7.4.5 Rent a GPU and Train a Hand-Built GPT-2
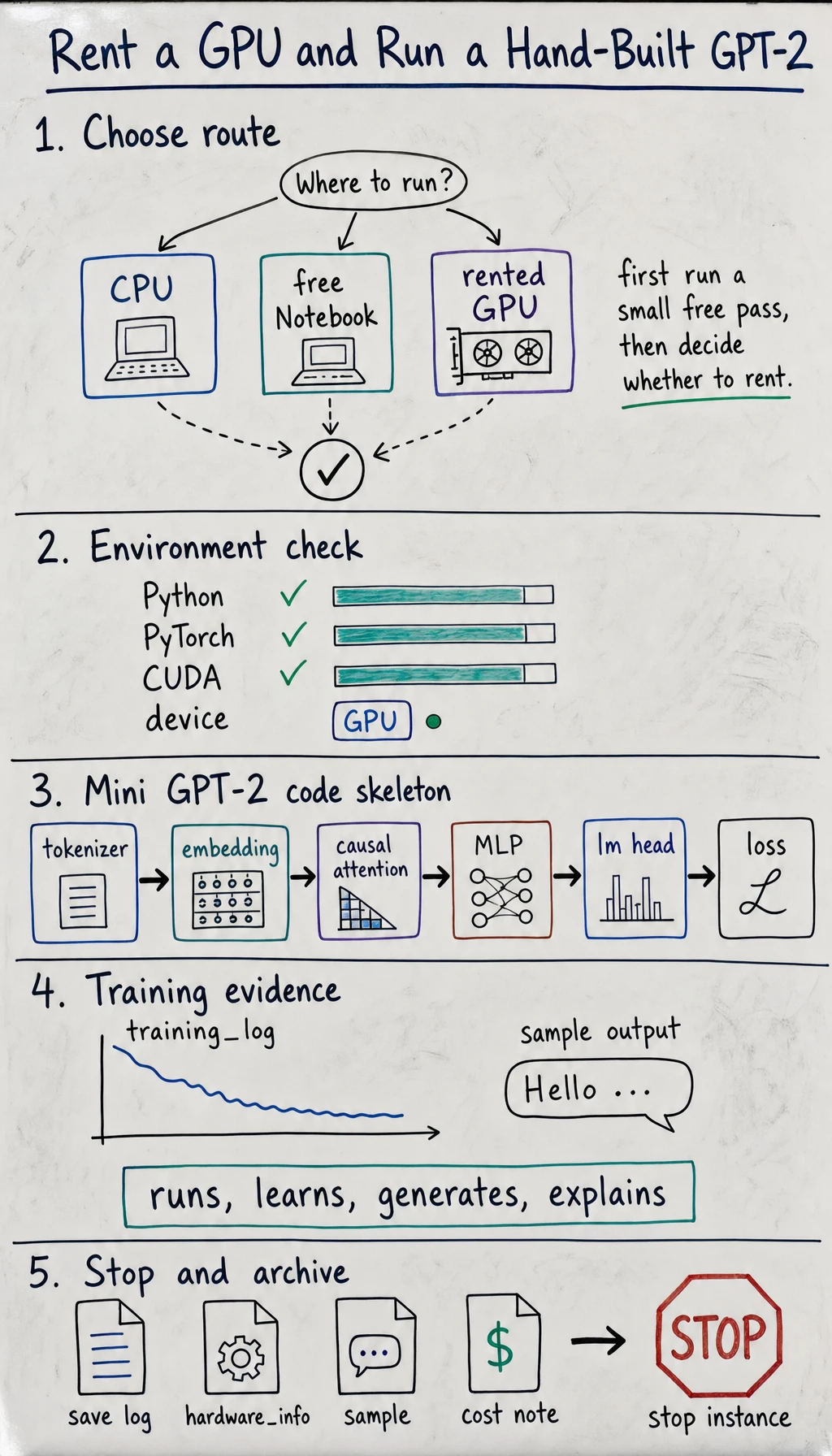
Learning Goals
Section titled “Learning Goals”- Decide when to use a free notebook and when to rent a low-cost GPU.
- Create a Python, PyTorch, and CUDA-ready training environment.
- Run a single-file mini GPT-2 training script on GPU.
- Explain embedding, causal self-attention, MLP, loss, checkpointing, and generation.
- Save training logs, hardware information, checkpoint path, sample output, and shutdown proof as evidence.
