9.6.6 AutoGen【Elective】
Learning Objectives
Section titled “Learning Objectives”- Understand why AutoGen-style systems emphasize multi-Agent conversation
- Distinguish its core differences from frameworks like LangGraph / CrewAI
- Read a minimal AutoGen-style message loop
- Know when this kind of framework is especially suitable, and when it can get out of control
What is the core intuition behind the AutoGen style?
Section titled “What is the core intuition behind the AutoGen style?”It does not start by drawing a flowchart; it starts by letting the roles “talk”
Section titled “It does not start by drawing a flowchart; it starts by letting the roles “talk””Many frameworks first ask:
- What is the current state?
- Which node should we go to next?
The AutoGen style is more like asking:
- How should the planner assign work to the coder?
- After the coder finishes, how should the result be handed to the reviewer?
- How does the reviewer’s feedback drive the next round?
In other words, it abstracts the system as:
A group of roles that send messages to one another.
A real-life analogy
Section titled “A real-life analogy”You can think of an AutoGen-style system as a group chat for work:
- The product manager states the requirements
- The developer takes the task
- The reviewer gives feedback
- Everyone keeps discussing back and forth
This analogy is very important because it directly determines the kinds of tasks this framework is good at.
Why does this “conversational multi-Agent” style feel so natural?
Section titled “Why does this “conversational multi-Agent” style feel so natural?”Because many complex tasks already have this shape:
- State the requirements first
- Then try to execute
- Then refine based on feedback
For example:
- Code generation and review
- Research report writing
- Troubleshooting and debugging
These tasks are not really a straight line; they are more like multiple rounds of back-and-forth. So the AutoGen-style abstraction is very close to human collaboration intuition.
A minimal AutoGen-style example
Section titled “A minimal AutoGen-style example”First, let’s not use a real framework. Instead, let’s use pure Python to get a feel for “multi-round conversational collaboration.”
messages = []
def send(sender, receiver, content): msg = { "from": sender, "to": receiver, "content": content } messages.append(msg) return msg
send("planner", "coder", "Please implement a function that checks refund eligibility.")send("coder", "reviewer", "I’ve written the first version. Please review it.")send("reviewer", "coder", "Please add logic for cases where learning progress exceeds 20%.")
for msg in messages: print(msg)Expected output:
{'from': 'planner', 'to': 'coder', 'content': 'Please implement a function that checks refund eligibility.'}{'from': 'coder', 'to': 'reviewer', 'content': 'I’ve written the first version. Please review it.'}{'from': 'reviewer', 'to': 'coder', 'content': 'Please add logic for cases where learning progress exceeds 20%.'}Although this code is simple, what is it teaching?
Section titled “Although this code is simple, what is it teaching?”It teaches you that:
- The unit of collaboration is a “message”
- System progress depends on “who said what to whom”
- Multi-Agent systems do not necessarily need an explicit state graph first
This is the core entry point of the AutoGen style.
Why is AutoGen often tied to “code execution” scenarios?
Section titled “Why is AutoGen often tied to “code execution” scenarios?”Because these scenarios naturally fit multi-round feedback
Section titled “Because these scenarios naturally fit multi-round feedback”Code tasks are rarely finished in one round:
- Write the code
- Run it
- Check the error
- Modify it
This matches AutoGen’s message back-and-forth pattern very well.
