7.1.3 Word Embeddings and Semantic Representation
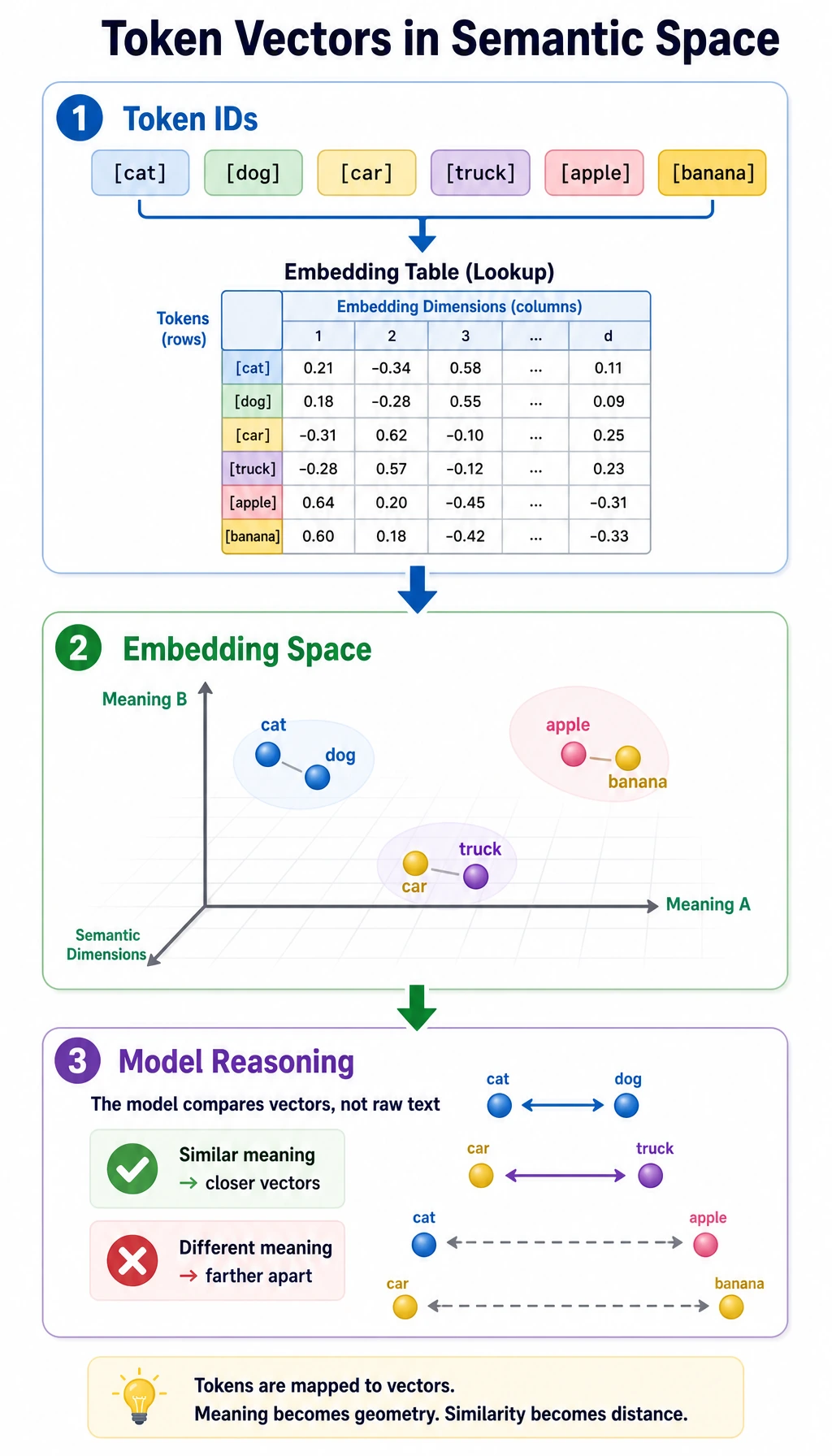
The Mental Model
Section titled “The Mental Model”One-hot IDs can tell words apart, but they cannot tell which words are related. Dense embeddings place tokens in a vector space:
In that space:
- nearby vectors often mean related usage;
- cosine similarity measures direction similarity;
- sentence vectors are usually produced by pooling token vectors;
- contextual models can make the same token move depending on nearby words.
