7.8.2 Project: Vertical Domain Fine-tuning
Learning Objectives
Section titled “Learning Objectives”- Learn how to narrow “domain fine-tuning” into an executable project
- Learn how to organize raw knowledge into SFT data and an evaluation set
- Learn how to build a truly convincing baseline comparison
- Learn how to present this project as a portfolio-quality page
Why must you narrow the project topic first?
Section titled “Why must you narrow the project topic first?”Broad topics are almost impossible to complete
Section titled “Broad topics are almost impossible to complete”For example:
- Build an industry expert LLM
This kind of topic is usually too broad, and it is hard to define clearly:
- What is the input?
- What is the output?
- What counts as a correct answer?
Topics that are better suited for a portfolio
Section titled “Topics that are better suited for a portfolio”For example:
E-commerce after-sales policy assistant: focus on four types of questions — refunds, address changes, invoices, and after-sales procedures.
This topic is good because:
- The scope is narrow
- The semantics are stable
- The evaluation criteria are easy to design
What does the smallest portfolio-ready fine-tuning loop look like?
Section titled “What does the smallest portfolio-ready fine-tuning loop look like?”- Define the task boundary
- Organize knowledge and dialogue samples
- Build a baseline
- Prepare SFT data
- Build an evaluation set
- Train and compare before/after results
As long as these 6 steps are clear, your project will already be very convincing.
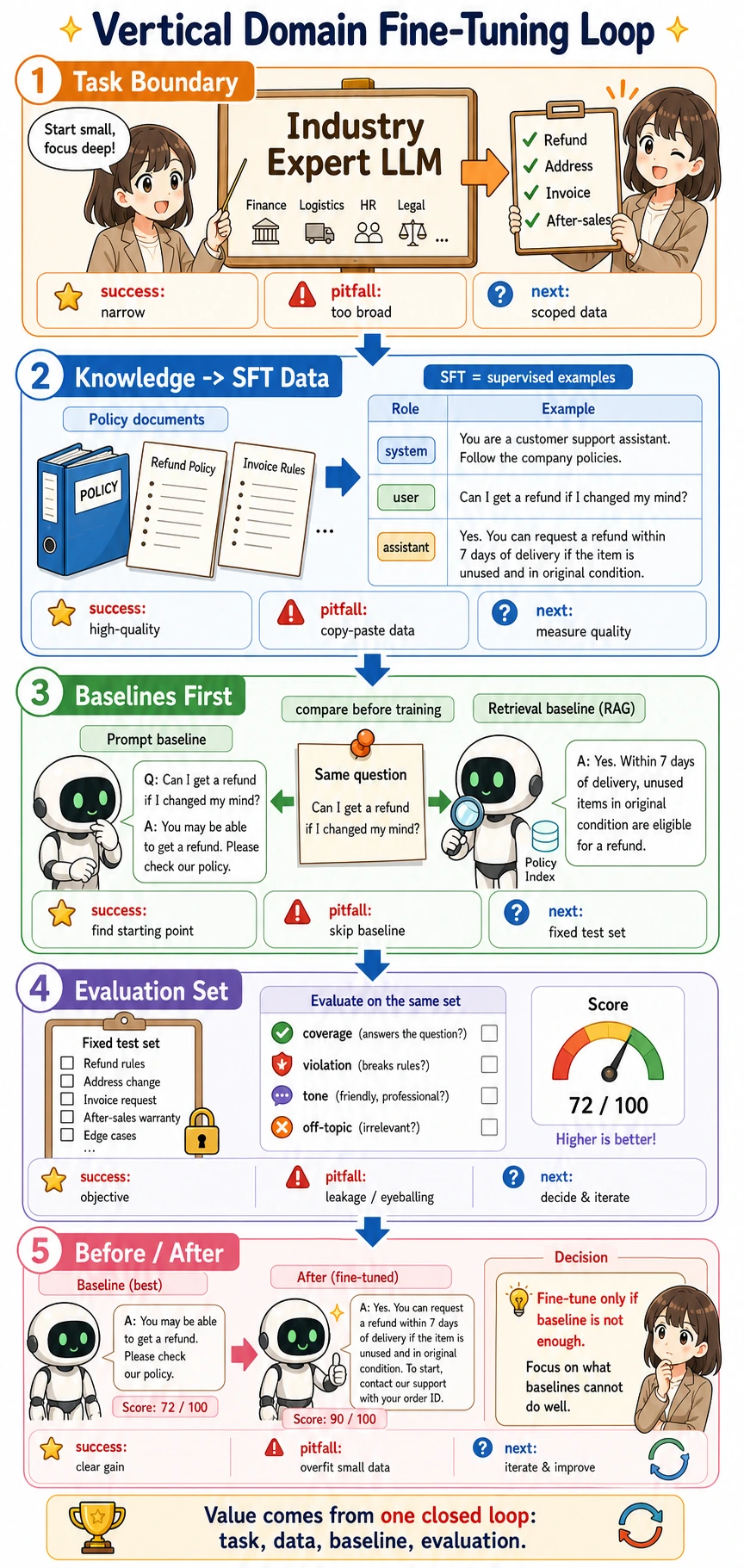
Recommended implementation order
Section titled “Recommended implementation order”For beginners, a more reliable order is usually:
- First narrow down the topic
- Then build a Prompt / retrieval baseline
- Then organize SFT data
- Finally fine-tune and compare before/after results
That way, the project feels like “fine-tuning after judgment,” rather than “fine-tuning for the sake of fine-tuning.”
Key project words before you read the code
Section titled “Key project words before you read the code”| Term | Beginner-friendly meaning | Why it matters here |
|---|---|---|
| LLM | Large Language Model, a model that predicts and generates text token by token | The project is about changing how an LLM behaves on a narrow domain task |
| Prompt | The instruction and context you send to the model at inference time | It is the first baseline because it costs less than training |
| RAG | Retrieval-Augmented Generation, which retrieves external documents before answering | It is useful when the model lacks current or private knowledge |
| Fine-tuning | Additional training on task-specific examples | It is useful when the model must follow a stable style, format, or decision pattern |
| SFT | Supervised Fine-Tuning, training with input/output examples written by humans or curated from reliable data | It teaches the model what a good answer should look like |
| Baseline | The simplest comparison system you build before the advanced method | It prevents you from claiming improvement without evidence |