A minimal “write code -> run -> feedback” example
Section titled “A minimal “write code -> run -> feedback” example”conversation = [ {"from": "planner", "to": "coder", "content": "Please write a status normalization function"}, {"from": "coder", "to": "executor", "content": "def normalize_status(status): return status.strip().lower()"}, {"from": "executor", "to": "reviewer", "content": "Execution result: normalize_status(' OPEN ')=open"}, {"from": "reviewer", "to": "coder", "content": "Please add invalid input handling"}]
for turn in conversation: print(turn)Expected output:
{'from': 'planner', 'to': 'coder', 'content': 'Please write a status normalization function'}{'from': 'coder', 'to': 'executor', 'content': 'def normalize_status(status): return status.strip().lower()'}{'from': 'executor', 'to': 'reviewer', 'content': "Execution result: normalize_status(' OPEN ')=open"}{'from': 'reviewer', 'to': 'coder', 'content': 'Please add invalid input handling'}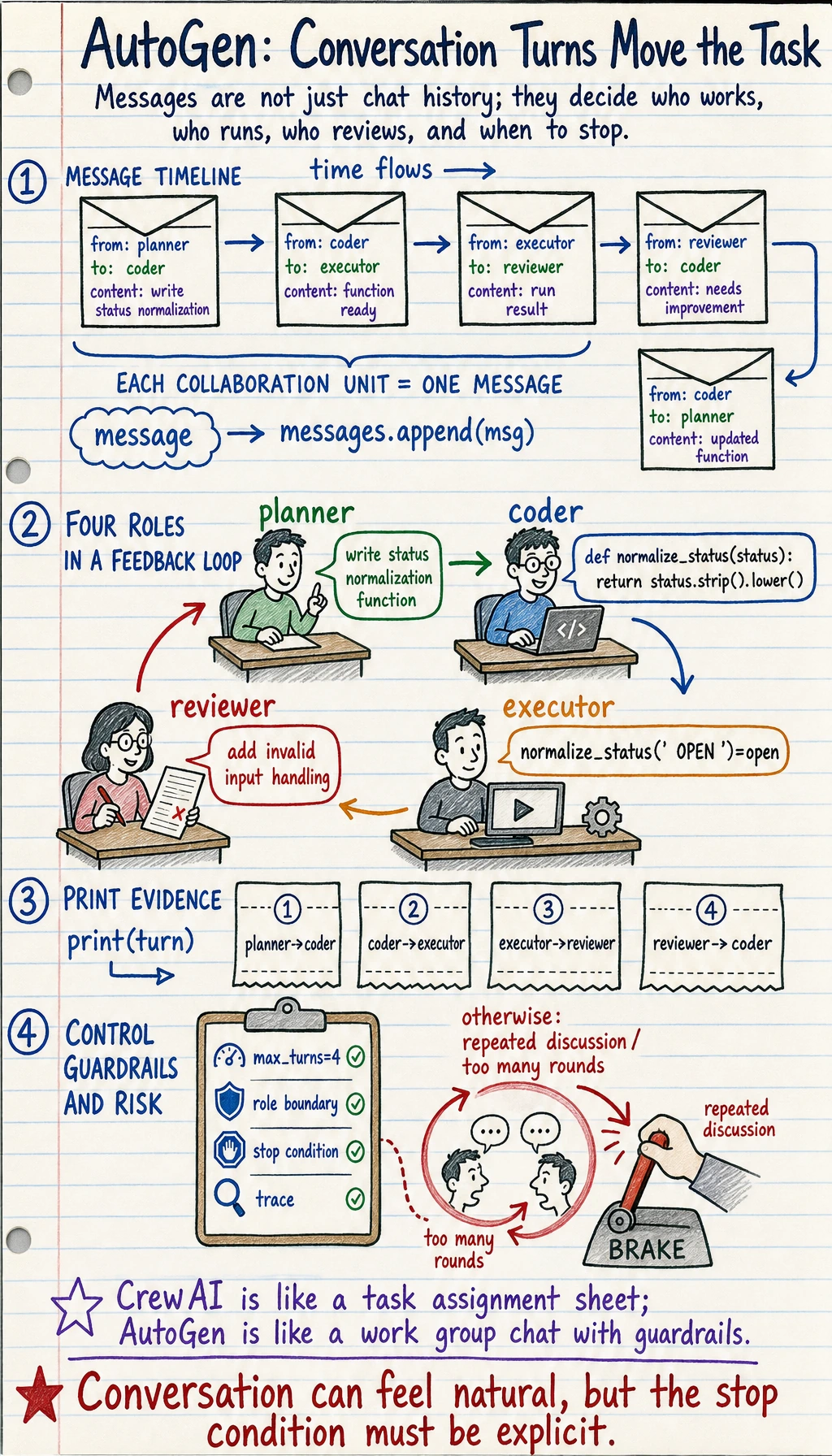
This example already looks very similar to the workflow skeleton in many AutoGen tutorials.
What is the real advantage of AutoGen?
Section titled “What is the real advantage of AutoGen?”It expresses “back-and-forth collaboration among multiple roles” very naturally
Section titled “It expresses “back-and-forth collaboration among multiple roles” very naturally”It is especially good at expressing:
planner <-> workerwriter <-> reviewercoder <-> executor <-> critic
These multi-round feedback relationships.
