8.5.4 Project: Intelligent Q&A Assistant
Learning objectives
Section titled “Learning objectives”- Understand the difference between an intelligent Q&A assistant and a regular Q&A function
- Learn how to put retrieval, state, and tool calling into one workflow
- Learn how to define the most important evaluation dimensions for this project
- Learn how to turn it into a portfolio project that feels more like a product
What does an intelligent Q&A assistant have that a regular Q&A app does not?
Section titled “What does an intelligent Q&A assistant have that a regular Q&A app does not?”It is not just “you ask once, I answer once”
Section titled “It is not just “you ask once, I answer once””The real feeling of an assistant usually comes from:
- It remembers the previous turn
- It asks follow-up questions when needed
- It knows when to check the knowledge base and when to use tools
A clear practice task
Section titled “A clear practice task”For example:
Build a course platform assistant that can answer questions about refunds, certificates, and learning progress.
This is a very good task because it naturally includes:
- A knowledge base
- User state
- Multi-turn context
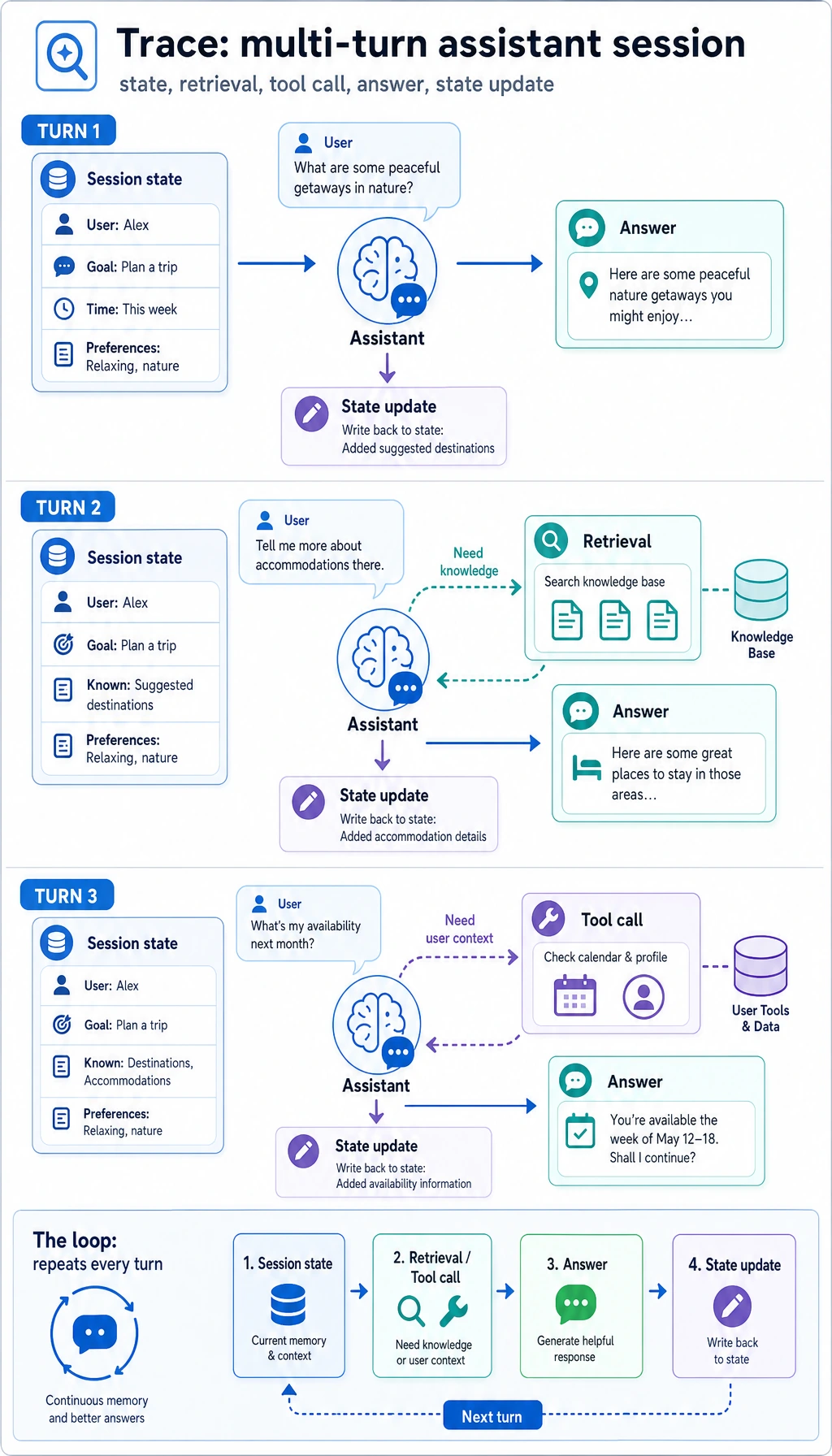
What does the minimum product-level loop look like?