From One-Hot to Dense Vectors
Section titled “From One-Hot to Dense Vectors”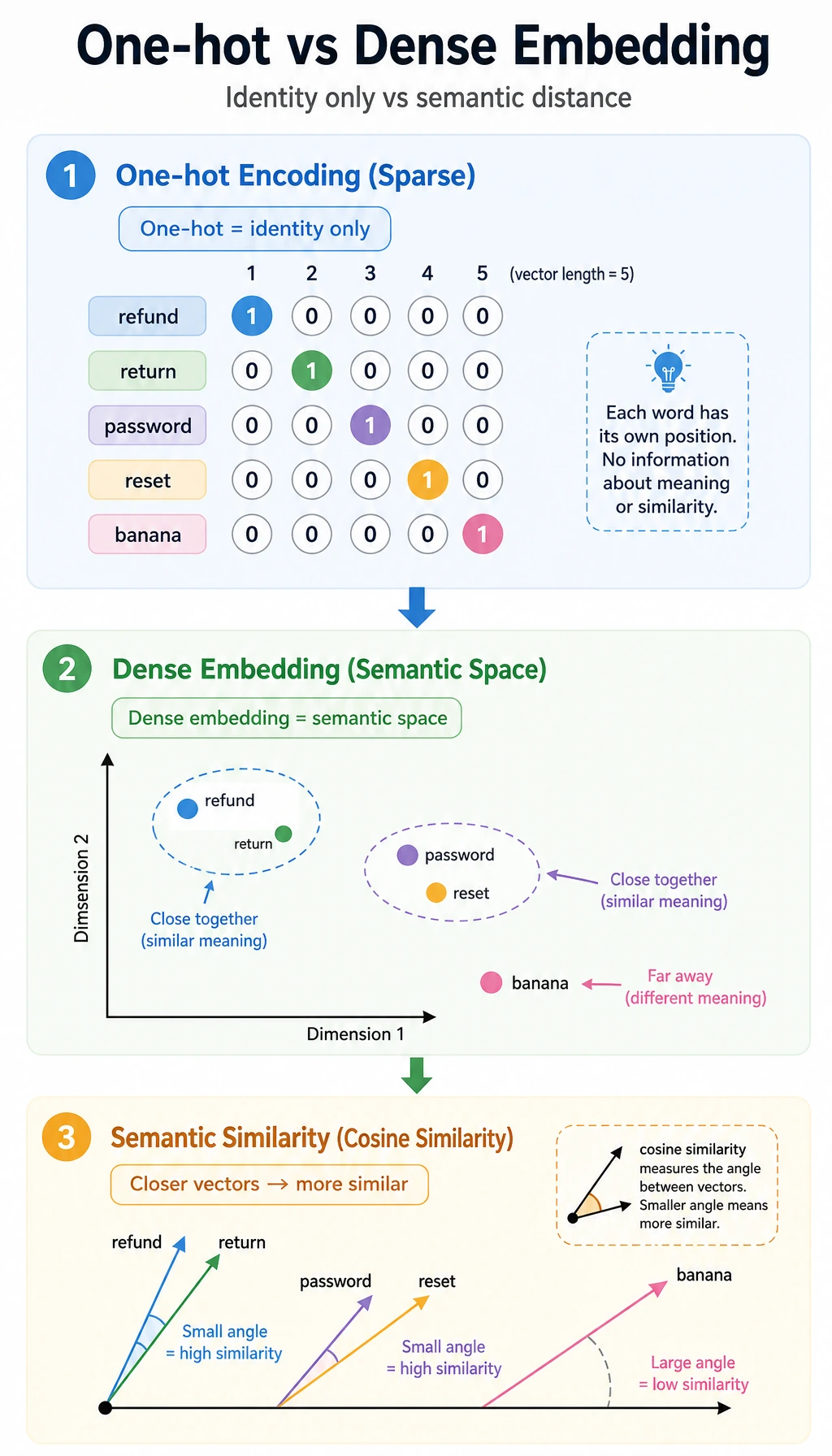
With one-hot vectors, every different word is equally different:
refund -> [1, 0, 0, 0]return -> [0, 1, 0, 0]password -> [0, 0, 1, 0]coupon -> [0, 0, 0, 1]Dense vectors can encode useful geometry:
refund and return -> closepassword and reset -> closerefund and password -> farThis geometry is learned from data, not hand-written. Words that appear in similar contexts tend to get similar vectors.
