9.7.7 Practice: Multi-Agent Collaboration System
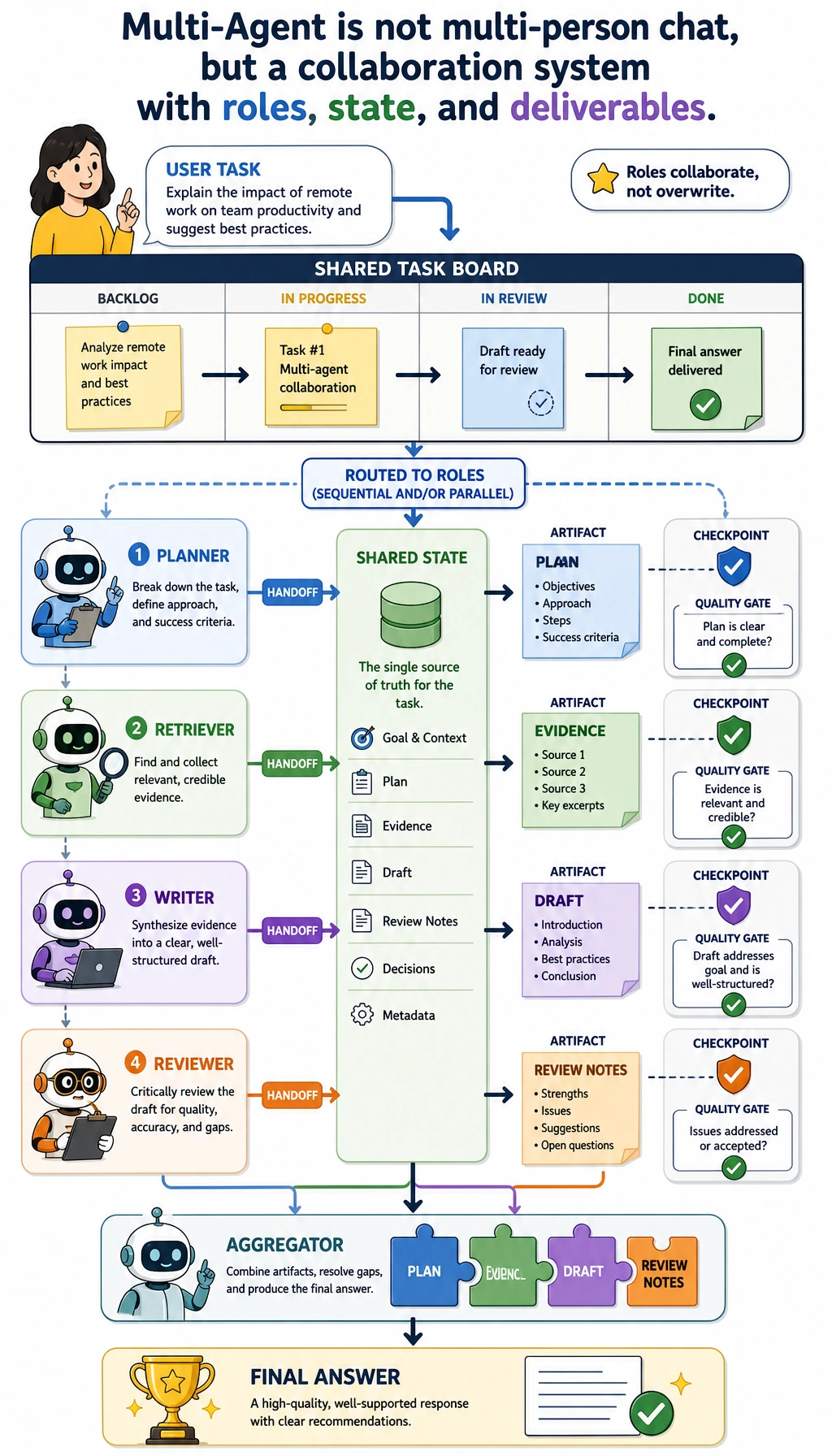
Learning Objectives
Section titled “Learning Objectives”- Build a minimal multi-Agent collaboration loop
- Learn how to let planner, retriever, writer, and reviewer each do their own job
- Understand how task state flows among multiple roles
- Understand what this project truly adds compared with a single-Agent system
First, Define the Project Goal
Section titled “First, Define the Project Goal”We will build a minimal research-style multi-Agent system:
User input:
“Please help me summarize the key conditions of the refund policy.”