Section titled “What does the minimum product-level loop look like?”- Maintain conversation history
- Identify the current topic
- Retrieve relevant knowledge
- Call tools to check user status when needed
- Generate a response with context awareness
As long as you make these 5 steps clear, the project already feels very product-like.
A loop diagram that looks more like a real product
Section titled “A loop diagram that looks more like a real product”flowchart LR A["User message"] --> B["Topic detection"] B --> C["Knowledge retrieval"] C --> D["Need to call a tool?"] D --> E["Generate response"] E --> F["Update session state"] F --> AThis diagram is important because it reminds you that:
- The assistant does not answer just once
- It keeps updating state and actions across turns
Recommended build order
Section titled “Recommended build order”For beginners, a safer sequence is usually:
- Build single-turn knowledge Q&A first
- Add conversation state next
- Add tool calling next
- Finally add multi-turn evaluation and failure case demos
This way, you can clearly see which layer creates the “assistant feel.”
A simpler analogy for beginners
Section titled “A simpler analogy for beginners”You can think of an intelligent Q&A assistant as:
- A customer service assistant that can look up documents, ask follow-up questions, and check system status
The biggest difference from an FAQ page is not:
- Longer answers
But rather:
- It continues collaborating based on context
Start by running a more complete minimal assistant
Section titled “Start by running a more complete minimal assistant”The example below will:
- Maintain a session
- Retrieve from a knowledge base
- Call a user progress tool for refund questions
- Generate a final answer based on context
kb = [ {"key": "refund", "text": "Refund policy: You can get a refund within 7 days of purchase if your learning progress is below 20%."}, {"key": "certificate", "text": "Certificate policy: You can receive a certificate after completing all projects and passing the test."},]
def retrieve(query): if "refund" in query: return kb[0], 0.92 if "certificate" in query: return kb[1], 0.88 return None, 0.0
def get_user_progress(user_id): progress_db = { 1: 0.15, 2: 0.30, } return progress_db.get(user_id, None)
def new_session(): return { "history": [], "topic": None, "user_id": None, "last_retrieved_doc": None, "last_tool_call": None, }
def assistant_reply(session, user_message, user_id=None): if user_id is not None: session["user_id"] = user_id
session["history"].append({"role": "user", "content": user_message}) message = user_message.lower()
if "still get a refund" in message and session["topic"] == "refund" and session["user_id"] is not None: session["last_tool_call"] = {"name": "get_user_progress", "user_id": session["user_id"]} progress = get_user_progress(session["user_id"]) if progress is None: answer = "I can't find your learning progress right now. Please confirm your account status." else: answer = ( f"The system shows your learning progress is about {int(progress * 100)}%." + (" You are still eligible for a refund." if progress < 0.2 else " You do not currently meet the refund conditions.") )
elif "refund" in message: session["topic"] = "refund" doc, score = retrieve("refund") session["last_retrieved_doc"] = doc session["last_tool_call"] = None answer = f"{doc['text']} If you tell me your learning progress, I can help you check whether you qualify."