1. Choose a GPU Option First
Section titled “1. Choose a GPU Option First”Do not start by chasing the largest card. Course labs should first make sure every learner can finish.
| Option | Best for | Recommended use | Watch out for |
|---|---|---|---|
| Kaggle Notebook | Free-first public courses | Enable GPU and run mini GPT-2 | Quotas change and GPU is not guaranteed |
| Colab Free | Fast trial runs | Validate code and logs | GPU model and session length vary |
| Lightning AI free tier | Cloud development workflow | Save projects and repeat experiments | Free credits can run out |
| AutoDL / RunPod | Stable 1-3 hour labs | Rent RTX 4090, L4, A10, or A5000 | Stop and delete instances when done |
| A100 / H100 | Understanding large-scale costs | Demo or advanced challenge only | Too expensive for required course work |
Recommended Config for This Lesson
Section titled “Recommended Config for This Lesson”| Goal | Minimum | More comfortable |
|---|---|---|
| Smoke-test the script | CPU or free notebook | Any machine that can import PyTorch |
| Pass this lesson | Any visible CUDA GPU, such as T4 | T4, L4, A10, 4090, or A5000 |
| See clear loss decrease | Free T4 for 300-800 steps | 4090 or A5000 for 1000-3000 steps |
| Try a larger model | 16GB VRAM | 24GB VRAM |
The default script is tiny and can fall back to CPU, but CPU completion is only a preflight. A full pass for this lesson requires at least one log where device: cuda appears. That requirement teaches the real training workflow: environment check, GPU memory discipline, logs, checkpoint, copied-back evidence, and shutdown.
2. Checklist Before Paying
Section titled “2. Checklist Before Paying”Before you start a paid machine, confirm four things:
- Budget: decide the maximum cost for this lab, such as a few dollars.
- Machine: prefer 16GB or 24GB VRAM; the most expensive card is unnecessary.
- Image: choose a PyTorch image, ideally with CUDA preinstalled.
- Exit path: know where to stop billing and delete the instance.
Common routes:
Free route: Kaggle / Colab -> enable GPU -> upload or create script -> runChina low-cost route: AutoDL -> choose PyTorch image -> open Jupyter or SSH -> runInternational low-cost route: RunPod -> choose PyTorch template -> open terminal -> runCost rule: run a short CPU or free-notebook smoke test first, then use GPU for the official run. Do not burn money while debugging imports, file paths, or missing CUDA images.
3. Open the Environment and Check PyTorch
Section titled “3. Open the Environment and Check PyTorch”Run this in a notebook or remote terminal:
python -Vpython - <<'PY'import torchprint("torch:", torch.__version__)print("cuda available:", torch.cuda.is_available())print("device:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "cpu")PYExpected output is similar to:
torch: 2.x.xcuda available: Truedevice: Tesla T4If cuda available is False, do not start training yet. Check whether the notebook accelerator is enabled or whether the cloud instance uses a CUDA PyTorch image.
4. Create the Single-File Script
Section titled “4. Create the Single-File Script”Create mini_gpt2_train.py. Copy the full script first; do not tune parameters before the first successful run.
import mathimport timefrom dataclasses import dataclass
import torchimport torch.nn as nnimport torch.nn.functional as F
text = """To build a language model, we ask it to predict the next token.The model reads previous tokens, mixes context with attention, and produces logits.Small experiments teach the same training loop as large models."""
chars = sorted(set(text))stoi = {ch: i for i, ch in enumerate(chars)}itos = {i: ch for ch, i in stoi.items()}data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long)
def decode(ids): return "".join(itos[int(i)] for i in ids)
def get_batch(batch_size, block_size, device): max_start = len(data) - block_size - 1 starts = torch.randint(0, max_start, (batch_size,)) x = torch.stack([data[i : i + block_size] for i in starts]).to(device) y = torch.stack([data[i + 1 : i + block_size + 1] for i in starts]).to(device) return x, y
@dataclassclass GPTConfig: vocab_size: int block_size: int = 64 n_layer: int = 2 n_head: int = 2 n_embd: int = 64 dropout: float = 0.1
class CausalSelfAttention(nn.Module): def __init__(self, config): super().__init__() assert config.n_embd % config.n_head == 0 self.n_head = config.n_head self.head_size = config.n_embd // config.n_head self.qkv = nn.Linear(config.n_embd, 3 * config.n_embd) self.proj = nn.Linear(config.n_embd, config.n_embd) self.dropout = nn.Dropout(config.dropout) mask = torch.tril(torch.ones(config.block_size, config.block_size)) self.register_buffer("mask", mask.view(1, 1, config.block_size, config.block_size))