| Evaluation set | A fixed set of test questions that you do not train on | It tells you whether the new method really improves unseen cases |
| Coverage | How many required policy points are included in the answer | It turns “looks good” into a more measurable score |
Let’s first look at a more complete data and baseline example
Section titled “Let’s first look at a more complete data and baseline example”The example below shows:
- Raw records
- SFT samples
- Two baselines
- Evaluation rules
The code uses only the Python standard library. Save it as domain_finetune_demo.py and run python domain_finetune_demo.py.
raw_records = [ { "intent": "refund_unshipped", "question": "My order hasn’t shipped yet. Can I refund it directly?", "policy_points": ["Unshipped orders can be refunded directly", "Refunds are returned to the original payment method", "It usually takes 3 to 7 business days"], "evaluation_keywords": [["not shipped", "unshipped"], ["original payment method", "payment method"], ["3 to 7", "business days"]], "answer": "Yes. If the order has not shipped yet, you can request a refund directly. The payment will be returned to the original payment method, and it usually arrives within 3 to 7 business days.", }, { "intent": "change_address", "question": "I entered the wrong shipping address. Can I still change it?", "policy_points": ["Address can be changed before warehouse dispatch", "If already dispatched, contact human support"], "evaluation_keywords": [["not been dispatched", "before warehouse dispatch"], ["human support", "already dispatched"]], "answer": "If the order has not been dispatched from the warehouse yet, you can change the address on the order details page. If it has already been dispatched, please contact human support.", }, { "intent": "invoice", "question": "When can I request an invoice?", "policy_points": ["Can be requested after the order is completed", "E-invoice will be sent to email"], "evaluation_keywords": [["order is completed", "after the order"], ["e-invoice", "email"]], "answer": "After the order is completed, you can request an invoice from the invoice center. The e-invoice will be sent to your registered email address.", },]
def build_sft_record(row): system = "You are an e-commerce after-sales policy assistant. Please answer user questions politely, accurately, and in accordance with platform rules." return { "messages": [ {"role": "system", "content": system}, {"role": "user", "content": row["question"]}, {"role": "assistant", "content": row["answer"]}, ], "intent": row["intent"], "policy_points": row["policy_points"], }
def generic_baseline(question): if "refund" in question or "refund" in question.lower(): return "In general, you can request a refund, depending on the order status." if "address" in question: return "It is recommended to contact customer support as soon as possible to handle the address issue." if "invoice" in question: return "Invoices are usually available upon request. Please check the page instructions for details." return "Please contact platform customer support for help."
