5.5.3 Feature Preprocessing
Learning Objectives
Section titled “Learning Objectives”- Understand what problems missing values, outliers, scaling, and encoding each solve
- Be able to judge whether different models need standardization
- Know the applicable boundaries of One-Hot, Ordinal Encoding, and Target Encoding
- Build basic awareness of how to avoid data leakage
First, Build a Map
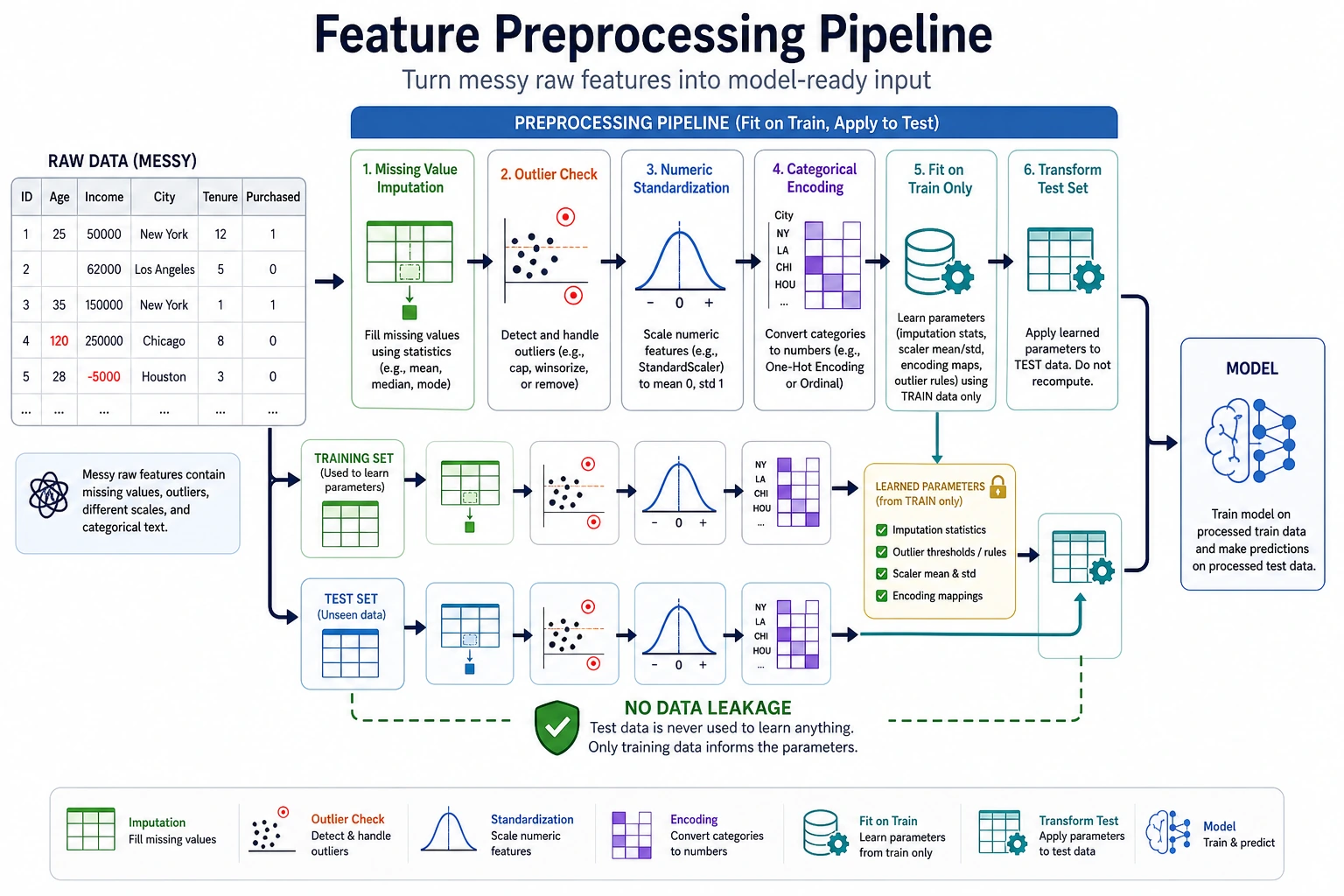
Section titled “First, Build a Map”flowchart LR A[Raw features] --> B[Missing value handling] B --> C[Outlier handling] C --> D[Numeric scaling] D --> E[Categorical encoding] E --> F[Into the model]This diagram shows a common order, not a fixed workflow. For example, tree models usually do not rely heavily on standardization, while linear models, KNN, SVM, and neural networks usually need scaling more.
Reusable Setup for the Examples Below
Section titled “Reusable Setup for the Examples Below”To make the code blocks below runnable on their own, we will use one tiny mixed-type sample dataset. It includes missing values, numeric columns, and categorical columns.
