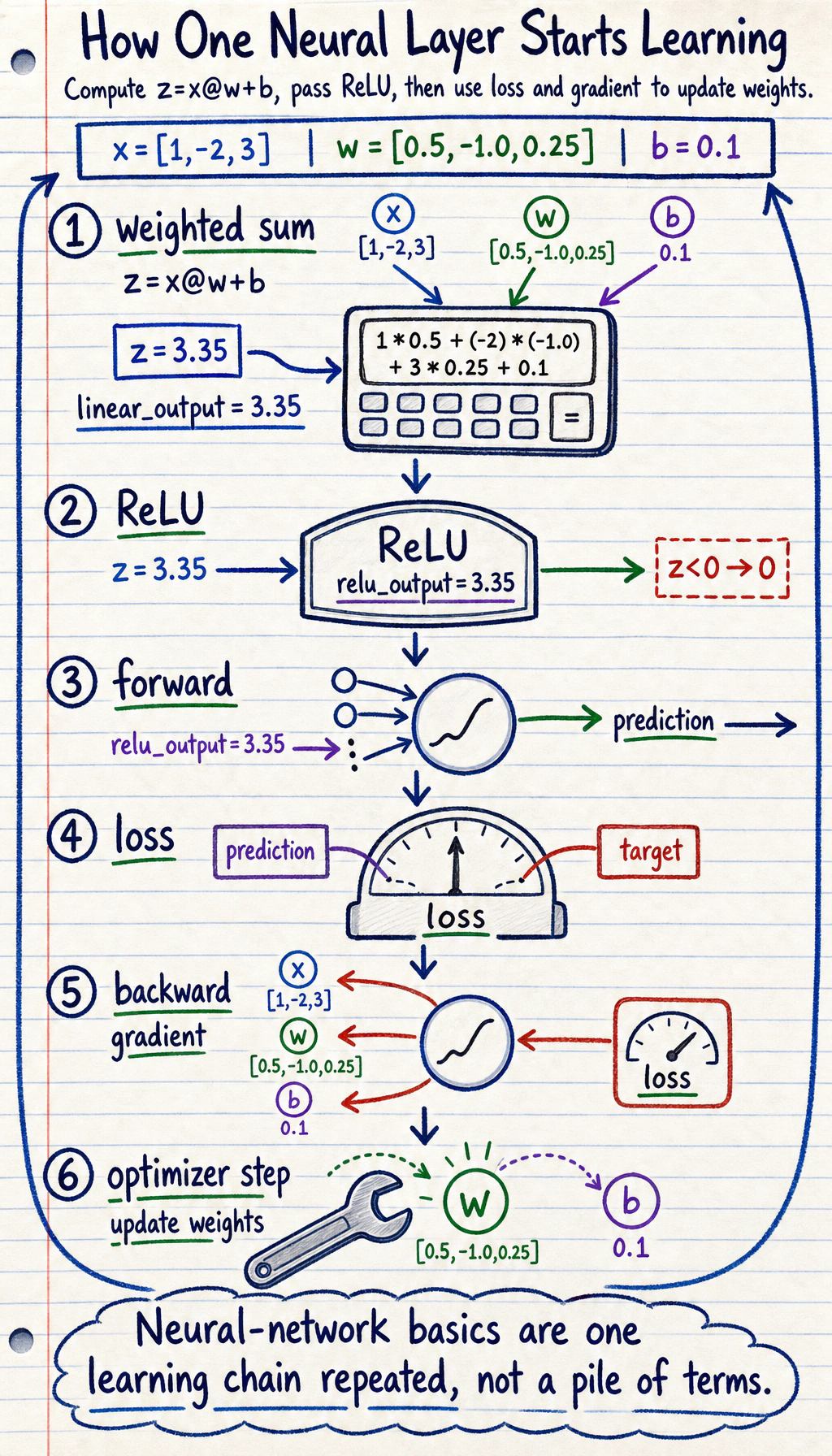
Keep this loop:
inputweighted sumactivationlossgradientupdate weights
| Word | First meaning |
|---|---|
| neuron | weighted sum plus bias |
| activation | nonlinearity such as ReLU |
| forward pass | compute prediction |
| backward pass | compute responsibility for error |
| optimizer | update weights using gradients |
Run One Neuron
Section titled “Run One Neuron”Create nn_first_loop.py and run it after installing torch.
import torch
x = torch.tensor([[1.0, -2.0, 3.0]])weights = torch.tensor([[0.5], [-1.0], [0.25]])bias = torch.tensor([0.1])
linear_output = x @ weights + biasactivated = torch.relu(linear_output)
print("linear_output:", round(linear_output.item(), 3))print("relu_output:", round(activated.item(), 3))Expected output:
linear_output: 3.35relu_output: 3.35If the linear output were negative, ReLU would turn it into 0. That small gate is what lets stacked layers model nonlinear patterns.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to focus on |
|---|---|---|
| 1 | 6.1.2 ML to DL Bridge | what changes after sklearn |
| 2 | 6.1.3 Neurons and Activation | weighted sum, bias, ReLU |
| 3 | 6.1.4 Forward and Backward | prediction, loss, gradient |
| 4 | 6.1.5 Optimizers | SGD, Momentum, Adam intuition |
| 5 | 6.1.6 Regularization | overfitting controls |
| 6 | 6.1.7 Weight Initialization | stable starting points |
| 7 | 6.1.8 Optional History | why backprop, CNN, RNN, Attention, and Transformer appeared |
Evidence to Keep
Section titled “Evidence to Keep”By the end of 6.1, keep one short note with these four lines:
- One Layer
- input @ weights + bias
- Nonlinearity
- activation lets stacked layers model curved patterns
- Training
- forward → loss → backward → optimizer step
- Debug First
- check shape, loss, gradient, update
This note becomes the pocket map for PyTorch, CNN, RNN, and Transformer later in Chapter 6.
Pass Check
Section titled “Pass Check”You pass this roadmap when you can explain one layer as input @ weights + bias, describe what an activation does, and connect loss, gradient, and optimizer into one training loop.
Check reasoning and explanation
- A passing answer connects tensors, model layers, loss,
backward(), and optimizer updates into one training loop. - The evidence should include a runnable mini experiment, tensor-shape checks, and a loss or validation curve you can explain.
- A good self-check names one failure mode such as shape mismatch, no loss decrease, overfitting, data leakage, or using Attention/Transformer words without explaining the data flow.