def retrieval_baseline(question, records): best = max(records, key=lambda row: overlap(question, row["question"])) return best["answer"]
def tokenize(text): punctuation = ".,?!'\";:()[]{}" words = [word.strip(punctuation).lower() for word in text.split()] return {word for word in words if word}
def overlap(a, b): return len(tokenize(a) & tokenize(b))
def coverage(answer, required_keyword_groups): normalized_answer = answer.lower() matched = [ group for group in required_keyword_groups if any(keyword.lower() in normalized_answer for keyword in group) ] return round(len(matched) / len(required_keyword_groups), 3)
sft_dataset = [build_sft_record(row) for row in raw_records]sample = raw_records[0]
generic_answer = generic_baseline(sample["question"])retrieval_answer = retrieval_baseline(sample["question"], raw_records)
print("question:", sample["question"])print("generic :", generic_answer, "coverage=", coverage(generic_answer, sample["evaluation_keywords"]))print("retrieval:", retrieval_answer, "coverage=", coverage(retrieval_answer, sample["evaluation_keywords"]))print("sft_sample:", sft_dataset[0])Expected output:
question: My order hasn’t shipped yet. Can I refund it directly?generic : In general, you can request a refund, depending on the order status. coverage= 0.0retrieval: Yes. If the order has not shipped yet, you can request a refund directly. The payment will be returned to the original payment method, and it usually arrives within 3 to 7 business days. coverage= 1.0sft_sample: {'messages': [{'role': 'system', 'content': 'You are an e-commerce after-sales policy assistant. Please answer user questions politely, accurately, and in accordance with platform rules.'}, {'role': 'user', 'content': 'My order hasn’t shipped yet. Can I refund it directly?'}, {'role': 'assistant', 'content': 'Yes. If the order has not shipped yet, you can request a refund directly. The payment will be returned to the original payment method, and it usually arrives within 3 to 7 business days.'