It is very friendly for prototyping and experimentation
Section titled “It is very friendly for prototyping and experimentation”Because you do not necessarily need to fully draw out the state graph from the beginning. You can first:
- Define several roles
- Let them start talking
- Then observe how the system progresses
This is very valuable during the exploration stage.
But you also need to understand the risks of the AutoGen style
Section titled “But you also need to understand the risks of the AutoGen style”The number of message rounds can easily get out of control
Section titled “The number of message rounds can easily get out of control”Once the system mainly relies on message back-and-forth to move forward, it is easy to end up with:
- Too many rounds
- Repeated discussions
- Continuing to talk even though the task already has enough information
Role boundaries can drift easily
Section titled “Role boundaries can drift easily”If you do not define clear boundaries for each role, then you may see:
- The planner starts writing code
- The reviewer starts doing retrieval
As a result, role responsibilities become increasingly messy.
The stopping condition must be very clear
Section titled “The stopping condition must be very clear”Without a rule for “when to stop,” the system can easily keep running longer and longer.
So one very important engineering principle for AutoGen is:
Conversation can be natural, but the termination condition must be explicit.
What is the difference between it and CrewAI / LangGraph?
Section titled “What is the difference between it and CrewAI / LangGraph?”Difference from CrewAI
Section titled “Difference from CrewAI”CrewAI emphasizes:
- Roles
- Tasks
- Teams
AutoGen emphasizes:
- How messages flow between roles
So a rough but memorable distinction is:
- CrewAI is more like a “team schedule”
- AutoGen is more like “team chat collaboration”
Difference from LangGraph
Section titled “Difference from LangGraph”LangGraph emphasizes:
- Explicit state
- Nodes
- Conditional edges
AutoGen emphasizes:
- Conversation turns
- Round-by-round progress
So AutoGen feels more natural when expressing systems that “move the task forward like a conversation.”
When is it worth considering AutoGen?
Section titled “When is it worth considering AutoGen?”It is especially suitable for:
- Multi-round negotiation tasks
- Code generation + execution + feedback
- Writing + review + revision
- Prototyping and exploratory experiments
It may not be especially suitable for:
- Production systems that require strict state-machine control
- Processes with complex branching that must be tightly controlled
In other words, it is more like:
A framework that is very good at expressing “conversational collaboration.”
A very practical engineering reminder
Section titled “A very practical engineering reminder”If you really want to build an AutoGen-style system in depth, it is best to add these early:
- trace
- maximum number of turns
- role permission boundaries
- failure fallback
Otherwise, the system can easily slide from:
- Looking smart
to:
- Very talkative, but inefficient
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Problem Shape
- workflow graph, retrieval app, role team, or experiment
- Framework Choice
- what abstraction it adds and what control it hides
- Trace
- state, node, tool call, message, or run id
- Failure Check
- framework magic hides state, retries, or permissions
- Decision
- choose framework only after the single-agent loop is clear
Summary
Section titled “Summary”The most important thing in this section is not to memorize the name AutoGen, but to understand:
It is best at expressing systems where multiple roles take turns advancing a task through conversation.
When a task naturally feels like group-chat collaboration, this kind of framework feels very natural. But if you need strong state control, you need to be especially careful about turn count and convergence.
Exercises
Section titled “Exercises”- Design a 3-role message flow for
planner -> coder -> reviewer. - Think about why AutoGen-style tasks are especially prone to “too many rounds of talking.”
- Explain in your own words: what is the core difference between AutoGen and CrewAI?
- If your task requires strong state-machine control, would you still prioritize this conversational abstraction? Why?
Solution approach and explanation
- A basic flow is: planner defines the task and acceptance criteria, coder proposes or edits the implementation, reviewer checks correctness and risk, then the planner decides whether another round is needed.
- AutoGen-style systems can talk too much because conversation itself is the control mechanism. Without stop conditions, role boundaries, and review criteria, agents may keep negotiating instead of finishing.
- AutoGen emphasizes conversational interaction among agents. CrewAI emphasizes role/task organization. They overlap in practice, but their mental models lead you to design the system differently.
- If strong state-machine control is required, conversational abstraction may not be the first choice. Use it only if you can still enforce state, limits, transitions, and traceability clearly.