def forward(self, x): B, T, C = x.shape q, k, v = self.qkv(x).split(C, dim=2) q = q.view(B, T, self.n_head, self.head_size).transpose(1, 2) k = k.view(B, T, self.n_head, self.head_size).transpose(1, 2) v = v.view(B, T, self.n_head, self.head_size).transpose(1, 2)
scores = q @ k.transpose(-2, -1) / math.sqrt(self.head_size) scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf")) weights = F.softmax(scores, dim=-1) weights = self.dropout(weights) out = weights @ v out = out.transpose(1, 2).contiguous().view(B, T, C) return self.proj(out)
class Block(nn.Module): def __init__(self, config): super().__init__() self.ln1 = nn.LayerNorm(config.n_embd) self.attn = CausalSelfAttention(config) self.ln2 = nn.LayerNorm(config.n_embd) self.mlp = nn.Sequential( nn.Linear(config.n_embd, 4 * config.n_embd), nn.GELU(), nn.Linear(4 * config.n_embd, config.n_embd), nn.Dropout(config.dropout), )
def forward(self, x): x = x + self.attn(self.ln1(x)) x = x + self.mlp(self.ln2(x)) return x
class MiniGPT(nn.Module): def __init__(self, config): super().__init__() self.config = config self.token_emb = nn.Embedding(config.vocab_size, config.n_embd) self.pos_emb = nn.Embedding(config.block_size, config.n_embd) self.blocks = nn.ModuleList([Block(config) for _ in range(config.n_layer)]) self.ln_f = nn.LayerNorm(config.n_embd) self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
def forward(self, idx, targets=None): B, T = idx.shape positions = torch.arange(T, device=idx.device) x = self.token_emb(idx) + self.pos_emb(positions) for block in self.blocks: x = block(x) x = self.ln_f(x) logits = self.lm_head(x)
loss = None if targets is not None: loss = F.cross_entropy(logits.view(B * T, -1), targets.view(B * T)) return logits, loss
@torch.no_grad() def generate(self, idx, max_new_tokens): for _ in range(max_new_tokens): idx_cond = idx[:, -self.config.block_size :] logits, _ = self(idx_cond) logits = logits[:, -1, :] probs = F.softmax(logits, dim=-1) next_id = torch.multinomial(probs, num_samples=1) idx = torch.cat([idx, next_id], dim=1) return idx
def main(): device = "cuda" if torch.cuda.is_available() else "cpu" torch.manual_seed(42)
config = GPTConfig(vocab_size=len(chars)) model = MiniGPT(config).to(device) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
steps = 500 if device == "cuda" else 120 batch_size = 64 if device == "cuda" else 16 print("device:", device) print("cuda_name:", torch.cuda.get_device_name(0) if device == "cuda" else "not available") print("parameters:", sum(p.numel() for p in model.parameters()))
start_time = time.time() for step in range(1, steps + 1): x, y = get_batch(batch_size, config.block_size, device) logits, loss = model(x, y) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step()
if step == 1 or step % 50 == 0: elapsed = time.time() - start_time print(f"step {step:04d} | loss {loss.item():.4f} | elapsed {elapsed:.1f}s")
checkpoint = { "model_state": model.state_dict(), "config": config.__dict__, "stoi": stoi, "itos": itos, } torch.save(checkpoint, "mini_gpt2_checkpoint.pt") print("checkpoint: mini_gpt2_checkpoint.pt")
prompt = torch.tensor([[stoi["T"]]], dtype=torch.long, device=device) generated = model.generate(prompt, max_new_tokens=180)[0].cpu() print("\n--- sample ---") print(decode(generated))
if __name__ == "__main__": main()Run it:
python mini_gpt2_train.py | tee gpu_train_log.txtExpected output:
device: cudacuda_name: Tesla T4parameters: about 100kstep 0001 | loss 3.5832 | elapsed 0.2sstep 0050 | loss 3.1120 | elapsed 1.6s...checkpoint: mini_gpt2_checkpoint.pt--- sample ---To build a language model...The generated text does not need to be elegant. If the GPU log shows decreasing loss, a saved checkpoint, and generated characters, the training loop works.
5. Line-by-Line Explanation
Section titled “5. Line-by-Line Explanation”Text and tokenizer
Section titled “Text and tokenizer”chars = sorted(set(text))stoi = {ch: i for i, ch in enumerate(chars)}itos = {i: ch for ch, i in stoi.items()}data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long)This is a character-level tokenizer. Real GPT-2 uses BPE tokens, but characters keep the lab dependency-free and focus attention on the model.
Next-token batch
Section titled “Next-token batch”x = data[i : i + block_size]y = data[i + 1 : i + block_size + 1]x is the input and y is the answer. The model reads token 0 through token T-1 and predicts token 1 through token T.
Config object
Section titled “Config object”class GPTConfig: vocab_size: int block_size: int = 64 n_layer: int = 2 n_head: int = 2 n_embd: int = 64These values control model size: context length, number of blocks, attention heads, and embedding width.