}], 'intent': 'refund_unshipped', 'policy_points': ['Unshipped orders can be refunded directly', 'Refunds are returned to the original payment method', 'It usually takes 3 to 7 business days']}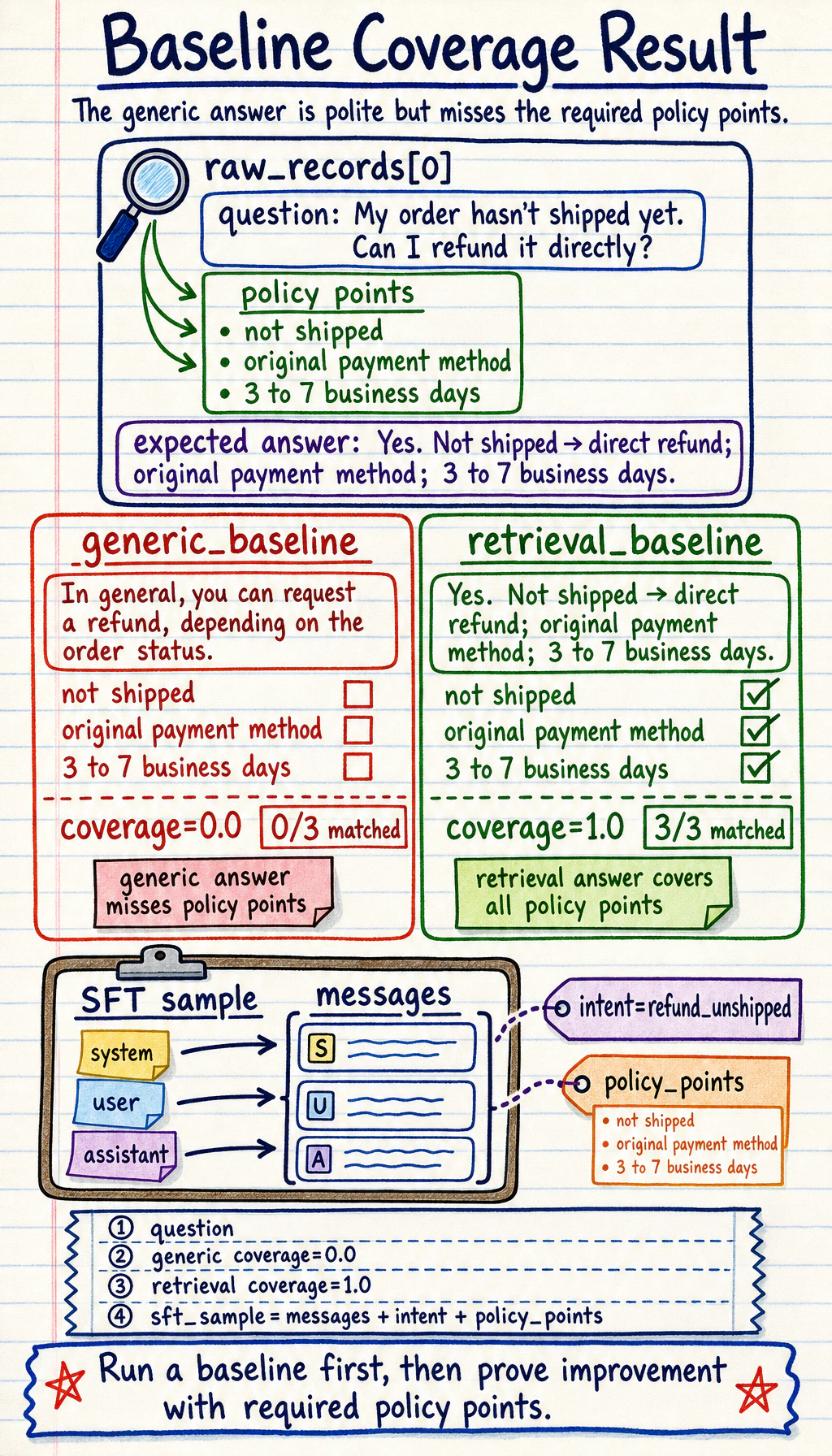
The point is not that this tiny retrieval baseline is production-ready. The point is to make the comparison visible: a generic answer sounds polite but misses required policy details, while a domain-aware answer can be checked against a fixed list of required points.
Why is this example more valuable than a pure “project plan” object?
Section titled “Why is this example more valuable than a pure “project plan” object?”Because it already shows the four most important things in the project:
- What the raw data looks like
- What the SFT samples look like
- What the baseline results are
- What the evaluation rules are
This is already very close to the core structure of a real fine-tuning project.
Why should you build two baselines first?
Section titled “Why should you build two baselines first?”At minimum, it is recommended to compare:
- Pure Prompt / generic response
- Retrieval or simple domain matching
- The fine-tuned system
Otherwise, it will be hard to explain later:
- What exactly did fine-tuning improve?
If retrieval already works, when is fine-tuning still worth it?
Section titled “If retrieval already works, when is fine-tuning still worth it?”Retrieval answers the question “which knowledge should the model see?” Fine-tuning answers a different question: “how should the model behave after seeing the input?” If retrieval already finds the correct policy text, fine-tuning may still be valuable when the assistant must always follow a fixed tone, classify intents consistently, output a strict JSON schema, or apply a repeated reasoning pattern.