Internal system roles:
- Planner: break down the task
- Retriever: find information
- Writer: write the summary
- Reviewer: check the result
This task is a good fit because it can naturally be split into parts, and each role has a very clear responsibility.
Prepare a Knowledge Base
Section titled “Prepare a Knowledge Base”knowledge_base = { "refund policy": "You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.", "certificate policy": "You can receive a completion certificate after finishing all required projects and passing the test.", "learning sequence": "It is recommended to learn Python, data analysis, and machine learning first, then move on to deep learning and large models."}
print(knowledge_base)Expected output:
{'refund policy': 'You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.', 'certificate policy': 'You can receive a completion certificate after finishing all required projects and passing the test.', 'learning sequence': 'It is recommended to learn Python, data analysis, and machine learning first, then move on to deep learning and large models.'}This is the minimal knowledge source that the system will operate on.
Define Four Agents
Section titled “Define Four Agents”Planner
Section titled “Planner”def planner_agent(user_query): if "refund" in user_query: return ["retrieve refund policy", "organize key conditions", "write summary", "review output"] return ["retrieve related materials", "write summary", "review output"]Retriever
Section titled “Retriever”def retriever_agent(task): if "refund policy" in task: return knowledge_base["refund policy"] return "No materials found"Writer
Section titled “Writer”def writer_agent(evidence): return f"Summary: {evidence}"Reviewer
Section titled “Reviewer”def reviewer_agent(draft): if "7 days" in draft and "20%" in draft: return {"approved": True, "comment": "Key information is complete"} return {"approved": False, "comment": "Missing key conditions"}Connect Them Together
Section titled “Connect Them Together”A Minimal Multi-Agent Collaboration Flow
Section titled “A Minimal Multi-Agent Collaboration Flow”Run this in the same Python file or interpreter session after the knowledge base and four Agent functions above.
def multi_agent_system(user_query): state = { "query": user_query, "plan": [], "evidence": None, "draft": None, "review": None }
# 1. Planning state["plan"] = planner_agent(user_query)
# 2. Retrieval state["evidence"] = retriever_agent(state["plan"][0])
# 3. Writing state["draft"] = writer_agent(state["evidence"])
# 4. Review state["review"] = reviewer_agent(state["draft"])
return state
result = multi_agent_system("Please help me summarize the key conditions of the refund policy.")for k, v in result.items(): print(k, "->", v)Expected output:
query -> Please help me summarize the key conditions of the refund policy.plan -> ['retrieve refund policy', 'organize key conditions', 'write summary', 'review output']evidence -> You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.draft -> Summary: You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.review -> {'approved': True, 'comment': 'Key information is complete'}
What Does This Code Already Show?
Section titled “What Does This Code Already Show?”It already shows that:
- Multi-Agent is not just multiple functions
- The key is state transition
- Each role is only responsible for its own part
This is a true minimal multi-Agent system.
Make the System More Like a Real Workflow
Section titled “Make the System More Like a Real Workflow”What If the Reviewer Does Not Approve?
Section titled “What If the Reviewer Does Not Approve?”In a real system, if the review does not pass, the process usually should not end immediately. A more reasonable approach is:
- Send the comment back to the writer
- Revise the output again
A Small Example with Revision
Section titled “A Small Example with Revision”Continue in the same file or session so multi_agent_system and the Agent functions are already defined.
def reviser_agent(draft, review): if review["approved"]: return draft return draft + " Additional note: the refund also requires learning progress to be below 20%."
state = multi_agent_system("Please help me summarize the key conditions of the refund policy.")final_output = reviser_agent(state["draft"], state["review"])
print("draft :", state["draft"])print("review:", state["review"])print("final :", final_output)Expected output:
draft : Summary: You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.review: {'approved': True, 'comment': 'Key information is complete'}final : Summary: You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.This step is very important because it shows:
The value of a multi-Agent system is not only division of labor, but also the ability for roles to form an iterative closed loop.
Add Clearer Task Logs
Section titled “Add Clearer Task Logs”Why Must a Project Have Traces?
