8.4.6 Long Context, RAG, and Memory Decision
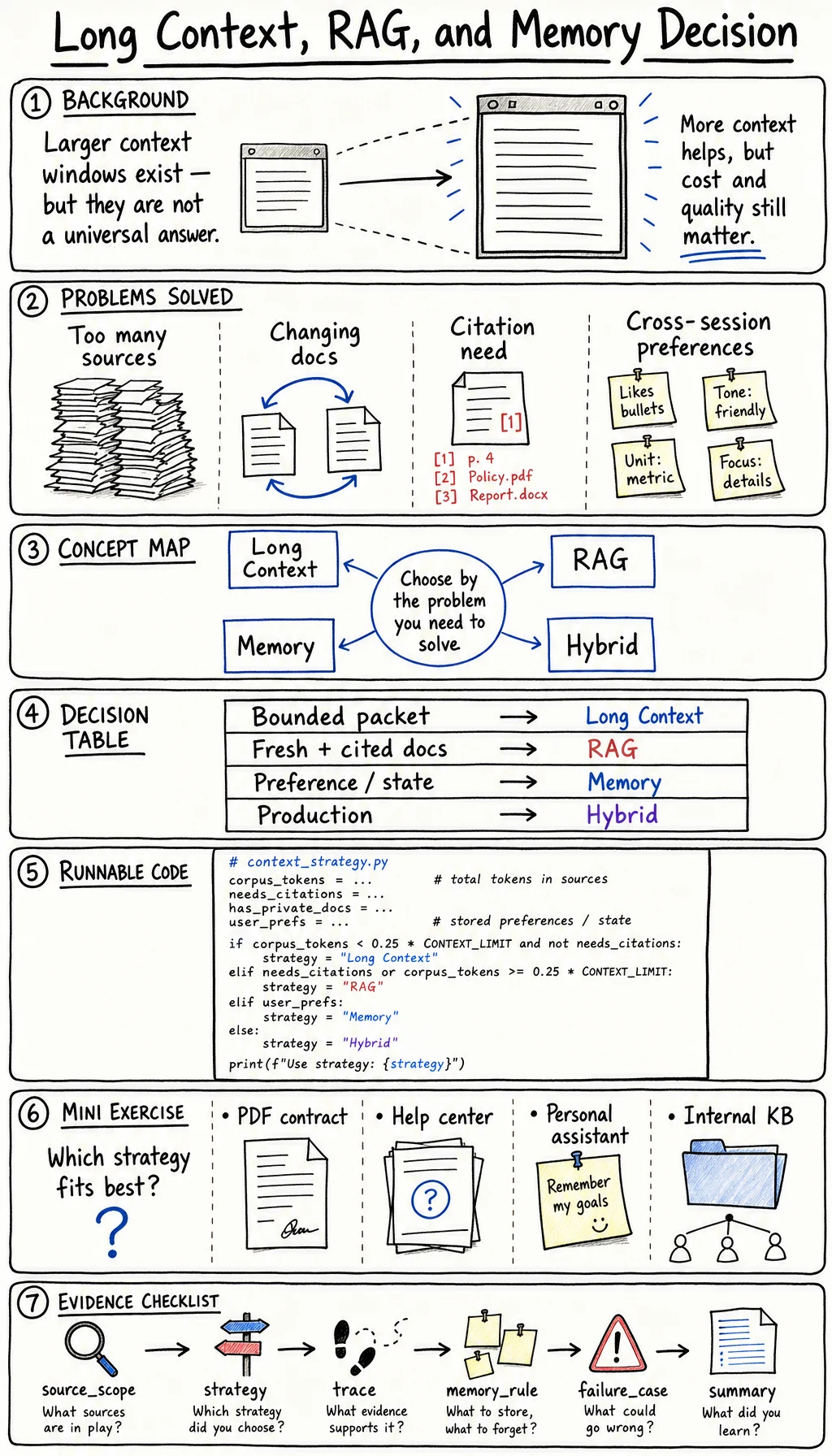
Long-context models, RAG systems, and agent memory all solve the same pain from different angles: the model needs the right information at the right time. The mistake is treating one technique as a religion.
This lesson gives you a decision rule. It is especially useful now that models such as GPT-4.1 and Claude with 1M context made very large context windows practical for some workflows. A larger window does not remove the need for retrieval, citations, privacy controls, or memory hygiene.
Why This Appeared
Section titled “Why This Appeared”Before long-context models improved, RAG was often the default answer for “the model needs more documents.” That worked, but it introduced chunking, embedding, indexing, ranking, citation, and freshness problems.
Long context changes the trade-off:
- You can paste more source material directly.
- You can reduce retrieval complexity for small or bounded corpora.
- You can inspect the full prompt more easily in some workflows.
But long context also creates new problems:
- More tokens can mean higher cost and latency.
- Important evidence can be buried.
- Repeated user preferences do not belong in every prompt.