| Situation | Better first choice | Reason |
|---|---|---|
| The answer needs private or frequently changing knowledge | RAG | Updating documents is safer than retraining the model |
| The answer must follow a stable style or structure | Fine-tuning | The model learns the repeated output pattern |
| The task definition is unclear | Rewrite the task and Prompt | Training on unclear examples only preserves confusion |
| The output must be parseable by code | Prompt + schema first, then fine-tuning if still unstable | Schema constraints reveal whether the problem is wording or model behavior |
| The baseline already passes evaluation | Keep the simpler method | A simpler reliable system is usually easier to maintain |
The most important evaluation for a fine-tuning project is not just “it looks like an expert”
Section titled “The most important evaluation for a fine-tuning project is not just “it looks like an expert””Structured evaluation points
Section titled “Structured evaluation points”At minimum, include:
- Whether key policy points are covered
- Whether there are any policy violations or false commitments
- Whether the tone is consistent
- Whether the answer is off-topic
A more portfolio-friendly presentation style
Section titled “A more portfolio-friendly presentation style”The best format is:
- The same set of questions
- Baseline answers
- Fine-tuned answers
- Line-by-line explanation of the differences
Failure cases are very important
Section titled “Failure cases are very important”For example:
- Easily hallucinating policies
- Getting details wrong
- Inconsistent tone
These are more realistic than showing only successful cases.
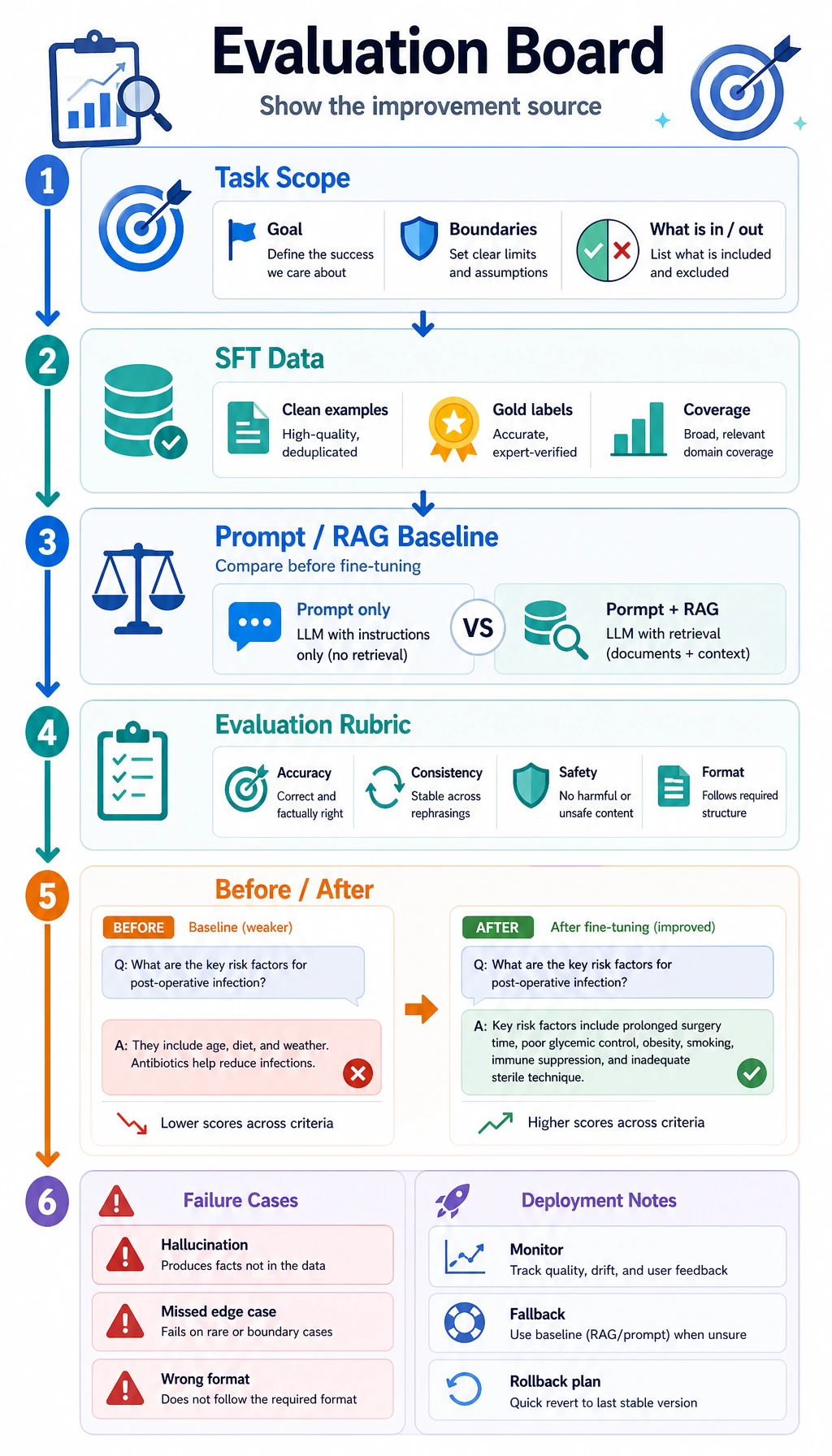
How do you turn this into a portfolio-quality page?