Lab 1: Compare Word Similarity
Section titled “Lab 1: Compare Word Similarity”Run this tiny embedding table. The numbers are hand-made for learning, but the operations are the same as real embedding retrieval.
from math import sqrt
embeddings = { "refund": [0.90, 0.80, 0.10], "return": [0.88, 0.78, 0.12], "password": [0.10, 0.20, 0.95], "reset": [0.12, 0.18, 0.92], "order": [0.75, 0.70, 0.15], "coupon": [0.05, 0.95, 0.10], "policy": [0.82, 0.74, 0.18],}
def cosine(a, b): dot = sum(x * y for x, y in zip(a, b)) norm_a = sqrt(sum(x * x for x in a)) norm_b = sqrt(sum(x * x for x in b)) return dot / (norm_a * norm_b)
print("refund vs return :", round(cosine(embeddings["refund"], embeddings["return"]), 3))print("refund vs password:", round(cosine(embeddings["refund"], embeddings["password"]), 3))print("password vs reset :", round(cosine(embeddings["password"], embeddings["reset"]), 3))Expected output:
refund vs return : 1.0refund vs password: 0.293password vs reset : 1.0Interpretation:
- high cosine means similar direction, not identical meaning;
refundandreturnare close because this toy table puts them in the same customer-service region;passwordandresetare close for the same reason;refundandpasswordare far because they serve different intents.
Lab 2: Build a Tiny Semantic Retriever
Section titled “Lab 2: Build a Tiny Semantic Retriever”Now average token vectors to create sentence vectors, then rank three documents for a query.
def mean_embedding(tokens): vectors = [embeddings[token] for token in tokens if token in embeddings] dim = len(vectors[0]) return [sum(vector[i] for vector in vectors) / len(vectors) for i in range(dim)]
query = mean_embedding(["reset", "password"])documents = { "A refund policy": ["refund", "policy"], "B password reset": ["password", "reset"], "C coupon return": ["coupon", "return"],}
ranked = sorted( ( (name, cosine(query, mean_embedding(tokens))) for name, tokens in documents.items() ), key=lambda item: item[1], reverse=True,)
for name, score in ranked: print(f"{name}: {score:.3f}")Expected output:
B password reset: 1.000C coupon return: 0.335A refund policy: 0.333This is the core of vector retrieval:
Real RAG systems use stronger embedding models and vector databases, but the logic is still similarity ranking.
Why Averaging Is Useful but Limited
Section titled “Why Averaging Is Useful but Limited”Mean pooling is easy to understand, but it loses important information:
- word order;
- negation;
- emphasis;
- long-range dependency;
- which token should matter most.
For example, reset password and password reset become identical in the toy retriever. That is acceptable for a first intuition, but not enough for reasoning-heavy tasks.
Contextual Representations
Section titled “Contextual Representations”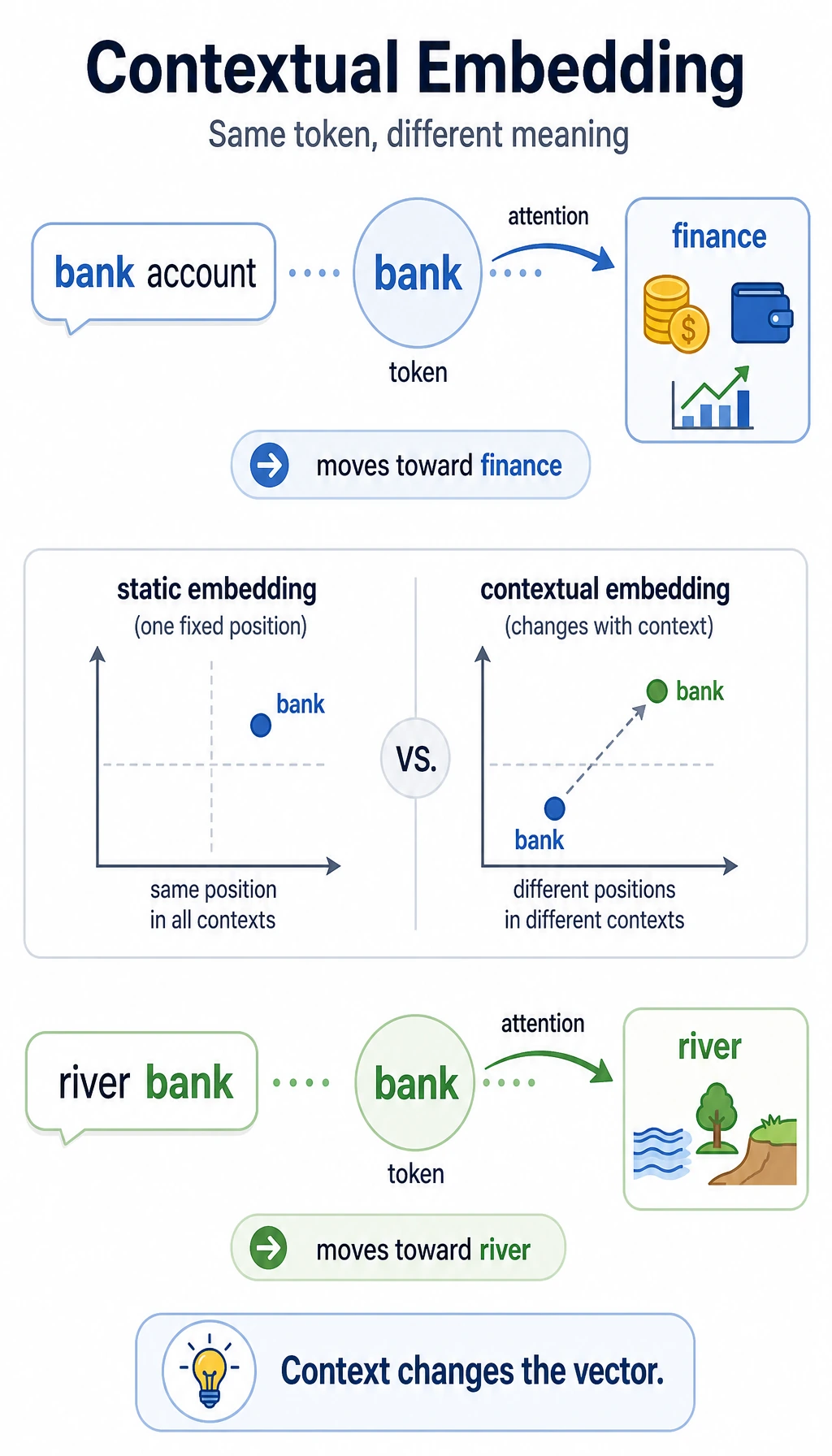
Static embeddings usually give one word one vector. Contextual models make the vector depend on surrounding words:
bank account -> bank moves toward financeriver bank -> bank moves toward geographyRun this small simulation:
base_bank = [0.50, 0.50, 0.50]finance_context = [0.30, -0.10, 0.20]river_context = [-0.20, 0.25, -0.10]
bank_in_finance = [a + b for a, b in zip(base_bank, finance_context)]bank_in_river = [a + b for a, b in zip(base_bank, river_context)]
print("bank in finance:", [round(x, 2) for x in bank_in_finance])print("bank in river :", [round(x, 2) for x in bank_in_river])Expected output:
bank in finance: [0.8, 0.4, 0.7]bank in river : [0.3, 0.75, 0.4]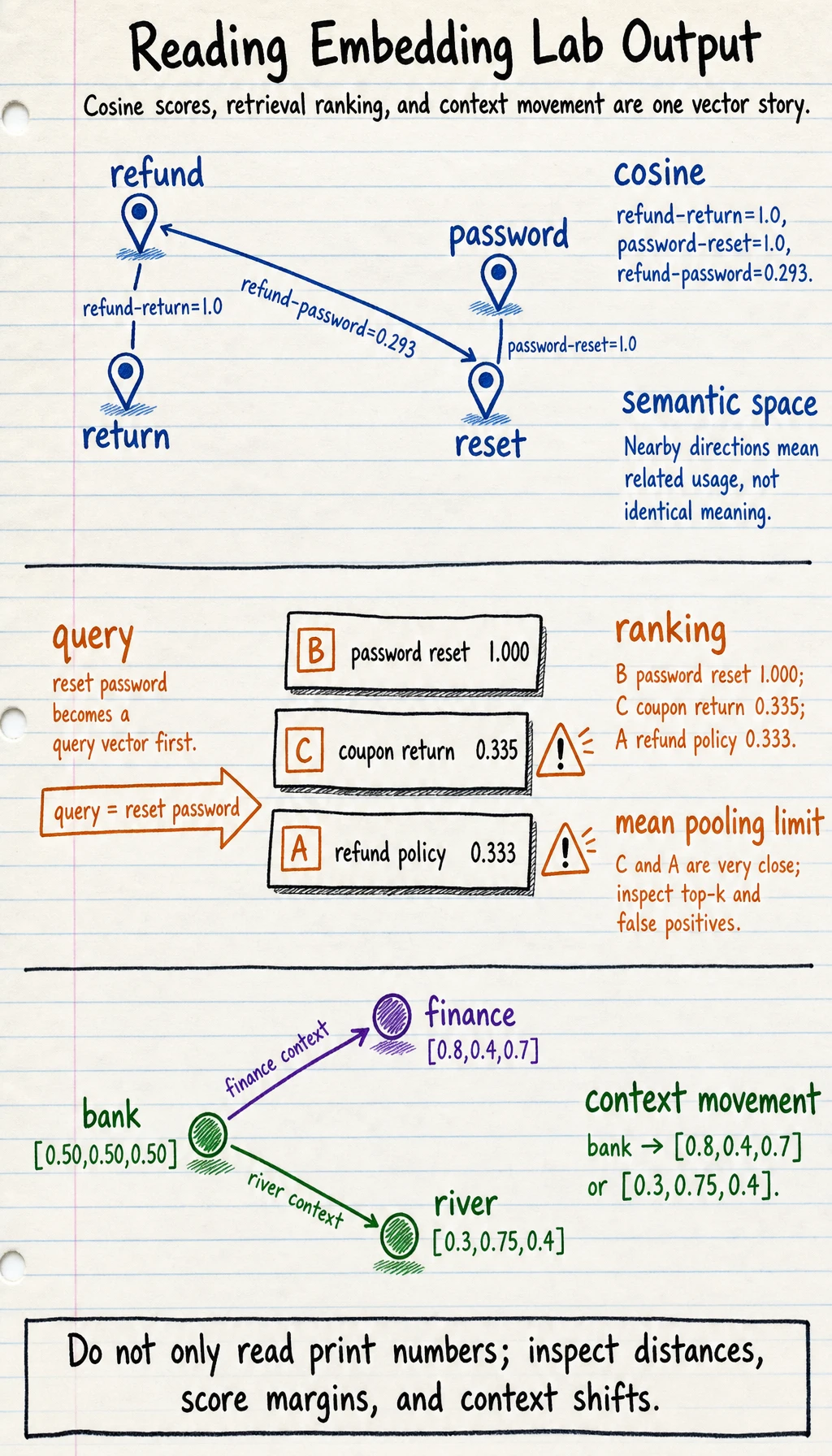
This is not a real Transformer. It is a memory hook: the same token can end up with different representations after context is mixed in.
Project Uses
Section titled “Project Uses”| Use case | What embedding provides | Watch out for |
|---|---|---|
| RAG retrieval | find semantically related chunks | bad chunks or stale metadata still hurt answers |
| FAQ clustering | merge similar questions | close does not always mean duplicate |
| Deduplication | find near-duplicate content | paraphrases and templates can confuse scores |
| Classification | turn text into features | labels and calibration still matter |
| Recommendation | compare users, items, or queries | popularity bias can dominate similarity |
Debugging Checklist
Section titled “Debugging Checklist”- Normalize vectors before cosine similarity if your library does not do it.