QKV and multi-head attention
Section titled “QKV and multi-head attention”q, k, v = self.qkv(x).split(C, dim=2)q = q.view(B, T, self.n_head, self.head_size).transpose(1, 2)x has shape [B, T, C]. After the split and reshape, each head receives its own [B, head, T, head_size] view.
Causal mask
Section titled “Causal mask”mask = torch.tril(torch.ones(config.block_size, config.block_size))scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf"))The lower-triangular mask prevents each position from seeing future tokens. This is the core rule behind next-token prediction in decoder-only models.
Transformer block
Section titled “Transformer block”x = x + self.attn(self.ln1(x))x = x + self.mlp(self.ln2(x))Attention mixes context. The MLP transforms each position. Residual connections keep information and gradients moving.
Embeddings
Section titled “Embeddings”x = self.token_emb(idx) + self.pos_emb(positions)Token embedding says what the token is. Position embedding says where it appears.
Logits and loss
Section titled “Logits and loss”logits = self.lm_head(x)loss = F.cross_entropy(logits.view(B * T, -1), targets.view(B * T))logits has shape [B, T, vocab_size]. Cross entropy rewards the model for assigning higher probability to the true next token.
Training loop
Section titled “Training loop”logits, loss = model(x, y)optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()This is the core loop: forward, clear gradients, backpropagate, update parameters.
Checkpoint
Section titled “Checkpoint”torch.save(checkpoint, "mini_gpt2_checkpoint.pt")A real training run must leave a recoverable artifact. This tiny checkpoint is not valuable as a model product, but it proves that the run produced weights, not just terminal text.
Generate
Section titled “Generate”logits = logits[:, -1, :]probs = F.softmax(logits, dim=-1)next_id = torch.multinomial(probs, num_samples=1)Generation reads the last position, samples the next token, appends it, and repeats.
6. GPU Training Runbook
Section titled “6. GPU Training Runbook”Kaggle or Colab
Section titled “Kaggle or Colab”- Create a notebook.
- Enable GPU in settings.
- Run the PyTorch check and confirm
cuda available: True. - Create
mini_gpt2_train.py. - Run
python mini_gpt2_train.py | tee gpu_train_log.txt. - Download or copy back
gpu_train_log.txtandmini_gpt2_checkpoint.pt. - Save hardware info, loss lines, checkpoint line, and the generated sample.
AutoDL or RunPod
Section titled “AutoDL or RunPod”- Choose a PyTorch image.
- Choose a 16GB or 24GB VRAM machine.
- Open JupyterLab or SSH terminal.
- Run the PyTorch check.
- Save the script and train.
- Copy back
gpu_train_log.txtandmini_gpt2_checkpoint.pt. - Stop the instance immediately after the run and confirm billing has stopped.
CPU Smoke Test Is Not the Final Pass
Section titled “CPU Smoke Test Is Not the Final Pass”CPU is useful for checking that the file exists, imports work, and the script can enter the training loop. It is not enough for this lab’s final pass. If the only evidence says device: cpu, mark the lab as “smoke test complete, GPU run still pending.”
Common Issues
Section titled “Common Issues”| Symptom | Likely cause | Fix |
|---|---|---|
cuda available: False | GPU disabled or wrong image | Enable accelerator or rebuild with CUDA/PyTorch image |
CUDA out of memory | Batch, context, or model too large | Reduce batch_size, then block_size or n_embd |
| Loss does not decrease | Too few steps, data too short, bad LR | Run 500 steps before judging trend |
| Generated text is messy | Model and data are tiny | Normal for this lab; mechanism is the goal |
| Billing continues | Instance still running | Stop the instance and verify in the console |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Platform Choice
- Kaggle/Colab/Lightning/AutoDL/RunPod
- Hardware Info
- torch version, CUDA status, GPU model
- Training Log
- device cuda plus at least three lines with step, loss, elapsed
- Checkpoint
- mini_gpt2_checkpoint.pt copied back or preserved
- Code Location
- identify embedding, attention, loss, checkpoint, and generate in the script
- Cost Record
- if rented, record runtime and cost, then confirm shutdown
Pass Check
Section titled “Pass Check”You pass when mini_gpt2_train.py completes one GPU run with device: cuda, gpu_train_log.txt and mini_gpt2_checkpoint.pt are saved, and you can explain how input tokens pass through embedding, attention, MLP, lm head, checkpointing, and cross entropy to learn next-token prediction. A CPU run counts only as a smoke test, even if it completes.
Check reasoning and explanation
- The goal is not beautiful generated text. The goal is to run the full path.
- A passing log includes
device: cuda, hardware info, parameter count, several loss lines, checkpoint path, and one sample. - If you rented a GPU, your evidence must state that the instance was stopped.
- CPU completion is still useful, but it is not the final pass for this lesson.