Section titled “Why Must a Project Have Traces?”If the system gives the wrong answer, at least you need to know:
- How the planner broke down the task
- What the retriever found
- What the writer wrote
- Why the reviewer did not catch the problem
A Minimal Trace Version
Section titled “A Minimal Trace Version”Continue in the same file or session so the four Agent functions are already defined.
def traced_multi_agent_system(user_query): trace = []
plan = planner_agent(user_query) trace.append({"agent": "planner", "output": plan})
evidence = retriever_agent(plan[0]) trace.append({"agent": "retriever", "output": evidence})
draft = writer_agent(evidence) trace.append({"agent": "writer", "output": draft})
review = reviewer_agent(draft) trace.append({"agent": "reviewer", "output": review})
return trace
for step in traced_multi_agent_system("Please help me summarize the key conditions of the refund policy."): print(step)Expected output:
{'agent': 'planner', 'output': ['retrieve refund policy', 'organize key conditions', 'write summary', 'review output']}{'agent': 'retriever', 'output': 'You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.'}{'agent': 'writer', 'output': 'Summary: You can apply for a refund within 7 days after purchase, provided your learning progress is below 20%.'}{'agent': 'reviewer', 'output': {'approved': True, 'comment': 'Key information is complete'}}This trace is the important foundation for debugging and evaluating the system later.
Why Is This System More Worth Learning Than a Single Agent?
Section titled “Why Is This System More Worth Learning Than a Single Agent?”Because It Breaks the Problem Apart
Section titled “Because It Breaks the Problem Apart”A single Agent often does everything in one go:
- Understand the task
- Retrieve information
- Summarize
- Self-check
A multi-Agent system breaks these actions apart, which makes it easier for you to:
- Observe each layer
- Replace one layer
- Find out where an error happened
But It Is Also More Expensive and More Complex
Section titled “But It Is Also More Expensive and More Complex”So the real engineering judgment is not:
Multi-Agent is always more advanced
Instead, it is:
Is this task worth paying extra complexity for better decomposability and controllability?
How Can This Project Be Extended?
Section titled “How Can This Project Be Extended?”You can keep adding:
- A more realistic retriever
- Multi-task routing
- Asynchronous communication
- Conflict resolution
- Retry on failure
If you keep expanding it, it will gradually become closer to a real multi-Agent product system.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Roles
- owner, worker, reviewer, or specialist responsibilities
- Message Contract
- artifact, request, response, and handoff state
- Coordination
- routing, task split, conflict resolution, and final owner
- Failure Check
- duplicated work, lost context, no accountable owner, or message loop
- Eval Action
- compare multi-agent result against single-agent baseline
Common Mistakes Beginners Make
Section titled “Common Mistakes Beginners Make”Writing All Roles in Almost the Same Way
Section titled “Writing All Roles in Almost the Same Way”Then the result is just “multiple Agents with different names for the same thing.”
No Shared State or Trace
Section titled “No Shared State or Trace”Once something goes wrong, it becomes very hard to debug.
The Project Looks Busy, but Each Role Does Not Actually Have a Real Division of Labor
Section titled “The Project Looks Busy, but Each Role Does Not Actually Have a Real Division of Labor”This is one of the most common problems in many multi-Agent demos.
Summary
Section titled “Summary”The most important thing in this section is not to write four functions, but to understand:
The core of a multi-Agent project is to let each role take different responsibilities around state transitions, and ultimately converge into an explainable and iterative workflow.
That is where multi-Agent truly becomes more valuable than a single Agent.
Exercises
Section titled “Exercises”- Add a
fact_checker_agentto this system to specifically verify numeric conditions. - Make
planner_agentproduce different plans for “certificate policy” as well. - Think about this: if the reviewer keeps rejecting the output, how should the system limit the number of revision rounds?
- Explain in your own words: why is the real importance of a multi-Agent project “state transition” rather than “number of roles”?
Project reference and review notes
fact_checker_agentshould receive the draft plus extracted numeric claims, compare each claim against source evidence, and return pass/fail status with the exact claim that needs revision.- For “certificate policy,” the planner should choose a plan that includes policy retrieval, eligibility extraction, conflict checking, draft answer, and reviewer verification rather than reusing a generic plan blindly.
- Revision rounds should be capped, for example two review-revise cycles. If it still fails, the system should stop, report unresolved issues, and ask for human input instead of looping indefinitely.
- State transition matters because the project succeeds only when each stage changes the system state in a controlled way: plan created, evidence collected, draft written, facts checked, review passed, final delivered.