- Print top-k scores, not only top-1; a weak margin means retrieval is uncertain.
- Inspect false positives: related terms are not always correct answers.
- Compare static, sentence, and contextual embeddings for the same data.
- For multilingual projects, test cross-language pairs before assuming the embedding model aligns languages well.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Vectors
- at least three text embeddings or toy vectors
- Similarity Check
- closest pair and score
- Retrieval Result
- top match for one query
- Limitation
- averaging or similarity misses context/negation/order
- Next Use
- this becomes retrieval evidence in Chapter 8
Exercises
Section titled “Exercises”- Move
couponcloser topasswordin the toy table. How does retrieval break? - Add a document
D recover accountand create vectors forrecoverandaccount. - Make a query
refund order. Which document should rank first? - Explain why
doctorandhospitalmay be close even though they are not synonyms. - In a RAG project, what evidence would you collect to prove your embedding model is good enough?
Project reference and review notes
- If
couponmoves close topassword, similarity search may retrieve unrelated promotion or return-policy text for account-recovery queries. The failure is not random; it comes from bad geometry. recoverandaccountshould be placed near password/account-support concepts, not near unrelated promotion or return-policy concepts. The added document should become a plausible match for account-recovery queries.refund ordershould rank the refund/order document first if the embedding space captures both commerce and refund intent.doctorandhospitalare close because they often appear in the same domain. Similarity can mean topical relation, not strict synonymy.- Useful evidence includes a fixed query set, expected top-k documents, retrieval scores, known failure cases, latency, cost, and examples where wording changes but intent stays the same.
Summary
Section titled “Summary”Embedding turns discrete token IDs into geometry:
The deeper idea is not the formula. It is that meaning becomes something you can compare, rank, and pass through a neural network.