- Private or regulated documents still need access control.
Memory adds a third axis: what should persist across sessions?
Concept Map
Section titled “Concept Map”| Technique | What it holds | Best at | Main risk |
|---|---|---|---|
| Long context | A large prompt with many files or passages | One-time deep reading, code review, legal/doc comparison, transcript analysis | Cost, latency, attention dilution |
| RAG | Retrieved chunks from a searchable corpus | Fresh knowledge, citations, large libraries, per-user access control | Bad chunking, wrong retrieval, stale index |
| Memory | Persistent facts, preferences, and state | User/project continuity across sessions | Stale or sensitive memory, hidden assumptions |
| Hybrid | Context + retrieval + memory with rules | Production assistants and agents | Harder debugging unless traced |
Decision Table
Section titled “Decision Table”| If your task needs… | Prefer | Why |
|---|---|---|
| One bounded packet, under the model limit | Long context | Fewer moving parts and easier trace |
| Many documents, frequent updates, or citations | RAG | Search, source metadata, and freshness matter |
| User preference or project state across sessions | Memory | It should persist without pasting every time |
| Private documents with per-user permissions | RAG plus access filters | Retrieval must respect authorization |
| A complex agent that works over weeks | Hybrid | Memory tracks state; RAG finds evidence; context carries current task |
Runnable Lab: Choose a Context Strategy
Section titled “Runnable Lab: Choose a Context Strategy”Create context_strategy.py and run it with Python 3.10 or later.
import jsonfrom pathlib import Path
project = { "corpus_tokens": 180_000, "changes_weekly": True, "needs_citations": True, "has_user_preferences": True, "has_private_docs": True, "model_context_limit": 1_000_000,}
def choose_strategy(info): can_fit = info["corpus_tokens"] < info["model_context_limit"] * 0.6 if info["needs_citations"] or info["changes_weekly"] or info["has_private_docs"]: base = "RAG" elif can_fit: base = "long_context" else: base = "RAG"
memory = "project_memory" if info["has_user_preferences"] else "no_persistent_memory"
if base == "RAG" and can_fit: pattern = "hybrid: retrieve first, then pack the most useful evidence into context" elif base == "long_context": pattern = "long context: pack bounded sources and keep a prompt manifest" else: pattern = "RAG: index corpus, retrieve with metadata, cite sources"
return {"base": base, "memory": memory, "pattern": pattern}
plan = { "strategy": choose_strategy(project), "evidence_to_keep": [ "source manifest", "retrieved chunks or packed files", "citation table", "latency and cost note", "memory write/delete rule", ],}
Path("context_strategy.json").write_text(json.dumps(plan, indent=2), encoding="utf-8")print(json.dumps(plan, indent=2))Expected output:
{ "strategy": { "base": "RAG", "memory": "project_memory", "pattern": "hybrid: retrieve first, then pack the most useful evidence into context" }, "evidence_to_keep": [ "source manifest", "retrieved chunks or packed files", "citation table", "latency and cost note", "memory write/delete rule" ]}Read the Code Line by Line
Section titled “Read the Code Line by Line”corpus_tokens and model_context_limit ask whether the source material can fit. Fit alone is not enough.
needs_citations, changes_weekly, and has_private_docs push the decision toward RAG because you need source metadata, refresh, and authorization.
has_user_preferences turns on memory. Memory is not a document store; it is a small persistent state layer.
pattern explains the final design. In practice, many strong systems are hybrid: retrieve the best evidence, then use long context to let the model reason over a richer packet.
Mini Exercise
Section titled “Mini Exercise”Change the project values and rerun.
| Scenario | Change | Expected direction |
|---|---|---|
| One PDF contract review | corpus_tokens=80_000, changes_weekly=False, needs_citations=True | Long context or hybrid with citation table |
| Product help center | corpus_tokens=8_000_000, changes_weekly=True | RAG |
| Personal writing assistant | has_user_preferences=True, needs_citations=False | Memory plus prompt context |
| Internal knowledge base | has_private_docs=True | RAG with access filters |
Evidence to Keep
Section titled “Evidence to Keep”Keep this packet whenever you choose a context strategy:
- Source Scope
- what documents or memories are allowed
- Strategy
- long_context, RAG, memory, or hybrid
- Why Not Other
- one rejected option and reason
- Trace
- packed files or retrieved chunks
- Memory Rule
- when memory is written, updated, or deleted
- Failure Case
- one example where the strategy could fail
Small Summary
Section titled “Small Summary”Long context reduces some retrieval plumbing, but it does not replace RAG or memory. Use long context for bounded reading, RAG for searchable and governed evidence, memory for persistent state, and hybrid designs when production work needs all three.
Check reasoning and explanation
You pass this lesson when you can explain why “more context” is not the same as “better evidence,” and when you can choose a strategy based on source size, freshness, citation needs, privacy, latency, and persistence.