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_split
df = pd.DataFrame({ "age": [25, np.nan, 39, 51, 45, np.nan, 33, 60], "income": [50000, 62000, np.nan, 120000, 85000, 76000, 54000, 200000], "amount": [80, 95, 120, 10000, 110, 130, 70, 150], "city": ["A", "B", "A", "C", None, "B", "D", "A"], "gender": ["F", "M", "F", "M", "F", None, "M", "F"], "target": [0, 1, 0, 1, 0, 1, 0, 1],})
X = df[["age", "income", "amount", "city", "gender"]]y = df["target"]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)Missing Value Handling
Section titled “Missing Value Handling”Missing values are sometimes dirty data, and sometimes a signal in themselves. For example, “the user did not fill in company” may mean an ordinary individual user; “a health metric is missing” may just be a system entry issue. Before handling missing values, ask first: why is it missing?
import pandas as pd
missing_rate = df.isna().mean().sort_values(ascending=False)print(missing_rate)Common strategies include dropping columns with too many missing values, filling numeric features with the mean or median, filling categorical features with the mode or “unknown,” and adding a flag column indicating whether a value is missing. Do not start by calling dropna() on everything, or you may easily lose a large number of samples.
Outlier Handling
Section titled “Outlier Handling”Outliers are not always errors. Financial fraud, device failures, and extreme spending behavior may be exactly the kinds of samples the model cares about most. When handling outliers, you need to combine them with business context.
q1 = df["amount"].quantile(0.25)q3 = df["amount"].quantile(0.75)iqr = q3 - q1lower = q1 - 1.5 * iqrupper = q3 + 1.5 * iqroutliers = df[(df["amount"] < lower) | (df["amount"] > upper)]print(outliers.head())If an outlier comes from a data entry mistake, you can correct or remove it. If an outlier represents truly rare behavior, consider keeping it and using a robust model or binning to handle it.
Numeric Scaling: When Standardization Is Needed
Section titled “Numeric Scaling: When Standardization Is Needed”Standardization solves the problem of large differences in feature scale. For example, age may be in the tens, while income may be in the tens of thousands. If a model relies on distance or gradients, scale differences can affect training.
| Model type | Usually needs scaling? | Reason |
|---|---|---|
| Linear Regression / Logistic Regression | Recommended | Gradients and regularization are affected by scale |
| KNN / SVM | Usually yes | Distance calculations are affected by scale |
| Neural Networks | Usually yes | Helps stabilize training |
| Decision Trees / Random Forest / GBDT | Usually no | They split by thresholds and are not sensitive to monotonic scaling |
from sklearn.preprocessing import StandardScaler
numeric_cols = ["age", "income", "amount"]scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train[numeric_cols])X_test_scaled = scaler.transform(X_test[numeric_cols])print(X_train_scaled[:2])Note that you should only fit on the training set, then transform the test set. If you fit the scaler on all the data, you leak test-set information into the training process.
Categorical Encoding
Section titled “Categorical Encoding”Categorical features cannot be fed directly into most traditional models and need to be encoded. The most common method is One-Hot Encoding, which is suitable for unordered categories such as city, color, and occupation.
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(handle_unknown="ignore")X_train_cat = encoder.fit_transform(X_train[["city"]])X_test_cat = encoder.transform(X_test[["city"]])print(X_train_cat.shape, X_test_cat.shape)Ordered categories can be encoded with Ordinal Encoding, such as education level or clothing size categories like small, medium, and large. But do not casually map unordered categories to 0, 1, 2, or the model may think there is an order relationship between them.
Target Encoding is useful for high-cardinality categories, but it can easily cause leakage. For example, when encoding city using the “average conversion rate of each city,” you must calculate it only based on the training fold, not directly from the full labels.
Use a Pipeline to Prevent Leakage
Section titled “Use a Pipeline to Prevent Leakage”The safest way is to put preprocessing and the model into the same Pipeline, so that during cross-validation each fold fits the preprocessors only on the training portion.
from sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import OneHotEncoder, StandardScalerfrom sklearn.linear_model import LogisticRegression
num_features = ["age", "income", "amount"]cat_features = ["city", "gender"]
preprocess = ColumnTransformer([ ("num", Pipeline([ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()), ]), num_features), ("cat", Pipeline([ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore")), ]), cat_features),])
model = Pipeline([ ("preprocess", preprocess), ("clf", LogisticRegression(max_iter=1000)),])
model.fit(X_train, y_train)print(model.score(X_test, y_test))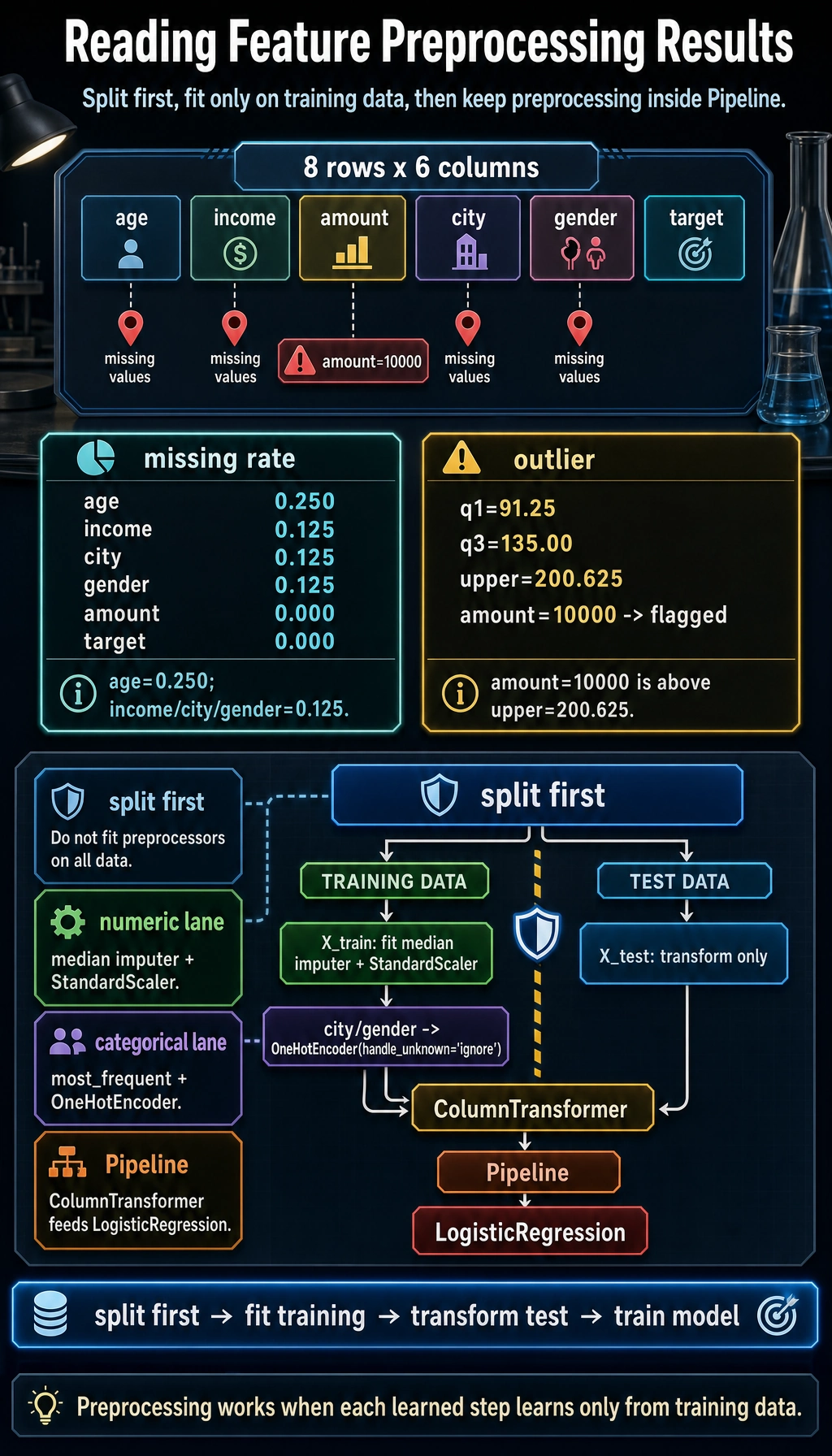
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Feature State
- raw columns, types, missing values, scale, and target relationship
- Transformation
- preprocessing, construction, selection, or pipeline step
- Output
- transformed feature table, pipeline object, score change, or selected features
- Failure Check
- leakage, inconsistent train/test transform, high-cardinality trap, or meaningless feature
- Expected Output
- feature pipeline evidence with before/after and metric impact
Common Mistakes
Section titled “Common Mistakes”The first mistake is standardizing all models. Tree models usually do not need it, and doing it may not bring any benefit. The second mistake is preprocessing before splitting the training and test sets, which causes data leakage. The third mistake is randomly mapping categories to numbers, causing the model to learn a nonexistent order relationship. The fourth mistake is over-cleaning outliers and deleting truly valuable extreme samples.
Exercises
Section titled “Exercises”- Use the Titanic dataset to calculate the missing rate for each column and design a handling plan for each one.
- Train LogisticRegression and RandomForest on the same dataset separately, and compare the impact of standardization on each.
- Explain why the scaler should
fiton the training set rather than on the full dataset. - Find a high-cardinality categorical feature and think about the risks of One-Hot and Target Encoding respectively.
Solution approach and explanation
- Low missing rates can often use median/mode imputation; high missing rates may need a missing indicator, domain review, or removal. The plan should justify each column separately.
- LogisticRegression is usually sensitive to scale because coefficients and optimization depend on numeric magnitude. RandomForest is much less sensitive because splits depend on ordering.
- The scaler must learn mean and variance from training data only. Fitting on the full dataset leaks test-set distribution information into training.
- One-Hot can create too many sparse columns for high-cardinality features. Target Encoding can leak label information unless it is done inside cross-validation or with careful smoothing.
Passing Criteria
Section titled “Passing Criteria”After finishing this section, you should be able to write a preprocessing plan for tabular data, explain the reason for each preprocessing step, use a Pipeline to avoid data leakage, and judge whether a model really needs standardization or categorical encoding.