Section titled “How do you turn this into a portfolio-quality page?”Recommended page structure
Section titled “Recommended page structure”- Task boundary
- Data construction method
- Baseline comparison
- SFT sample examples
- Before / after
- Failure cases
A very useful extra point
Section titled “A very useful extra point”Expose a clear rule such as “policy-point coverage rate.” It makes the project feel solid and well-grounded, rather than based only on subjective judgment.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Scope
- narrow domain behavior and target users
- Data
- examples, label rules, and quality checks
- Baseline
- prompt/RAG result before fine-tuning
- Eval
- domain cases, failure samples, and safety cases
- Portfolio
- decision table plus reproducible run instructions
The most common pitfalls
Section titled “The most common pitfalls”Starting with a broad topic
Section titled “Starting with a broad topic”This causes both evaluation and data to drift apart.
No baseline
Section titled “No baseline”Without a comparison, a fine-tuning project is almost impossible to defend.
Showing only model training, not task judgment
Section titled “Showing only model training, not task judgment”What to include when delivering the project
Section titled “What to include when delivering the project”- A task boundary table
- A baseline comparison table
- A set of before / after Q&A samples
- A set of failure cases with root-cause analysis
- A short explanation of “why fine-tuning is worth it here instead of just using RAG / Prompt”
What really makes the project valuable is:
- Topic definition
- Data organization
- Evaluation design
Summary
Section titled “Summary”The most important idea in this section is to establish a portfolio-level judgment:
The real value of a vertical domain fine-tuning project is not “I fine-tuned a model,” but whether you can explain the task boundary, SFT data, baselines, evaluation rules, and before/after comparison as one clear closed loop.
As long as that loop is clear, this project is very suitable for showcasing.
Suggested version roadmap
Section titled “Suggested version roadmap”| Version | Goal | Key Deliverable |
|---|---|---|
| Basic | Run through the smallest closed loop | Can accept input, process it, output results, and keep a set of examples |
| Standard | Become a presentable project | Add configuration, logs, error handling, README, and screenshots |
| Challenge | Approach portfolio quality | Add evaluation, comparison experiments, failure sample analysis, and a next-step roadmap |
It is recommended to finish the basic version first. Do not try to make it large and complete from the start. With each version upgrade, document in the README what new capability was added, how it was verified, and what problems remain.
Exercises
Section titled “Exercises”- Add 5 more samples to the raw data so the four intent categories are more balanced.
- Think about this: if the Retrieval baseline is already very strong, when is fine-tuning still worth doing?
- Why is “policy-point coverage rate” more suitable for project evaluation than “it feels more human-like”?
- If you turn this into a portfolio project, which 4 before/after examples are most worth showing?
Project reference and review notes
- Add samples where each intent has enough variety, including short, long, ambiguous, and noisy wording. Balance is about coverage, not just equal counts.
- Fine-tuning is still worth considering when you need stable style, domain-specific phrasing, compact behavior, repeated classification patterns, or lower per-request prompt complexity.
- Policy-point coverage rate measures whether required content is present. “Feels human-like” is subjective and can reward fluent but incomplete answers.
- Show examples where the improved system fixes clear failures: wrong intent, missing policy point, bad refusal, and unstable formatting. Each before/after should include the evaluation reason.