elif "certificate" in message: session["topic"] = "certificate" doc, score = retrieve("certificate") session["last_retrieved_doc"] = doc session["last_tool_call"] = None answer = doc["text"]
else: session["last_tool_call"] = None answer = "I can currently help with refund, certificate, and learning progress questions."
session["history"].append({"role": "assistant", "content": answer}) return answer
session = new_session()print(assistant_reply(session, "What is the refund policy?", user_id=2))print(assistant_reply(session, "Can I still get a refund?"))print("last_tool_call:", session["last_tool_call"])print("topic:", session["topic"])Expected output:
Refund policy: You can get a refund within 7 days of purchase if your learning progress is below 20%. If you tell me your learning progress, I can help you check whether you qualify.The system shows your learning progress is about 30%. You do not currently meet the refund conditions.last_tool_call: {'name': 'get_user_progress', 'user_id': 2}topic: refund
What is the most important value of this example?
Section titled “What is the most important value of this example?”It is not just doing “Q&A,” but showing:
- Conversation state
- The division of labor between retrieval and tools
- How multi-turn context drives the answer
This already feels much more like a real assistant product than single-turn FAQ matching.
Why is session more worth looking at than the answer itself?
Section titled “Why is session more worth looking at than the answer itself?”Because session is the key to keeping the system collaborative over time.
Without state, it is very hard to create an assistant-like experience.
Another tiny “state snapshot” example
Section titled “Another tiny “state snapshot” example”snapshot = { "topic": session["topic"], "user_id": session["user_id"], "last_retrieved_doc": session["last_retrieved_doc"], "last_tool_call": session["last_tool_call"],}
print(snapshot)Expected output:
{'topic': 'refund', 'user_id': 2, 'last_retrieved_doc': {'key': 'refund', 'text': 'Refund policy: You can get a refund within 7 days of purchase if your learning progress is below 20%.'}, 'last_tool_call': {'name': 'get_user_progress', 'user_id': 2}}This example is great for beginners because it helps you first see:
- What an assistant system really needs to maintain is not the full raw conversation text
- It is several key pieces of state
How should you evaluate this project?
Section titled “How should you evaluate this project?”Single-turn accuracy is not enough
Section titled “Single-turn accuracy is not enough”You should also check at least:
- Whether the multi-turn context stays consistent
- Whether tool calling is reasonable
- Whether the system starts making things up when information is missing
A minimal evaluation case table
Section titled “A minimal evaluation case table”eval_cases = [ { "turns": ["What is the refund policy?", "Can I still get a refund?"], "user_id": 1, "expected_keywords": ["15%", "eligible for a refund"], }, { "turns": ["How do I get a certificate?"], "user_id": None, "expected_keywords": ["passing the test", "certificate"], },]
for case in eval_cases: session = new_session() last_answer = "" for turn in case["turns"]: last_answer = assistant_reply(session, turn, case["user_id"]) print({ "turns": case["turns"], "last_answer": last_answer, "expected_hit": all(keyword in last_answer for keyword in case["expected_keywords"]), })Expected output:
{'turns': ['What is the refund policy?', 'Can I still get a refund?'], 'last_answer': 'The system shows your learning progress is about 15%. You are still eligible for a refund.', 'expected_hit': True}{'turns': ['How do I get a certificate?'], 'last_answer': 'Certificate policy: You can receive a certificate after completing all projects and passing the test.', 'expected_hit': True}Why is multi-turn evaluation especially important?
Section titled “Why is multi-turn evaluation especially important?”Because the highlight of this kind of project is not single-turn performance. The place where it most easily fails is:
- Forgetting the context starting from the second turn
An evaluation table that beginners can remember first
Section titled “An evaluation table that beginners can remember first”| Dimension | What you are really checking |
|---|---|
| Is the single-turn answer correct? | Knowledge answering ability |
| Does the multi-turn context stay on track? | State management ability |
| Is tool calling reasonable? | System decision-making ability |
| Does it ask follow-up questions when information is missing? | Assistant collaboration ability |
This table is especially useful for beginners because it breaks “assistant feel” into several concrete, checkable parts.
How do you turn this into a portfolio-quality page?
Section titled “How do you turn this into a portfolio-quality page?”Show one complete dialogue trace
Section titled “Show one complete dialogue trace”For example:
- User question
- Retrieved document
- Whether a tool was called
- Final answer
Failure cases that are especially worth showing
Section titled “Failure cases that are especially worth showing”For example:
- When the user does not provide enough information, does the system make random guesses?
- When the tool cannot find the status, does the system honestly stop and wait?
A very good bonus point
Section titled “A very good bonus point”Turn these two chains into flowcharts and show them:
- Knowledge answering
- User state answering
The easiest mistakes to make
Section titled “The easiest mistakes to make”Only building single-turn Q&A
Section titled “Only building single-turn Q&A”This makes it hard to show the “assistant feel.”
No tool boundary
Section titled “No tool boundary”If every question depends on model guessing, the system will become less and less stable.
Not checking context consistency
Section titled “Not checking context consistency”Many project problems happen exactly on the second and third turns.
If you turn this into a portfolio, what should you emphasize most?
Section titled “If you turn this into a portfolio, what should you emphasize most?”What is most worth emphasizing is usually not:
- “It can chat”
But instead:
- One complete multi-turn dialogue trace
- Which turn triggered retrieval
- Which turn triggered tool calling
- How the session state changed
- When the system chose to ask a follow-up question or stop
That way, others can more easily feel that:
- You built a continuous collaboration system
- Not just a multi-turn chat demo
What to include when delivering the project
Section titled “What to include when delivering the project”- A system flowchart
- One complete multi-turn dialogue trace
- A set of tool-calling success/failure cases
- A set of examples showing when the system knows to ask follow-up questions or stop
- A short explanation of your future extension path
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Project Goal
- user task and business boundary
- Baseline
- simplest prompt/RAG/app version first
- Evaluation
- fixed cases, retrieval evidence, answer quality, and citation check
- Failure Log
- at least one failed case with likely cause
- Deliverable
- README, run command, screenshots/logs, next step
Summary
Section titled “Summary”The most important idea in this section is to build a product-level judgment:
What makes an intelligent Q&A assistant feel like a real project is not whether it sounds human, but whether it can organize retrieval, state, and tool calling into a continuous multi-turn collaboration flow.
As long as you explain that flow clearly, it will feel very much like a real AI product that can keep growing.
Suggested version roadmap
Section titled “Suggested version roadmap”| Version | Goal | Delivery focus |
|---|---|---|
| Basic version | Get the minimum loop working | Can accept input, process it, and output results, while keeping a few examples |
| Standard version | Become a presentable project | Add configuration, logs, error handling, README, and screenshots |
| Challenge version | Approach portfolio quality | Add evaluation, comparison experiments, failure sample analysis, and next-step planning |
It is recommended to finish the basic version first. Do not try to make it large and complete from the start. Every time you move up a version, write in the README what new capability was added, how it was verified, and what problems remain.
Exercises
Section titled “Exercises”- Add a
learning pathtopic to the example so the assistant can handle three kinds of questions. - Think about why an intelligent assistant needs state management more than an FAQ does.
- If the tool cannot find the user’s status, what is the safest response?
- If you turn this project into a portfolio piece, which conversation is most worth showing?
Project reference and review notes
- The
learning pathtopic should add intent detection, required slots, a tool/context source, and a response template. - An assistant must track user goal, missing information, previous answers, tool results, and next action. FAQ is mostly stateless lookup.
- The safest response is to say the status cannot be found, ask for the needed information or suggest a secure next step, and avoid inventing status.
- The best portfolio conversation shows multi-turn clarification, state updates, tool/RAG evidence, and graceful failure or permission boundaries.